Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]
日期:2020.02.02
博客期:141
星期日
【本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)】
所有相关跳转:
a.【简单准备】
b.【云图制作+数据导入】
c.【拓扑数据】
d.【数据修复】
e.【解释修复+热词引用】(本期博客)
f.【JSP演示+页面跳转】
g.【热词分类+目录生成】
h.【热词关系图+报告生成】
i . 【App制作】
j . 【安全性改造】
嗯~昨天相当于把数据重新爬了一边,但是貌似数据仍然不合适。问题到底出在什么地方呢?我直接回答了吧!如果我们的需求仅仅是云图展示,那么这些数据就够用了,甚至还多,因为任务是要实现“标记热词出现在哪个新闻里”,这就需要我们记录一下标题。当然!这也不难实现。我先把我所有的 Python 类全部单独分包做成一个.py文件。然后,我将数据库文件重新配置,将sql文件覆盖到上一篇博客中(本篇博客也会发出下载链接)。然后找到之前的添加解释的类,进行二次利用,重新爬取!这个任务也做完了以后呢,我会把之前的链接分别对应到每一个热词,利用 jsp 技术实现热词相关信息的展示。最后,将探索一下热词之间的紧密程度(说实在的我现在有点儿不太理解这是什么意思,等睡一觉,起来问了老师,再修改本篇博客),利用 ECharts 接口制作可供展示的关系图,努力肝了一天发现只做到了展示,没能完成热词关系探索,嗯,交给今后的我了。
1、整理文件(修改之前的 爬取网页的 文件 不再 撰写)
嗯,现在我已经将文件规整好了,如下图。先说一下,改造以后的python代码将每一个类分别单独封装成一个.py文件,每一个执行过程将单独使用一个.py文件,并放入到 itWords.process 包当中!我想过可以将所有执行过程写到一个.py文件里,但这样的话就有点儿乱,最终还是决定分开写。
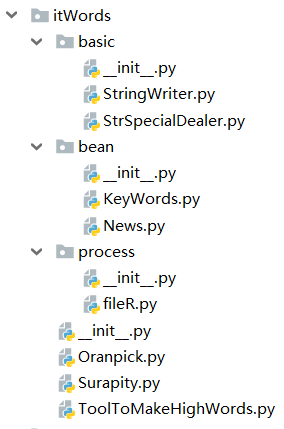
itWords.basic 包:
此包类已经被整合,详细参照博客: Python 爬取的类封装【将来可能会改造,持续更新...】(2020年寒假小目标09)
itWords.bean 包:
import codecs class KeyWords:
# 热词
word = ""
# 对应链接
link = ""
# 频数
num = 0 def __init__(self,word,link,num):
self.word = word
self.link = link
self.num = num # 整理成 一行 字符串
def __toString__(self):
return self.word +"\t"+str(self.num)+"\t"+self.link # 将 自动整理好的字符串 带换行符 追加 到文件后
def __toFile__(self,filePath):
f = codecs.open(filePath, "a+", 'utf-8')
f.write(self.__toString__() + "\n")
f.close()
KeyWords.py
import codecs class News:
# 标题
title = ""
# 内容
info = ""
# 链接
link = "" # 初始化
def __init__(self,title,info,link):
self.title = title
self.info = info
self.link = link # 整理成 一行 字符串
def __toString__(self):
return self.link+"\t"+self.title+"\t"+self.info # 将 自动整理好的字符串 带换行符 追加 到文件后
def __toFile__(self,filePath):
f = codecs.open(filePath, "a+", 'utf-8')
f.write(self.__toString__() + "\n")
f.close() # 将 标题和内容 衔接的 字符串 予以返回 ( 计算词语频率 )
def getSimple(self):
return self.title+self.info
News.py
itWords.process 包:
import codecs def makeSql():
file_path = "../../testFile/rc/words_sql.txt"
f = codecs.open(file_path, "w+", 'utf-8')
f.write("")
f.close() fw = open("../../testFile/rc/news.txt", mode='r', encoding='utf-8')
tmp = fw.readlines() num = tmp.__len__() for i in range(0,num):
group = tmp[i].split("\t")
group[0] = "'" + group[0] + "'"
group[2] = "'" + group[2][0:group[2].__len__()-1] + "'"
