Python爬虫系列(五):分析HTML结构
今晚,被烦死了。9点多才下班,就想回来看书学习,结果被唠叨唠叨个小时,我不断喊不要和我聊天了,还反复说。我只想安安静静看看书,学习学习,全世界都不要打扰我
接着上一个讨论,我们今晚要分析HTML结构了
1.获取元素
html_doc = """
<html>
<head>
<title>The Dormouse's story
</title>
</head>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "lxml")
# 直接访问head元素
print(soup.head)
# 多个a元素只会返回第一个
print(soup.a)
# 通过层级获取 注意:上面没有body,soup会自动补全
print(soup.body.p)
# 获取所有a,返回a的数组
print(soup.find_all('a'))
2.获取内容和子元素
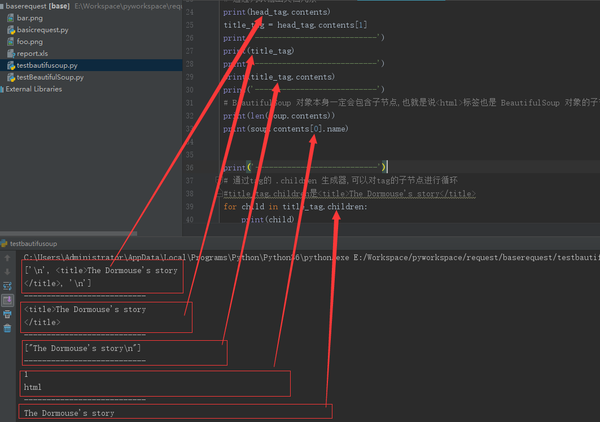
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "lxml")
head_tag = soup.head
# 通过列表输出文档元素
print(head_tag.contents)
title_tag = head_tag.contents[1]
print('---------------------------')
print(title_tag)
print('---------------------------')
print(title_tag.contents)
print('---------------------------')
# BeautifulSoup 对象本身一定会包含子节点,也就是说<html>标签也是 BeautifulSoup 对象的子节点:
print(len(soup.contents))
print(soup.contents[0].name)
print('---------------------------')
# 通过tag的 .children 生成器,可以对tag的子节点进行循环
#title_tag.children是<title>The Dormouse's story</title>
for child in title_tag.children:
print(child)
# 字符串没有 .contents 属性,因为字符串没有子节点:
print('---------------------------')
text = title_tag.contents[0]
print(text.contents) #直接报错 :AttributeError: 'NavigableString' object has no attribute 'contents'
3.跨级获取子节点
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "lxml")
head_tag = soup.head
# 递归获取所有子节点
for child in head_tag.descendants:
print('-----------------------')
print(child)
# 直接子节点
print(len(list(soup.children)))
# 跨级子节点:包括换行符 都算成了子节点。在使用的过程中,一定要注意判空
print(len(list(soup.descendants)))
4.string字符串
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "lxml")
head_tag = soup.head
# title_tag.string是title标签的子节点。即便是纯粹的string 这个就是 NavigableString
# print(title_tag.string)
# 如果一个tag仅有一个子节点,那么这个tag也可以使用 .string 方法,输出结果与当前唯一子节点的 .string 结果相同:
print(head_tag.contents)
# 如果tag包含了多个子节点,tag就无法确定 .string 方法应该调用哪个子节点的内容, .string 的输出结果是 None :
print(soup.html.string)
5.遍历字符串和去除空白字符
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "lxml")
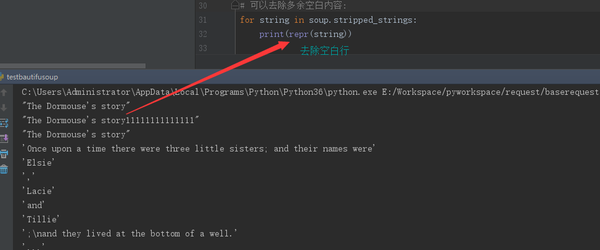
# 如果tag中包含多个字符串 [2] ,可以使用 .strings 来循环获取:
# for string in soup.strings:
# print(repr(string))
# 输出的字符串中可能包含了很多空格或空行, 使用.stripped_strings
# 可以去除多余空白内容:
for string in soup.stripped_strings:
print(repr(string))

去除空白字符
6.父节点
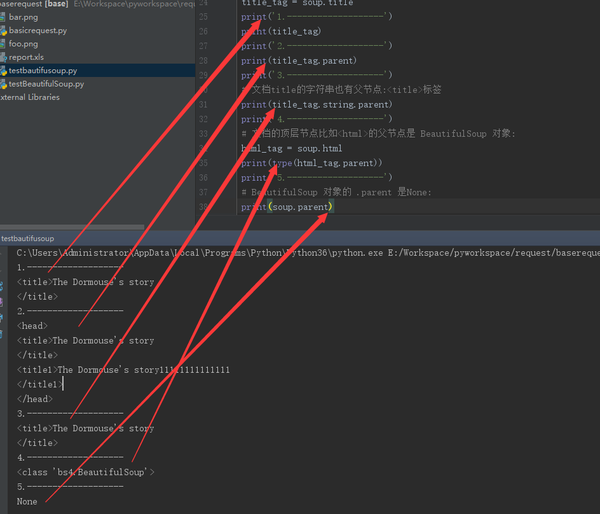
每个节点都有自己的父节点。除了第一个
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "lxml")
title_tag = soup.title
print('1.-------------------')
print(title_tag)
print('2.-------------------')
print(title_tag.parent)
print('3.-------------------')
# 文档title的字符串也有父节点:<title>标签
print(title_tag.string.parent)
print('4.-------------------')
# 文档的顶层节点比如<html>的父节点是 BeautifulSoup 对象:
html_tag = soup.html
print(type(html_tag.parent))
print('5.-------------------')
# BeautifulSoup 对象的 .parent 是None:
print(soup.parent)
遍历所有父节点:
soup = BeautifulSoup(html_doc, "lxml")
link = soup.a
for parent in link.parents:
if parent is None:
print(parent)
else:
print(parent.name)

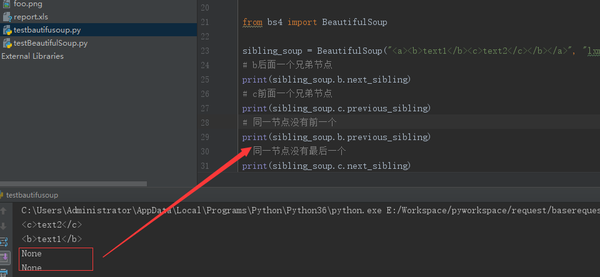
7.兄弟节点
同一个级别的节点查找
sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>", "lxml")
# b后面一个兄弟节点
print(sibling_soup.b.next_sibling)
# c前面一个兄弟节点
print(sibling_soup.c.previous_sibling)
# 同一节点没有前一个
print(sibling_soup.b.previous_sibling)
# 同一节点没有最后一个
print(sibling_soup.c.next_sibling)
获取前后所有的兄弟节点
注意:这些节点包括字符串和符号
soup = BeautifulSoup(html_doc, "lxml")
for sibling in soup.a.next_siblings:
print('--------------------------')
print(repr(sibling))
for sibling in soup.find(id="link3").previous_siblings:
print('******************************')
print(repr(sibling))

8.回退和前进
注意看next_sibling和next_element的差别
soup = BeautifulSoup(html_doc, "lxml")
last_a_tag = soup.find("a", id="link3")
# 是指link3之后的内容
print(last_a_tag.next_sibling)
print('----------------------')
# 是指link3内部之后的内容
print(last_a_tag.next_element)
print(last_a_tag.next_element.next_element)
soup = BeautifulSoup(html_doc, "lxml")
last_a_tag = soup.find("a", id="link3")
#next_elements和previous_elements 会访问当前节点内部往后和外部往后的所有内容。内部往后优先
for element in last_a_tag.next_elements:
print(repr(element))
还有一节,培训新手的文档就结束了。真心希望同学们要好好学习,不然我白讲。 不下班回家陪我的小公举,却来义务教你写代码,而且是从零开始手把手教。兄弟们要加油啊
Python爬虫系列(五):分析HTML结构的更多相关文章
- 爬虫系列(五) re的基本使用
1.简介 究竟什么是正则表达式 (Regular Expression) 呢?可以用下面的一句话简单概括: 正则表达式是一组特殊的 字符序列,由一些事先定义好的字符以及这些字符的组合形成,常常用于 匹 ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- Python爬虫进阶五之多线程的用法
前言 我们之前写的爬虫都是单个线程的?这怎么够?一旦一个地方卡到不动了,那不就永远等待下去了?为此我们可以使用多线程或者多进程来处理. 首先声明一点! 多线程和多进程是不一样的!一个是 thread ...
