十分钟一起学会ResNet残差网络
作者 | 荔枝boy
目录
深层次网络训练瓶颈:梯度消失,网络退化
ResNet简介
ResNet解决深度网络瓶颈的魔力
ResNet使用的小技巧
总结
深层次网络训练瓶颈:梯度消失,网络退化
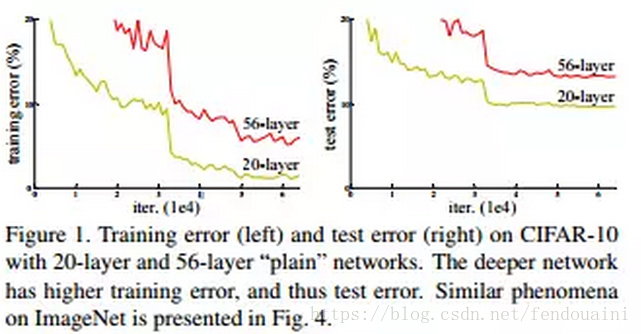
深度卷积网络自然的整合了低中高不同层次的特征,特征的层次可以靠加深网络的层次来丰富。从而,在构建卷积网络时,网络的深度越高,可抽取的特征层次就越丰富。所以一般我们会倾向于使用更深层次的网络结构,以便取得更高层次的特征。但是在使用深层次的网络结构时我们会遇到两个问题,梯度消失,梯度爆炸问题和网络退化的问题。
但是当使用更深层的网络时,会发生梯度消失、爆炸问题,这个问题很大程度通过标准的初始化和正则化层来基本解决,这样可以确保几十层的网络能够收敛,但是随着网络层数的增加,梯度消失或者爆炸的问题仍然存在。
还有一个问题就是网络的退化,举个例子,假设已经有了一个最优化的网络结构,是18层。当我们设计网络结构的时候,我们并不知道具体多少层次的网络时最优化的网络结构,假设设计了34层网络结构。那么多出来的16层其实是冗余的,我们希望训练网络的过程中,模型能够自己训练这五层为恒等映射,也就是经过这层时的输入与输出完全一样。但是往往模型很难将这16层恒等映射的参数学习正确,那么就一定会不比最优化的18层网络结构性能好,这就是随着网络深度增加,模型会产生退化现象。它不是由过拟合产生的,而是由冗余的网络层学习了不是恒等映射的参数造成的。
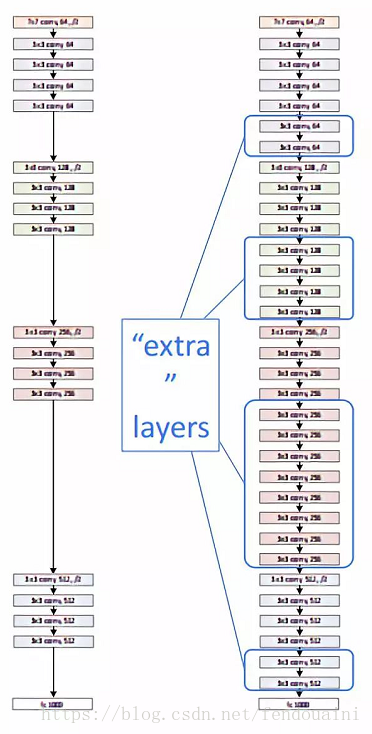
图一
ResNet简介
ResNet是在2015年有何凯明,张翔宇,任少卿,孙剑共同提出的,ResNet使用了一个新的思想,ResNet的思想是假设我们涉及一个网络层,存在最优化的网络层次,那么往往我们设计的深层次网络是有很多网络层为冗余层的。那么我们希望这些冗余层能够完成恒等映射,保证经过该恒等层的输入和输出完全相同。具体哪些层是恒等层,这个会有网络训练的时候自己判断出来。将原网络的几层改成一个残差块,残差块的具体构造如下图所示:
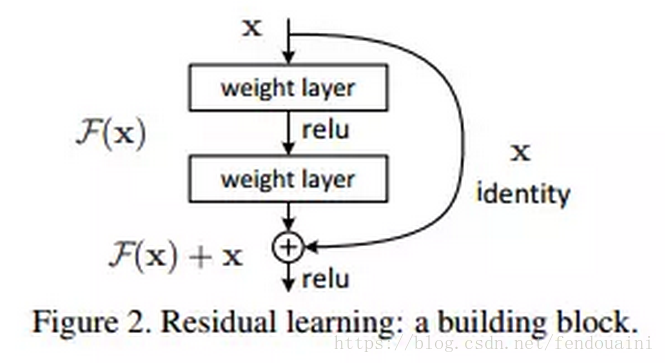
可以看到X是这一层残差块的输入,也称作F(x)为残差,x为输入值,F(X)是经过第一层线性变化并激活后的输出,该图表示在残差网络中,第二层进行线性变化之后激活之前,F(x)加入了这一层输入值X,然后再进行激活后输出。在第二层输出值激活前加入X,这条路径称作shortcut连接。
ResNet解决深度网络瓶颈的魔力
网络退化问题的解决:
