综合练习: PIVOT、UNPIVOT、GROUPING SETS、GROUPING_ID_1
综合练习: PIVOT、UNPIVOT、GROUPING SETS、GROUPING_ID
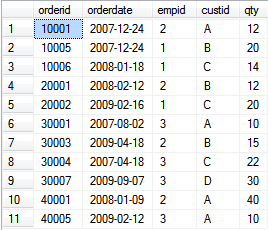
问题1:
Desired output:
empid cnt2007 cnt2008 cnt2009
----------- ----------- ----------- -----------
1 1 1 1
2 1 2 1
3 2 0 2
问题2:
Desired output:
empid orderyear numorders
----------- ----------- -----------
1 2007 1
1 2008 1
1 2009 1
2 2007 1
2 2008 2
2 2009 1
3 2007 2
3 2009 2
问题3:Write a query against the Orders table that returns the total quantities for each:
(employee, customer, and order year),
(employee and order year),
(customer and order year).
Include a result column in the output that uniquely identifies the grouping set with which the current row is associated
Desired output:
groupingset empid custid orderyear sumqty
-------------- ----------- --------- ----------- -----------
0 2 A 2007 12
0 3 A 2007 10
4 NULL A 2007 22
0 2 A 2008 40
4 NULL A 2008 40
0 3 A 2009 10
4 NULL A 2009 10
0 1 B 2007 20
4 NULL B 2007 20
0 2 B 2008 12
4 NULL B 2008 12
0 2 B 2009 15
4 NULL B 2009 15
0 3 C 2007 22
4 NULL C 2007 22
0 1 C 2008 14
4 NULL C 2008 14
0 1 C 2009 20
4 NULL C 2009 20
0 3 D 2009 30
4 NULL D 2009 30
2 1 NULL 2007 20
2 2 NULL 2007 12
2 3 NULL 2007 32
2 1 NULL 2008 14
2 2 NULL 2008 52
2 1 NULL 2009 20
2 2 NULL 2009 15
2 3 NULL 2009 40
f object_id('dbo.orders','U') is not null drop table dbo.orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL,
orderdate DATE NOT NULL,
empid INT NOT NULL,
custid VARCHAR(5) NOT NULL,
qty INT NOT NULL,
CONSTRAINT PK_Orders PRIMARY KEY(orderid)
);
GO
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES
(30001, '', 3, 'A', 10),
(10001, '', 2, 'A', 12),
(10005, '', 1, 'B', 20),
(40001, '', 2, 'A', 40),
(10006, '', 1, 'C', 14),
(20001, '', 2, 'B', 12),
(40005, '', 3, 'A', 10),
(20002, '', 1, 'C', 20),
(30003, '', 2, 'B', 15),
(30004, '', 3, 'C', 22),
/*
《Microsoft SQL Server 2008 T-SQL Fundamentals》
*/
------------------------------------------------------------------
select *
from Orders
------------------------------------------------------------------
--按照empid分组
select empid
from Orders
group by empid
------------------------------------------------------------------
--按YY分组
select datepart(yy,orderdate)
from Orders
group by datepart(yy,orderdate)
------------------------------------------------------------------ ------------------------------------------------------------------
--按empid, orderid,YY分组
select empid, orderid, datepart(yy,orderdate),
count(*)
from Orders
group by empid, orderid, datepart(yy,orderdate)
------------------------------------------------------------------
----按empid, YY分组
select empid, datepart(yy,orderdate) as YY,
count(*) as cnt
from Orders
group by empid, datepart(yy,orderdate)
------------------------------------------------------------------
----按empid, YY分组
select empid, YEAR(orderdate) as YY --, count(*) as cnt
from Orders
------------------------------------------------------------------
--从上面这个步骤,直接得出最后的结果,交叉时之前的子查询不要分组,统计, 还是多熟悉一下pivot,unpivot的语法
select empid, [], [], []
from (
select empid, datepart(yy,orderdate) as YY
from Orders
) as d
pivot(count(YY) for YY in([], [], [])) as p --对于交叉时,一直不想在这里用列举的方法,假使这里的值很多时?