f = codecs.open(file_path, "a+", 'utf-8')
f.write("Insert into words values ("+group[0]+","+group[1]+","+group[2]+");"+"\n")
f.close() def makeOne():
file_path = "../../testFile/rc/keyword_moreinfo.txt"
fw = open("../../testFile/rc/keywords.txt", mode='r', encoding='utf-8')
tmp = fw.readlines()
fileR.py
itWords 包:
import jieba
import jieba.analyse # 新闻段落高频词分析器
class ToolToMakeHighWords:
# 要处理的字符串
test_str = "" # 初始化
def __init__(self,test_str):
self.test_str = str(test_str)
pass # 使用 文件 建立数据
def buildWithFile(self,filePath,type):
file = open(filePath, encoding=type)
self.test_str = file.read() # 直接给予 字符串 建立
def buildWithStr(self,test_str):
self.test_str = test_str
pass # 统计词
def getWords(self,isSimple,isAll):
if(isSimple):
words = jieba.lcut_for_search(self.test_str)
return words
else:
# True - 全模式 , False - 精准模式
words = jieba.cut(self.test_str, cut_all=isAll)
return words # 统计词频并排序
def getHighWords(self,words):
data = {}
for charas in words:
if len(charas) < 2:
continue
if charas in data:
data[charas] += 1
else:
data[charas] = 1 data = sorted(data.items(), key=lambda x: x[1], reverse=True) # 排序 return data # 获取 前 num 名的高频词 ( 带频率 )
def selectObjGroup(self,num):
a = jieba.analyse.extract_tags(self.test_str, topK=num, withWeight=True, allowPOS=())
return a # 获取 前 num 名的高频词 ( 不带频率 )
def selectWordGroup(self,num):
b = jieba.analyse.extract_tags(self.test_str, topK=num, allowPOS=())
return b
ToolToMakeHighWords.py
import parsel
from urllib import request
import codecs from itWords.bean.KeyWords import KeyWords
from itWords.Oranpick import Oranpick # [ 连续网页爬取的对象 ]
from itWords.ToolToMakeHighWords import ToolToMakeHighWords class Surapity:
page = 1
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'}
basicURL = ""
oran = "" # ---[定义构造方法]
def __init__(self):
self.page = 1
self.basicURL = "https://news.cnblogs.com/"
self.oran = Oranpick("https://start.firefoxchina.cn/") def __close__(self):
self.oran.__close__() def __next__(self):
self.page = self.page + 1
self.basicURL = 'https://news.cnblogs.com/n/page/'+str(self.page)+'/' # 获取 url 的内部 HTML 代码
def getHTMLText(self):
req = request.Request(url=self.basicURL, headers=self.headers)
r = request.urlopen(req).read().decode()
return r # 获取页面内的基本链接
def getMop(self,filePath):
index_html = self.getHTMLText()
