mysql去重复关键字distinct的用法
distinct的去重复的提前是表中所有列的数据完成相同时,才能把相同的数据只保留一条,并不是 distinct 列名,除去某一列相同的数据,并且 distinct要放在第一个列前面。案例如下:一个学生表如下:第一条记录跟第四条记录完成相同 第一条的性名列跟第二条相同。
现在除掉相同的姓名的数据,只保留一条。代码如下:
SELECT id AS "学号", IFNULL (age,0) AS "年龄", DISTINCT s.`name` AS "姓名", brithday AS "生日", s.`intsert_time` AS "插入时间" FROM stu1 s ;结果报如下错:
既然distinct 只能放在第一列前,哪我把姓名列移动第一列看看代码如下:
SELECT DISTINCT s.`name` AS "姓名", id AS "学号", IFNULL (age,0) AS "年龄", brithday AS "生日", s.`intsert_time` AS "插入时间" FROM stu1 s ;
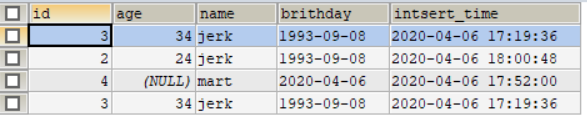
运行结果却是去掉第四条数据,但是没有去掉第二条数据。说明distinct去重复要求某几条数据完成一样才会去重复。运行结果如下图:

如果想姓名列相同,只保留一条记录,那么可以考虑group by 分组,现在用group by 看看效果,代码如下:
SELECT DISTINCT s.`name` AS "姓名", id AS "学号", IFNULL (age,0) AS "年龄", brithday AS "生日", s.`intsert_time` AS "插入时间" FROM stu1 s GROUP BY s.`name`;
运行结果只保留第一条记录,第2,4条数据都去掉了。

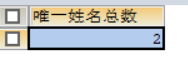
如果我们只需要计算某个字段去重复后的总记录数的话可以用以下代码:
SELECT COUNT(DISTINCT s.name) AS "唯一姓名总数" FROM stu1 s; 结果如下:
总结一下:如果我们需要去掉完全重复的数据可以用distinct放在第一列数据前面,如果我们只需要按照某列相同去掉重复的数据,可以用group by 进行分组。如果我们只需要计算某一个字段去重复后的总记录数可以 用 count(distinct 列名)聚合函数的方式获取。
mysql去重复关键字distinct的用法的更多相关文章
- MYSQL去重复并计算总数的sql语句
SELECT count(distinct uid) FROM `two_users`
- oracle中去重复记录 不用distinct
用distinct关键字只能过滤查询字段中所有记录相同的(记录集相同),而如果要指定一个字段却没有效果,另外distinct关键字会排序,效率很低 . select distinct name fro ...
- mysql数据库去重复
参考:http://www.cnblogs.com/duanjie/archive/2011/08/13/2136862.html 说到去重复,感觉逻辑很简单.但动手写起来却并不是那么容易.面试的时候 ...
- distinct 去重复查询——两个表join 连接,去掉重复的数据
------distinct 去重复查询 select * from accounts acc join (select distinct accid from roles) r on r.acci ...
- C# List<T>中Select List Distinct()去重复
List<ModelJD> data = myDalJD.GetAllDataList(); List<string> list= new List<string> ...
- SQL server 存储过程 C#调用Windows CMD命令并返回输出结果 Mysql删除重复数据保留最小的id C# 取字符串中间文本 取字符串左边 取字符串右边 C# JSON格式数据高级用法
create proc insertLog@Title nvarchar(50),@Contents nvarchar(max),@UserId int,@CreateTime datetimeasi ...
- Mysql中EXISTS关键字用法、总结
在做教务系统的时候,一个学生(alumni_info)有多个教育经历(alumni_education),使用的数据库是mysql,之前使用左链接查询的,发现数据量才只有几万条时,查询就很慢了,早上想 ...
- 【知识库】-数据库_MySQL之高级数据查询:去重复、组合查询、连接查询、虚拟表
简书作者:seay 文章出处: 关系数据库SQL之高级数据查询:去重复.组合查询.连接查询.虚拟表 回顾:[知识库]-数据库_MySQL之基本数据查询:子查询.分组查询.模糊查询 Learn [已经过 ...
- mysql 中合并查询结果union用法 or、in与union all 的查询效率
mysql 中合并查询结果union用法 or.in与union all 的查询效率 (2016-05-09 11:18:23) 转载▼ 标签: mysql union or in 分类: mysql ...
随机推荐
- <学习笔记: Django之初见>
Django 1. web框架介绍 具体介绍Django之前,必须先介绍WEB框架等概念. web框架: 别人已经设定好的一个web网站模板,你学习它的规则,然后“填空”或“修改”成你自己需要的样子. ...
- 02_Java语法
1.注释 2.关键字 3.标识符 4.常量 5.变量 6.数据类型 7.数据类型转换 8.表达式 9.运算符 9.1算数运算符 9.2赋值运算符 9.3比较运算符 9.4逻辑运算符 9.5三元运算符 ...
- 初识CoAP协议
前言 本文介绍什么是CoAP,以及如何在物联网设备上使用它.CoAP是一种物联网协议,具有一些专门为受约束的设备而设计的有趣功能.还有其他一些可用于构建物联网解决方案的IoT协议,例如MQTT等. 物 ...
- java线程池原理解析
五一假期大雄看了一本<java并发编程艺术>,了解了线程池的基本工作流程,竟然发现线程池工作原理和互联网公司运作模式十分相似. 线程池处理流程 原理解析 互联网公司与线程池的关系 这里用一 ...
- Vue实现靠边悬浮球(PC端)
我想把退出登录的按钮做成一个悬浮球的样子,带动画的那种. 实现是这个样子: 手边没有球形图.随便找一个,功能这里演示的为单机悬浮球注销登录 嗯,具体代码: <div :class="[ ...
- spring学习笔记(三)我对AOP理解
首先我们要知道AOP是什么?AOP全称Aspect OrientedProgramming,即面向切面编程.在这里我不想去说什么是切面,什么是切点,什么是通知等等,相关博客很多,如果大家想知道可以自己 ...
- struts2初始化探索(一)
上篇文章已经介绍了struts2的简单使用,现在开始源码的学习. 本篇主要介绍struts2的初始化.对应的源码为StrutsPrepareAndExecuteFilter中的init方法. 先贴源码 ...
- LeetCode 刷题1---两数之和
/** 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标. 你可以假设每种输入只会对应一个答案.但是,你不能重复利用这个数组中 ...
- 折腾了好久的vscode配置c/c++语言环境(Windows环境下)
最近有c语言相关的作业,但是突然再次拿起大一的时候那些c语言编辑器的时候,总觉得不智能,于是下了一个vscode,准备配一个c语言的环境 步骤如下: 1.vs官网下载好vscode,安装好以后再下载一 ...
- Coursera课程笔记----计算导论与C语言基础----Week 4
感性认识计算机程序(Week 4) 引入 编程序 = 给计算机设计好运行步骤 程序 = 人们用来告诉计算机应该做什么的东西 问题➡️该告诉计算机什么?用什么形式告诉? 如果要创造一门"程序设 ...