- Python爬虫入门五之URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理. 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的 ...
- 转 Python爬虫入门五之URLError异常处理
静觅 » Python爬虫入门五之URLError异常处理 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的服务器 服务器不存在 在代码中, ...
- Python爬虫和情感分析简介
摘要 这篇短文的目的是分享我这几天里从头开始学习Python爬虫技术的经验,并展示对爬取的文本进行情感分析(文本分类)的一些挖掘结果. 不同于其他专注爬虫技术的介绍,这里首先阐述爬取网络数据动机,接着 ...
- Python爬虫系列 - 初探:爬取旅游评论
Python爬虫目前是基于requests包,下面是该包的文档,查一些资料还是比较方便. http://docs.python-requests.org/en/master/ POST发送内容格式 爬 ...
- python 爬虫系列教程方法总结及推荐
爬虫,是我学习的比较多的,也是比较了解的.打算写一个系列教程,网上搜罗一下,感觉别人写的已经很好了,我没必要重复造轮子了. 爬虫不过就是访问一个页面然后用一些匹配方式把自己需要的东西摘出来. 而访问页 ...
- $python爬虫系列(2)—— requests和BeautifulSoup库的基本用法
本文主要介绍python爬虫的两大利器:requests和BeautifulSoup库的基本用法. 1. 安装requests和BeautifulSoup库 可以通过3种方式安装: easy_inst ...
随机推荐
- ECNU 计算机系统 (CSAPP) 教材习题作业答案集
这里是华东师范大学计算机系统的作业答案.由于几乎每一年布置的习题都几乎相同,网上的答案又比较分散,就把自己上学期提交的作业pdf放上来了,供参考. 长这样 Download Link:http://c ...
- 五分钟学Java:如何学习Java面试必考的网络编程
原创声明 本文作者:黄小斜 转载请务必在文章开头注明出处和作者. 本文思维导图 简介 Java作为一门后端语言,对于网络编程的支持是必不可少的,但是,作为一个经常CRUD的Java工程师,很多时候都不 ...
- ASP.NET Core应用的7种依赖注入方式
ASP.NET Core框架中的很多核心对象都是通过依赖注入方式提供的,如用来对应用进行初始化的Startup对象.中间件对象,以及ASP.NET Core MVC应用中的Controller对象和V ...
- 【python 数据结构】相同某个字段值的所有数据(整理成数组包字典的形式)
class MonitoredKeywordMore(APIView): def post(self, request): try: # 设置原生命令并且请求数据 parents_asin = str ...
- 软件版本管理工具-SVN
一.SVN简介 Subversion(svn)是一款开发源代码的版本控制系统. repository(源代码库):源代码统一存放的地方 Checkout(检出):当你手上没有源代码的时候,你需要从re ...
- Consider defining a bean named 'authenticator' in your configuration.
SpringBoot整合Shiro时出错: 异常日志: o.s.b.d.LoggingFailureAnalysisReporter: *************************** APPL ...
- hdu2112 dijkstra
题目链接:http://icpc.njust.edu.cn/Problem/Hdu/2112/ 只要需处理一下字符串,给他个编号再跑一半dijkstra就行. 代码如下: #include<bi ...
- 题解 P1002 【过河卒】
正文 简单描述一下题意: 士兵想要过河,他每一次可以往下走一格,也可以往右走一格,但马一步走到的地方是不能走的,问走到\(n\)行,\(m\)列有多少种走法 我们显然应该先根据马的位置将不能走的格子做 ...
- 【笔记3-24】Python语言基础
环境搭建与语法入门 遇到问题解决问题 积累 英语单词 认真听讲,多敲代码 计算机是什么 计算机的组成 计算机的使用方式 TUI文本交互 GUI图形化交互 windows 的命令行 Shell.Term ...
- Web 服务器压力测试实例详解
发表于 2012-1-6 14:53 | 来自 51CTO网页 Web 服务器搭建完成上线在即,其能够承载多大的访问量,响应速度.容错能力等性能指标,所有这些是管理人员最想知道也最为担心的.如何才能 ...