index_sel = parsel.Selector(index_html)
links = index_sel.css(".news_entry a::attr(href)").extract()
size = links.__len__()
for i in range(0,size):
link = "https://news.cnblogs.com"+links[i]
self.oran.__reset__(link)
news = self.oran.getNews()
ttm = ToolToMakeHighWords(news.getSimple())
words = ttm.getHighWords(ttm.getWords(False,False))
leng = words.__len__()
# 频数 要在 15次 以上
for i in range(0,leng):
if words[i][1]<=15:
break
keyw = KeyWords(word=words[i][0],link=link,num=words[i][1])
keyw.__toFile__(filePath)
Surapity.py
import parsel
import time
from selenium import webdriver from itWords.basic import StrSpecialDealer
from itWords.bean import News # [ 一次性网页爬取的对象 ] class Oranpick:
basicURL = ""
profile = "" # ---[定义构造方法]
def __init__(self, url):
self.basicURL = url
self.profile = webdriver.Firefox()
self.profile.get("https://account.cnblogs.com/signin?returnUrl=https%3A%2F%2Fnews.cnblogs.com%2Fn%2F654191%2F")
self.profile.find_element_by_id("LoginName").send_keys("youraccount")
self.profile.find_element_by_id("Password").send_keys("yourpassword")
time.sleep(2)
self.profile.find_element_by_id("submitBtn").click()
# 给予 15s 的验证码人工验证环节
time.sleep(15)
self.profile.get(url) # 重新设置
def __reset__(self,url):
self.basicURL = url
self.profile.get(url) # ---[定义释放方法]
def __close__(self):
self.profile.quit() # 获取 url 的内部 HTML 代码
def getHTMLText(self):
a = self.profile.page_source
return a # 获取基本数据
def getNews(self):
index_html = self.getHTMLText()
index_sel = parsel.Selector(index_html)
context = index_sel.css('#news_title a')[0].extract()
context = StrSpecialDealer.getReaction(context)
context = StrSpecialDealer.simpleDeal(context)
conform = index_sel.css('#news_body')[0].extract()
conform = StrSpecialDealer.deleteRe(conform)
conform = StrSpecialDealer.simpleDeal(conform)
news = News(title=context, info=conform, link=self.basicURL)
return news
Oranpick.py
整理完成,接下来还会改代码的,上面的 basic 包应该是不会改了。
2、重写 Bean 相关的基础类,并重新爬取(可记录标题)
需要将表示 标题 的 title 属性加到 KeyWords 类中,并修改 init 初始化方法 和 toString 转性方法:
import codecs class KeyWords:
# 热词
word = ""
# 对应链接
link = ""
# 频数
num = 0
# 链接标题
title = "" def __init__(self,word,link,num,title):
self.word = word
self.link = link
self.num = num
self.title = title # 整理成 一行 字符串
def __toString__(self):
return self.word +"\t"+str(self.num)+"\t"+self.title+"\t"+self.link # 将 自动整理好的字符串 带换行符 追加 到文件后