------------------------------------------------------------------
----按empid, YY分组,不需要的思考过程,就向后缩进
--select empid, -- datepart(yy,orderdate),
-- (case when datepart(yy,orderdate)='2007' then count(*) end) AS cnt2007,
-- (case when datepart(yy,orderdate)='2008' then count(*) end) AS cnt2008,
-- (case when datepart(yy,orderdate)='2009' then count(*) end) AS cnt2009
--from Orders
--group by empid, datepart(yy,orderdate)
------------------------------------------------------------------
----按empid,这就是最后的结果,虽然是最后的结果,是以订单数量的次数在相加
select empid, -- datepart(yy,orderdate),
count(case when datepart(yy,orderdate)='' then qty end) AS cnt2007,
count(case when datepart(yy,orderdate)='' then qty end) AS cnt2008,
count(case when datepart(yy,orderdate)='' then qty end) AS cnt2009
from Orders
group by empid
------------------------------------------------------------------
----按empid,这就是最后的结果,以出现的 “年” 相同的次数在相加
select empid, -- datepart(yy,orderdate),
count(case when year(orderdate)='' then year(orderdate) end) AS cnt2007,
count(case when year(orderdate)='' then year(orderdate) end) AS cnt2008,
count(case when year(orderdate)='' then year(orderdate) end) AS cnt2009
from Orders
group by empid
------------------------------------------------------------------
--将查询的结果集,插入到另外一个表中去,目的是什么? ---看这么查询得出这么整齐的结果,当然是想训练UNPIVOT
IF OBJECT_ID('dbo.EmpYearOrders', 'U') IS NOT NULL DROP TABLE dbo.EmpYearOrders; SELECT empid, [] AS cnt2007, [] AS cnt2008, [] AS cnt2009
INTO dbo.EmpYearOrders
FROM (SELECT empid, YEAR(orderdate) AS orderyear
FROM dbo.Orders) AS D
PIVOT(COUNT(orderyear)
FOR orderyear IN([], [], [])) AS P; SELECT * FROM dbo.EmpYearOrders;
empid cnt2007 cnt2008 cnt2009
----------- ----------- ----------- -----------
1 1 1 1
2 1 2 1
3 2 0 2
------------------------------------------------------------------
--将上面这个结果,转化为下面的,打散开
empid orderyear numorders
----------- ----------- -----------
1 2007 1
1 2008 1
1 2009 1
2 2007 1
2 2008 2
2 2009 1
3 2007 2
3 2009 2 SELECT empid, orderyear, numorders
FROM dbo.EmpYearOrders
UNPIVOT(numorders
for orderyear in(cnt2007, cnt2008,cnt2009)) AS U
where numorders <> 0
------------------------------------------------------------------ ------------------------------------------------------------------
--
--select * from Orders
select grouping(empid) as groupingset, empid, custid, year(orderdate) as orderyear, sum(qty) as sumqty
from Orders
group by
grouping sets(
(empid, custid, year(orderdate)),
(empid, year(orderdate)),
(custid, year(orderdate)) --如果分组包含(),则结果集中将会计算总的数量(sumqty = 205)
)
------------------------------------------------------------------
-- Write a query against the Orders table that returns the total quantities for each:
-- (employee, customer, and order year), (employee and order year), (customer and order year).
-- Include a result column in the output that uniquely identifies the grouping set with which the current row is associated.
-- 用GROUPING_ID函数为与每一行相关联的分组集生成唯一的标识符
select grouping_id(empid,custid,year(orderdate)) as groupingset, empid, custid, year(orderdate) as orderyear, sum(qty) as sumqty
from Orders
group by
grouping sets(
(empid, custid, year(orderdate)),
(empid, year(orderdate)),
(custid, year(orderdate))
)
感悟:也许国内出书都是以结果为导向,或者为升职、或者为名,反正出的书、或者翻译的书籍,即使自己懂、理解、或没完全理解透彻,翻译出来的书籍都不是那么理想的,
并不是在否定他们的劳动成果,你出书,面向哪个级别的书籍,就应该针对哪个级别要进行理解性的讲解。
综合练习: PIVOT、UNPIVOT、GROUPING SETS、GROUPING_ID_1的更多相关文章
- TSQL 分组集(Grouping Sets)
分组集(Grouping Sets)是多个分组的并集,用于在一个查询中,按照不同的分组列对集合进行聚合运算,等价于对单个分组使用“union all”,计算多个结果集的并集.使用分组集的聚合查询,返回 ...
- SQL Server中行列转换 Pivot UnPivot
SQL Server中行列转换 Pivot UnPivot PIVOT用于将列值旋转为列名(即行转列),在SQL Server 2000可以用聚合函数配合CASE语句实现 PIVOT的一般语法是:PI ...