我们发现,假设该层是冗余的,在引入ResNet之前,我们想让该层学习到的参数能够满足h(x)=x,即输入是x,经过该冗余层后,输出仍然为x。但是可以看见,要想学习h(x)=x恒等映射时的这层参数时比较困难的。ResNet想到避免去学习该层恒等映射的参数,使用了如上图的结构,让h(x)=F(x)+x;这里的F(x)我们称作残差项,我们发现,要想让该冗余层能够恒等映射,我们只需要学习F(x)=0。学习F(x)=0比学习h(x)=x要简单,因为一般每层网络中的参数初始化偏向于0,这样在相比于更新该网络层的参数来学习h(x)=x,该冗余层学习F(x)=0的更新参数能够更快收敛,如图所示:
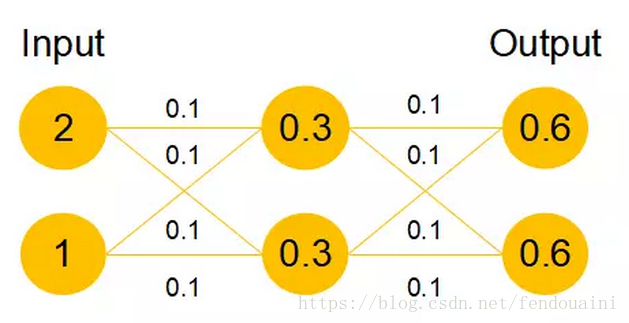
图四
假设该曾网络只经过线性变换,没有bias也没有激活函数。我们发现因为随机初始化权重一般偏向于0,那么经过该网络的输出值为[0.6 0.6],很明显会更接近与[0 0],而不是[2 1],相比与学习h(x)=x,模型要更快到学习F(x)=0。
并且ReLU能够将负数激活为0,过滤了负数的线性变化,也能够更快的使得F(x)=0。这样当网络自己决定哪些网络层为冗余层时,使用ResNet的网络很大程度上解决了学习恒等映射的问题,用学习残差F(x)=0更新该冗余层的参数来代替学习h(x)=x更新冗余层的参数。
这样当网络自行决定了哪些层为冗余层后,通过学习残差F(x)=0来让该层网络恒等映射上一层的输入,使得有了这些冗余层的网络效果与没有这些冗余层的网络效果相同,这样很大程度上解决了网络的退化问题。
梯度消失或梯度爆炸问题的解决:
我们发现很深的网络层,由于参数初始化一般更靠近0,这样在训练的过程中更新浅层网络的参数时,很容易随着网络的深入而导致梯度消失,浅层的参数无法更新。

图五
可以看到,假设现在需要更新b1,w2,w3,w4参数因为随机初始化偏向于0,通过链式求导我们会发现,w4w3w2相乘会得到更加接近于0的数,那么所求的这个b1的梯度就接近于0,也就产生了梯度消失的现象。
ResNet最终更新某一个节点的参数时,由于h(x)=F(x)+x,由于链式求导后的结果如图所示,不管括号内右边部分的求导参数有多小,因为左边的1的存在,并且将原来的链式求导中的连乘变成了连加状态(正是 ),都能保证该节点参数更新不会发生梯度消失或梯度爆炸现象。

图六
这样ResNet在解决了阻碍更深层次网络优化问题的两个重要问题后,ResNet就能训练更深层次几百层乃至几千层的网络并取得更高的精确度了。
ResNet使用的小技巧
这里是应用了ResNet的网络图,这里如果遇到了h(x)=F(x)+x中x的维度与F(x)不同的维度时,我们需要对identity加入Ws来保持Ws*x的维度与F(x)的维度一致。
x与F(x)维度相同时:
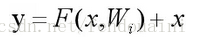
x与F(x)维度不同时:
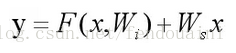
下边是ResNet的网络结构图:
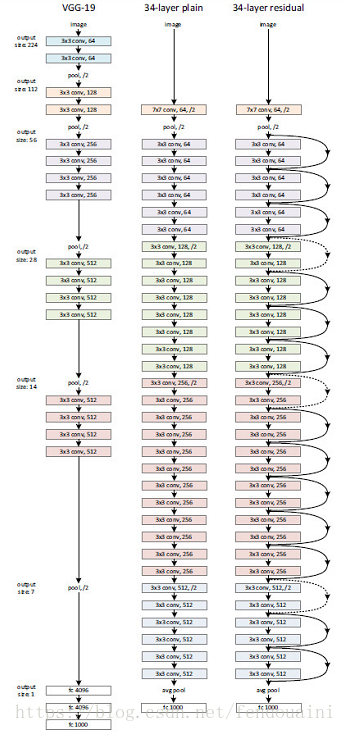
使用1*1卷积减少参数和计算量:
如果用了更深层次的网络时,考虑到计算量,会先用1*1的卷积将输入的256维降到64维,然后通过1*1恢复。这样做的目的是减少参数量和计算量。
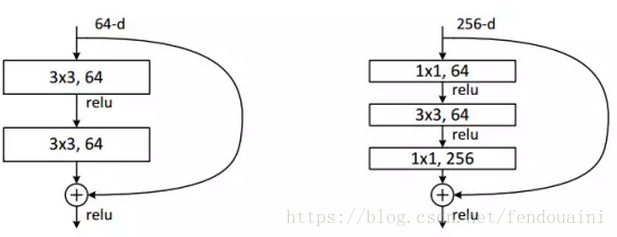
图八
左图是ResNet34,右图是ResNet50/101/152。这一个模块称作building block,右图称之为bottleneck design。在面对50,101,152层的深层次网络,意味着有很大的计算量,因此这里使用1*1卷积先将输入进行降维,然后再经过3*3卷积后再用1*1卷积进行升维。使用1*1卷积的好处是大大降低参数量计算量。
总结
通过上述的学习,你应该知道了,现如今大家普遍认为更好的网络是建立在更宽更深的网络基础上,当你需要设计一个深度网络结构时,你永远不知道最优的网络层次结构是多少层,一旦你设计的很深入了,那势必会有很多冗余层,这些冗余层一旦没有成功学习恒等变换h(x)=x,那就会影响网络的预测性能,不会比浅层的网络学习效果好从而产生退化问题。
ResNet的过人之处,是他很大程度上解决了当今深度网络头疼的网络退化问题和梯度消失问题。使用残差网络结构h(x)=F(x)+x代替原来的没有shortcut连接的h(x)=x,这样更新冗余层的参数时需要学习F(x)=0比学习h(x)=x要容易得多。而shortcut连接的结构也保证了反向传播更新参数时,很难有梯度为0的现象发生,不会导致梯度消失。
这样,ResNet的构建,使我们更朝着符合我们的直觉走下去,即越深的网络对于高级抽象特征的提取和网络性能更好,不用在担心随着网络的加深发生退化问题了。
近段时间,准备持续发表一些CNN常见的网络模型讲解。好了,今天的十分钟就带你一起学会ResNet,下次的十分钟我们再见。
十分钟一起学会ResNet残差网络的更多相关文章
- 跟我学算法-图像识别之图像分类(下)(GoogleNet网络, ResNet残差网络, ResNext网络, CNN设计准则)
1.GoogleNet 网络: Inception V1 - Inception V2 - Inception V3 - Inception V4 1. Inception v1 split - me ...
- 十分钟一起学会Inception网络
作者 | 荔枝boy 编辑 | 安可 一.Inception网络简介 二.Inception网络模块 三.Inception网络降低参数计算量 四.Inception网络减缓梯度消失现象 五.Ince ...