def __toFile__(self,filePath):
f = codecs.open(filePath, "a+", 'utf-8')
f.write(self.__toString__() + "\n")
f.close()
KeyWords.py
之后找到引用 KeyWords 的地方,也就是 Surapity 类的 getMop() 方法,将 keyw = KeyWords(word=words[i][0],link=link,num=words[i][1]) 一句改成
keyw = KeyWords(word=words[i][0],link=link,num=words[i][1],title=news.title) ,修改完成后:
import parsel
from urllib import request
import codecs from itWords.bean.KeyWords import KeyWords
from itWords.Oranpick import Oranpick # [ 连续网页爬取的对象 ]
from itWords.ToolToMakeHighWords import ToolToMakeHighWords class Surapity:
page = 1
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'}
basicURL = ""
oran = "" # ---[定义构造方法]
def __init__(self):
self.page = 1
self.basicURL = "https://news.cnblogs.com/"
self.oran = Oranpick("https://start.firefoxchina.cn/") def __close__(self):
self.oran.__close__() def __next__(self):
self.page = self.page + 1
self.basicURL = 'https://news.cnblogs.com/n/page/'+str(self.page)+'/' # 获取 url 的内部 HTML 代码
def getHTMLText(self):
req = request.Request(url=self.basicURL, headers=self.headers)
r = request.urlopen(req).read().decode()
return r # 获取页面内的基本链接
def getMop(self,filePath):
index_html = self.getHTMLText()
index_sel = parsel.Selector(index_html)
links = index_sel.css(".news_entry a::attr(href)").extract()
size = links.__len__()
for i in range(0,size):
link = "https://news.cnblogs.com"+links[i]
self.oran.__reset__(link)
news = self.oran.getNews()
ttm = ToolToMakeHighWords(news.getSimple())
words = ttm.getHighWords(ttm.getWords(False,False))
leng = words.__len__()
# 频数 要在 15次 以上
for i in range(0,leng):
if words[i][1]<=15:
break
keyw = KeyWords(word=words[i][0],link=link,num=words[i][1],title=news.title)
keyw.__toFile__(filePath)
Surapity.py
之后,在 process 编写 过程文件 paData.py 重新爬取
from itWords.Surapity import Surapity
from itWords.basic.StringWriter import StringWriter def main():
filepath = "../../testFile/rc/news.txt"
s = Surapity()
StringWriter(filepath).makeFileNull()
s.getMop(filepath)
s.__next__()
s.getMop(filepath)
while s.page <= 100:
s.__next__()
s.getMop(filepath)
s.__close__() main()
paData.py
爬取得到结果如下:

3、简单的数据导入(附带sql文件)
在MySql中,重新建立 words 表:
准备 Insert 语句,修改 fileR.py ,并执行:
import codecs def makeSql():
file_path = "../../testFile/rc/words_sql.txt"
f = codecs.open(file_path, "w+", 'utf-8')
f.write("")
f.close() fw = open("../../testFile/rc/news.txt", mode='r', encoding='utf-8')
tmp = fw.readlines() num = tmp.__len__() for i in range(0,num):
group = tmp[i].split("\t")
group[0] = "'" + group[0] + "'"
group[3] = "'" + group[3][0:group[3].__len__()-1] + "'"
f = codecs.open(file_path, "a+", 'utf-8')
f.write("Insert into words values ("+group[0]+","+group[1]+",'"+group[2]+"',"+group[3]+");"+"\n")
f.close() makeSql()
fileR.py
之后,进入数据库,选择新建查询,输入 testFile/rc/words_sql.txt 文件内的sql语句,并予以执行
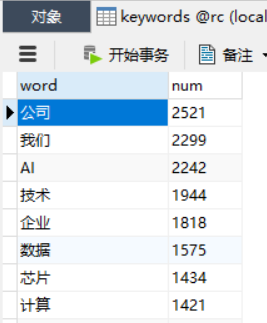
使用上次建视图的代码重新建立视图(也可以建成新表)名称:keywords,如图:
Sql 文件下载地址:https://files.cnblogs.com/files/onepersonwholive/words.zip
4、解释修复——重新利用 百度百科 进行解释性文字爬取
先使用 Navicat 导出 keywords 表,设置 \t 为列间隔,\n 为行间隔,导出 txt 文件(不要文本限定符)
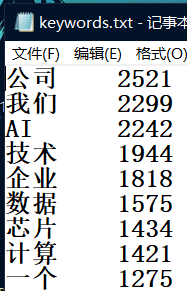
之后,将此文件剪切到 testFile/rc/keywords.txt 处
编写新的Bean类 ExplainThings:
class ExplainThings:
# --- [ 方法域 ]
# 初始化
def __init__(self,word,exp,num):
self.word = word
self.num = num
self.exp = exp # 整理成 一行 字符串
def __toString__(self):
return self.word + "\t" + str(self.num) + "\t" + self.exp # 整理成 Insert 语句
def __toSql__(self):
return "Insert into keywords VALUES ('"+self.word+"',"+str(self.num)+",'"+self.exp+"');" # --- [ 属性域 ]
# 热词
word = ""
# 解释
exp = ""
# 频数
num = 0
ExplainThings.py
之后将老代码,进行整合和修改
from itWords.WebConnector import WebConnector
from itWords.basic.StrSpecialDealer import StrSpecialDealer
from itWords.basic.StringWriter import StringWriter
from itWords.bean.ExplainThings import ExplainThings wc = WebConnector()
sw = StringWriter("../../testFile/rc/moreinfo.txt") sw.makeFileNull() fw = open("../../testFile/rc/keywords.txt", mode='r', encoding='utf-8')
lines = fw.readlines() num = lines.__len__()
print(num)
for i in range(0, num):
print(str(i))
str_line = lines[i]
gr = str_line.split("\t")
name_b = StrSpecialDealer.simpleDeal(gr[0])
num_b = StrSpecialDealer.simpleDeal(gr[1])
wc.__reset__()
wc.getMore(name_b)
more_b = wc.getFirstChanel()
ex = ExplainThings(word=name_b,exp=more_b,num=num_b)
sw.write(ex.__toSql__()) wc.__close__()
paExplain.py
爬取得到Insert数据以后,将keywords表删掉(或视图),新建 keywords表,将 Insert文件执行一边

最终得到数据,如图所示:
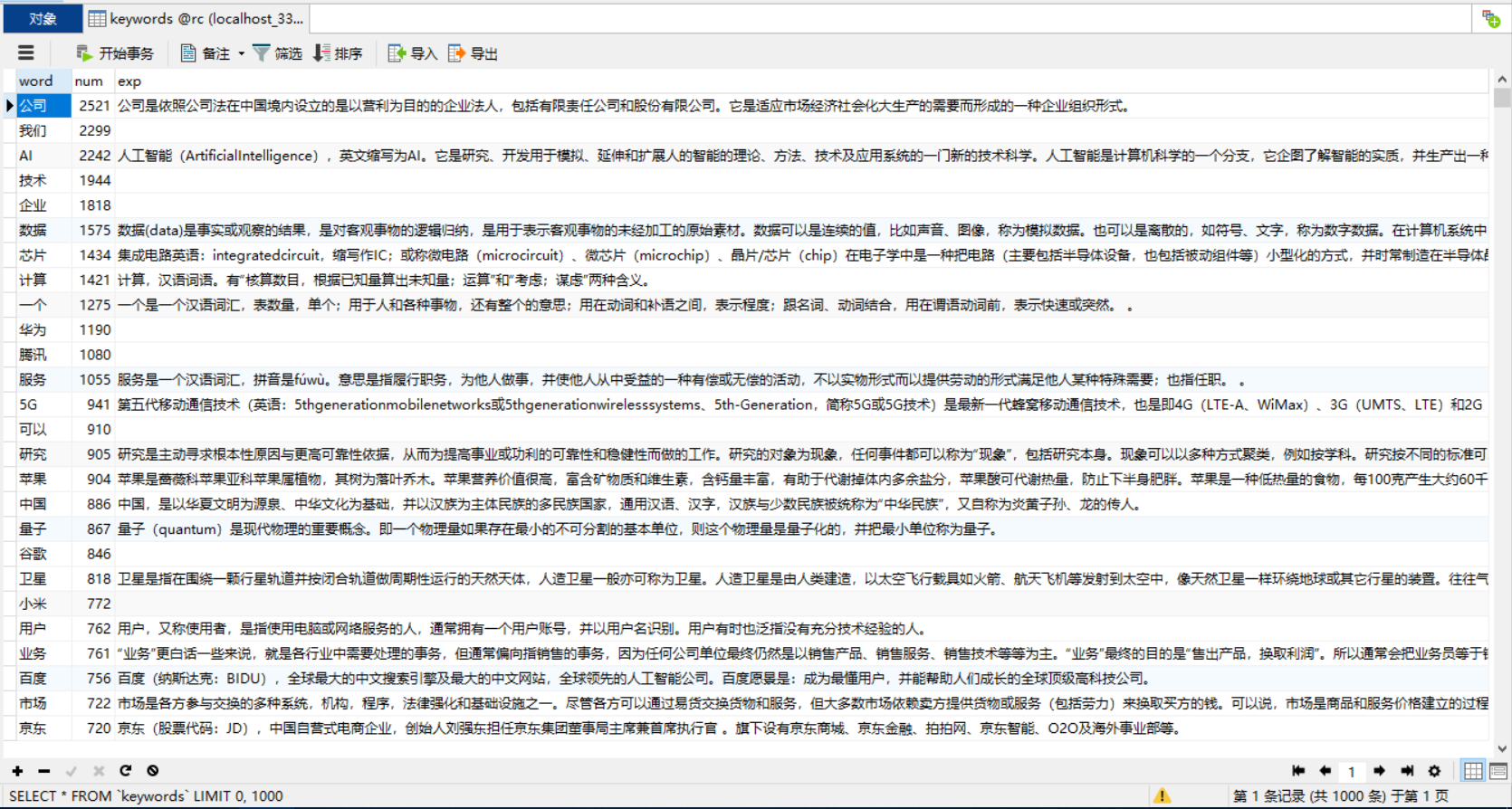
5、jsp实现热词的信息展示(附带 按照 词频或热词拼写 的 顺序或逆序 排序)——先显示单页30条数据
紧赶慢赶,写了展示部分,这还需要进一步的改造,今天时间不多了,还要抓紧时间赶另一项任务呢!