- 十分钟能学会的框架,MVC+20个常用函数
LazyPHP(以下简称LP)是一个轻框架. 之所以开发这么一个框架,是因为其他框架给的太多.在高压力的情况下,ORM和盘根错节的对象树反而将简单的页面请求处理复杂化,在调试和性能上带来反面效果. L ...
- ResNet 残差网络训练数据
https://github.com/tornadomeet/ResNet 图片地址: data/trian/cifar10_cifar10.rec data/train/cifar10_val.re ...
- GDB十分钟教程【转载于网络爱好者】
本文写给主要工作在Windows操作系统下而又需要开发一些跨平台软件的程序员朋友,以及程序爱好者. GDB是一个由GNU开源组织发布的.UNIX/LINUX操作系统下的.基于命令行的.功能强大的程序调 ...
- 十分钟快速学会Matplotlib基本图形操作
在学习Python的各种工具包的时候,看网上的各种教程总是感觉各种方法很多很杂,参数的种类和个数也十分的多,理解起来需要花费不少的时间. 所以我在这里通过几个例子,对方法和每个参数都进行详细的解释,这 ...
- 深度残差网络——ResNet学习笔记
深度残差网络—ResNet总结 写于:2019.03.15—大连理工大学 论文名称:Deep Residual Learning for Image Recognition 作者:微软亚洲研究院的何凯 ...
- 从头学pytorch(二十):残差网络resnet
残差网络ResNet resnet是何凯明大神在2015年提出的.并且获得了当年的ImageNet比赛的冠军. 残差网络具有里程碑的意义,为以后的网络设计提出了一个新的思路. googlenet的思路 ...
- PHP学习过程_Symfony_(3)_整理_十分钟学会Symfony
这篇文章主要介绍了Symfony学习十分钟入门教程,详细介绍了Symfony的安装配置,项目初始化,建立Bundle,设计实体,添加约束,增删改查等基本操作技巧,需要的朋友可以参考下 (此文章已被多人 ...
随机推荐
- MYSQL对数据库和表的基本操作
CREATE DATABASE testdb CHARSET=UTF8 创建一个数据库 名字叫做testdb USE testdb; 选择数据库 CREATE TABLE testTable1( ) ...
- percona-toolkit 之 【pt-query-digest】介绍
背景: 做为一个MySQL DBA,分析慢查询是日常主要的工作之一,之前一直使用mysqlsla作为分析慢查询的, 因为简单并且也能满足自己对慢查询分析的要求,对于另一个工具pt-query-dige ...
- java8新特性——stream笔记
stream对象 Stream IntStream LongStream DoubleStream 创建 常用的三种方式: 使用list对象: list.stream() − 为集合创建串行流. li ...
- UVA - 10462 Is There A Second Way Left?
题意: 给你一张无向图,让你判断三种情况:1.不是连通图(无法形成生成树)2.只能生成唯一的生成树 3.能生成的生成树不唯一(有次小生成树),这种情况要求出次小生成树的边权值和. 思路: 比较常见的次 ...
- 关于 InnoDB 锁的超全总结
有点全的 InnoDB 锁 几个月之前,开始深入学习 MySQL .说起数据库,并发控制是其中很重要的一部分.于是,就这样开起了 MySQL 锁的学习,随着学习的深入,发现想要更好的理解锁,需要了解 ...
- xml模块介绍
# xml 是一门可拓展的语言 # xml 语法 是用<>包裹的起来的<>就是标签, xml可以由多个<>组成 也可以由单个<>组成, # < ...
- ELK springboot日志收集
一.安装elasticsearch 可以查看前篇博客 elasticsearch安装.elasticsearch-head 安装 二.安装 配置 logstash 1.安装logstash 下载地址: ...
- hadoop的伪分布式系统
1.下载hadoop 链接:https://pan.baidu.com/s/10HBQd57pA4OYNPXe8Dwx9g 提取码:1wtk 运行hadoop需要Java环境,所以还需要安装jdk 链 ...
- 什么是SSH与SSH客户端
1.什么是SSH? SSH 为 Secure Shell 的缩写,由 IETF 的网络工作小组(Network Working Group)所制定:SSH 为建立在应用层和传输层基础上的安全协议.SS ...
- openwrt sdk 添加软件包 Makefile 写法
参考 https://openwrt.org/start?id=docs/guide-developer/packages ,英文稍好点的自己看吧,我写出来也就是方便,英文不好的人看. 软件包的来源, ...