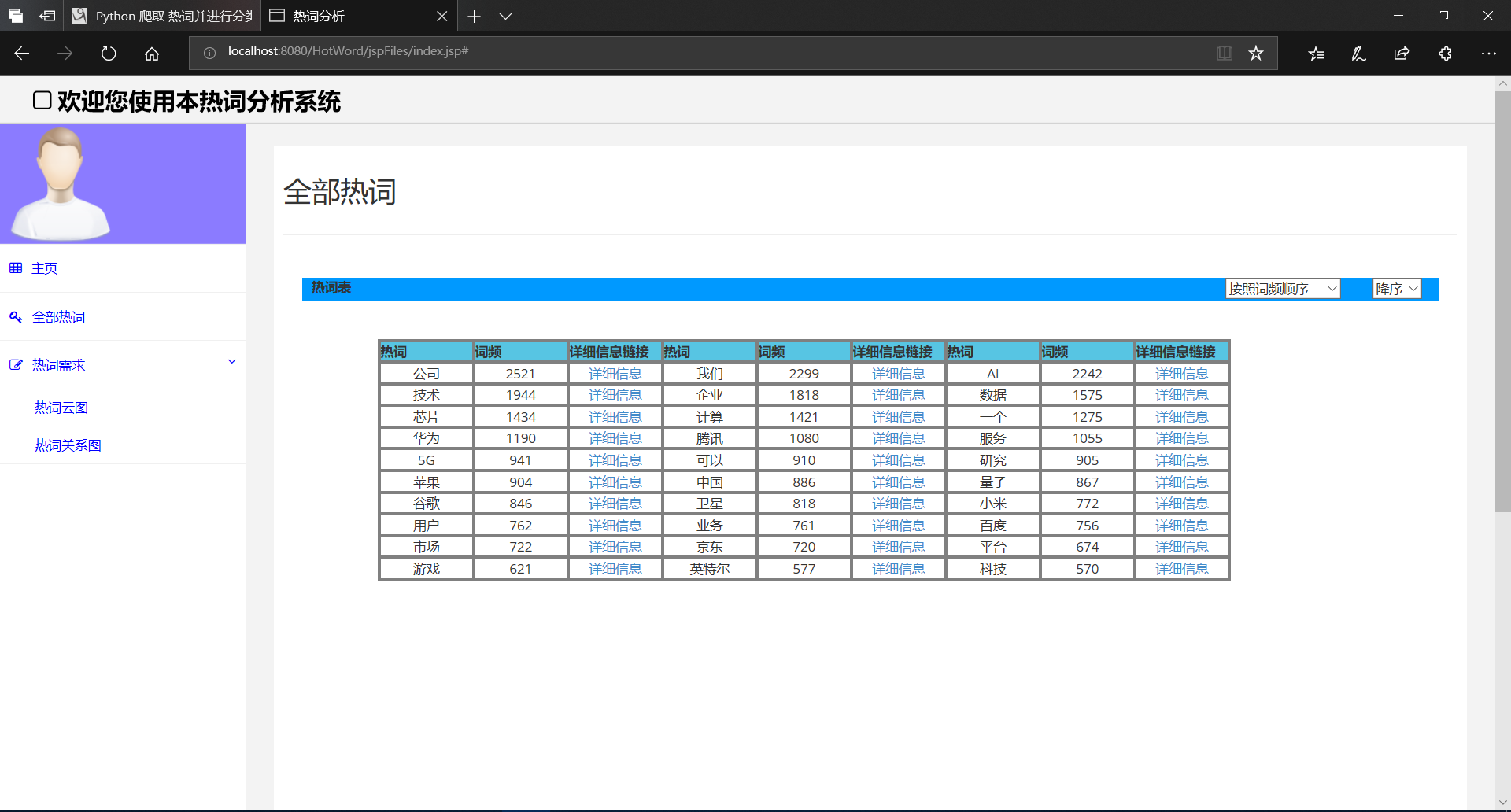
先设置每一页30个数据,数据横向显示好像有点儿不妥,竖向感觉也不太合适啊!页面跳转交给明天的我来写。
6、将链接写到每一个对应热词当中去
实现了点击 “详细信息”链接可以跳转页面至单个热词的页面
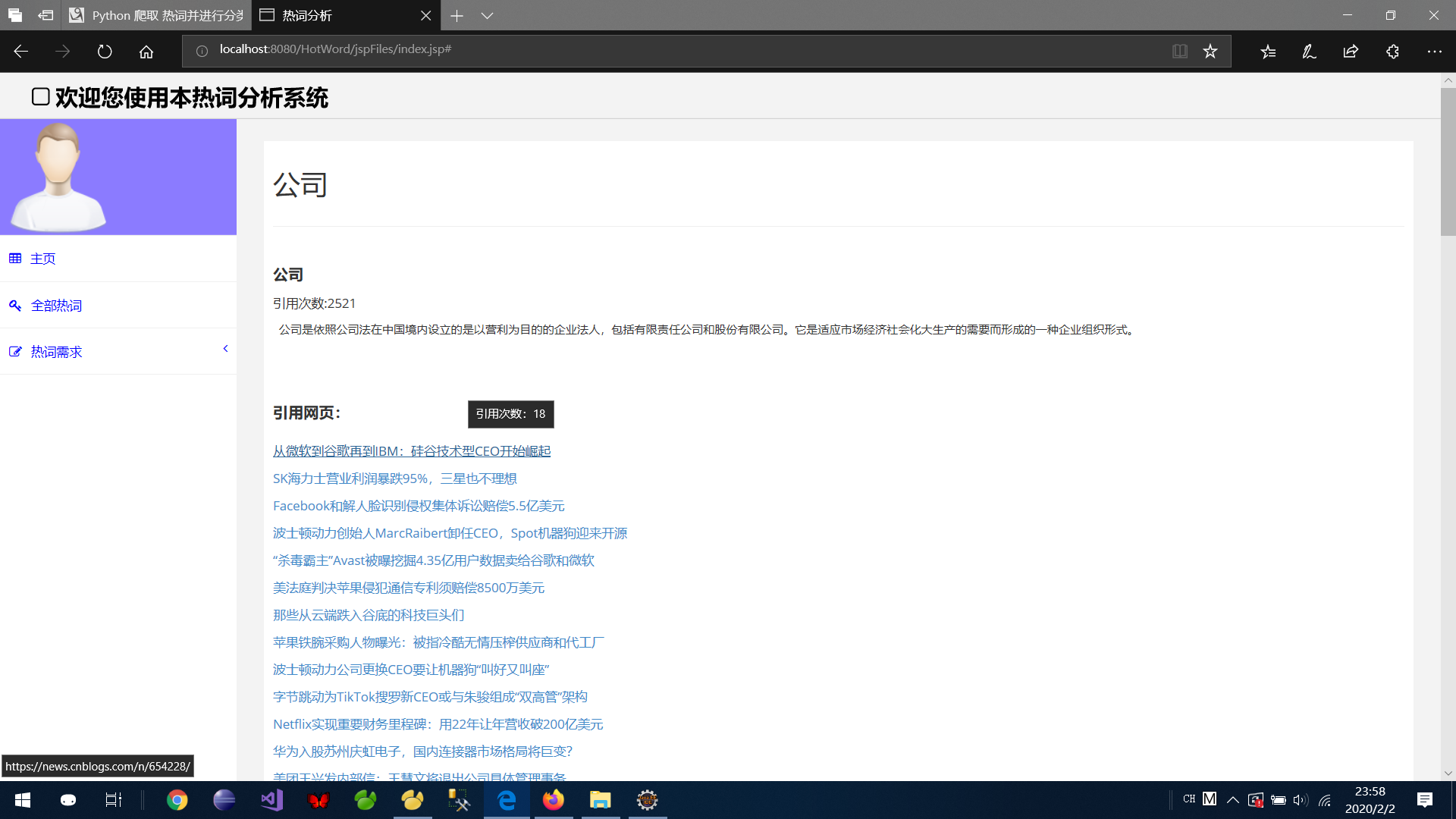
总算是在2月3号以前写完了,呼!明天整理页面的问题!
Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]的更多相关文章
- Python 爬取 热词并进行分类数据分析-[数据修复]
日期:2020.02.01 博客期:140 星期六 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- python 爬取网页简单数据---以及详细解释用法
一.准备工作(找到所需网站,获取请求头,并用到请求头) 找到所需爬取的网站(这里举拉勾网的一些静态数据的获取)----------- https://www.lagou.com/zhaopin/Pyt ...
- Python 爬取 热词并进行分类数据分析-[云图制作+数据导入]
日期:2020.01.28 博客期:136 星期二 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入](本期博客) ...
- Python 爬取 热词并进行分类数据分析-[简单准备] (2020年寒假小目标05)
日期:2020.01.27 博客期:135 星期一 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备](本期博客) b.[云图制作+数据导入] ...
- Python 爬取 热词并进行分类数据分析-[热词分类+目录生成]
日期:2020.02.04 博客期:143 星期二 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[ ...
- Python 爬取 热词并进行分类数据分析-[拓扑数据]
日期:2020.01.29 博客期:137 星期三 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[App制作]
日期:2020.02.14 博客期:154 星期五 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[JSP演示+页面跳转]
日期:2020.02.03 博客期:142 星期一 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[热词关系图+报告生成]
日期:2020.02.05 博客期:144 星期三 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
随机推荐
- buuctf 变异凯撒
加密密文:afZ_r9VYfScOeO_UL^RWUc 格式:flag{ } 这里我们发现a, f, Z, _的ASCii码是 97, 102, 90, 95 而再看这里flag{}的ASCii码是- ...
- 路飞-自定义User表和Media配置
user模块User表 创建user模块 """ 前提:在 luffy 虚拟环境下 1.终端从项目根目录进入apps目录 >: cd luffyapi & ...
- 【PAT甲级】1112 Stucked Keyboard (20分)(字符串)
题意: 输入一个正整数K(1<K<=100),接着输入一行字符串由小写字母,数字和下划线组成.如果一个字符它每次出现必定连续出现K个,它可能是坏键,找到坏键按照它们出现的顺序输出(相同坏键 ...
- C语言程序的错误和警告
一段C语言代码,在编译.链接和运行的各个阶段都可能会出现问题.编译器只能检查编译和链接阶段出现的问题,而可执行程序已经脱离了编译器,运行阶段出现问题编译器是无能为力的. 如果我们编写的代码正确,运行时 ...
- PHP基础学习笔记1
一.基本语法 1.1 形式 PHP 脚本以 <?php 开始,以 ?> 结束: <?php //php代码 ?> 1.2 注释 单行注释 //这是单行注释 多行注释 /* 这是 ...
- js实现上移下移
直接上代码 //上移 var $up = $(".up") $up.click(function () { var $tr = $(this).parents("tr&q ...
- 通过WMI获取网卡MAC地址、硬盘序列号、主板序列号、CPU ID、BIOS序列号
转载:https://www.cnblogs.com/tlduck/p/5132738.html #define _WIN32_DCOM #include<iostream> #inclu ...
- oracle错误代码大全(超详细)
本篇文章是对oracle错误代码进行了详细的总结与分析,需要的朋友参考下 ORA-00001: 违反唯一约束条件 (.)ORA-00017: 请求会话以设置跟踪事件ORA-00018: 超出最大会话数 ...
- ASCII码排序 题解
1. while(scanf("%c%c%c%*c",&a,&b,&c)!=EOF) 这里需要注意 输入多组语句 while后面不能加分号: 2.%*c& ...
- 解决linux 运行自动化脚本浏览器无法启动问题
1.前提你的驱动和版本对应无问题时,依旧报未知错误无法启动chrome 解决方法加上两行: options.addArguments("no-sandbox");options.a ...