- grouping sets从属子句的运用
grouping sets主要是用来合并多个分组的结果. 对于员工目标业绩表'businessTarget': employeeId targetDate idealDistAmount 如果需要分别 ...
- 【转】rollup、cub、grouping sets、grouping、grouping_id在报表中的应用
摘自 http://blog.itpub.net/26977915/viewspace-734114/ 在报表语句中经常要使用各种分组汇总,rollup和cube就是常用的分组汇总方式. 第一:gro ...
- 转:GROUPING SETS、ROLLUP、CUBE
转:http://blog.csdn.net/shangboerds/article/details/5193211 大家对GROUP BY应该比较熟悉,如果你感觉自己并不完全理解GROUP BY,那 ...
- SQL Server 之 GROUP BY、GROUPING SETS、ROLLUP、CUBE
1.创建表 Staff CREATE TABLE [dbo].[Staff]( ,) NOT NULL, ) NULL, ) NULL, ) NULL, [Money] [int] NULL, [Cr ...
- hive中grouping sets的使用
hive中grouping sets 数量较多时如何处理? 可以使用如下设置来 set hive.new.job.grouping.set.cardinality = 30; 这条设置的意义在于 ...
- Grouping Sets:CUBE和ROLLUP从句
在上一篇文章里我讨论了SQL Server里Grouping Sets的功能.从文中的例子可以看到,通过简单定义需要的分组集是很容易进行各自分组.但如果像从所给的列集里想要有所有可能的分布——即所谓的 ...
- SQL Server里Grouping Sets的威力
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务).我不是说在生产里使用开发版,也不是说安装盗版SQL Server. 不可能的任务 ...
随机推荐
- 王艳 201771010127《面向对象程序设计(java)》第七周学习总结
1.实验目的与要求 (1)进一步理解4个成员访问权限修饰符的用途: (2)掌握Object类的常用API用法: (3)掌握ArrayList类用法与常用API: (4)掌握枚举类使用方法: (5)结合 ...
- HDU6097 Mindis
题目链接:https://cn.vjudge.net/problem/HDU-6097 知识点: 计算几何.圆的反演 题目大意: 已知一个圆心在原点的圆的半径,再给定 \(P, Q\) 两点坐标( \ ...
- java class 字节码
java class 字节码 协议: class文件 魔数(Magic):4byte -> 0xCAFEBABE 类似2f3f 版本(Version):4Byte -> 0x0000003 ...
- SpringBoot外部化配置使用Plus版
本文如有任何纰漏.错误,请不吝指正! PS: 之前写过一篇关于SpringBoo中使用配置文件的一些姿势,不过嘛,有句话(我)说的好:曾见小桥流水,未睹观音坐莲!所以再写一篇增强版,以便记录. 序言 ...
- git简单的使用步骤
Git介绍 Git是分布式版本控制系统 集中式VS分布式,SVN VS Git 1)SVN和Git主要的区别在于历史版本维护的位置 2)这两个工具主要的区别在于历史版本维护的位置Git本地仓库包含代码 ...
- windows环境下Kubernetes及Docker安装(那些坑)
k8s 和 Docker容器技术,当前非常流行的技术. 让人日狗的是, 这套技术栈对CN的donet 程序员不怎么友好.娓娓道来,1. 好多镜像都是需要梯子才能访问: 2. window程序员天生 ...
- Jmeter(四) - 从入门到精通 - 创建网络测试计划(详解教程)
1.简介 在本节中,您将学习如何创建基本的 测试计划来测试网站.您将创建五个用户,这些用户将请求发送到JMeter网站上的两个页面.另外,您将告诉用户两次运行测试.因此,请求总数为(5个用户)x(2个 ...
- 上传应用至Google Play 后被重新签名,怎么获取最新的签名信息
基本签名信息在Google Play 上都能查看到. 快速解决Google+登录和facebook登录的办法: 不用改包名重新创建应用,不用重新打包,不要删除自己的keystore文件,不要重新创建k ...
- 认证(Authentication)和授权(Authorization)总结
身份认证是验证你的身份,一旦通过验证,即启用授权.你所拥有的身份可以进行哪些操作都是由授权规定.例如,任何银行客户都可以创建一个账户(如用户名),并使用该账户登录该银行的网上服务,但银行的授权政策必须 ...
- SpringBoot实现微信小程序登录的完整例子
目录 一.登录流程 二.后端实现 1.SpringBoot项目结构树 2.实现auth.code2Session 接口的封装 3.建立用户信息表及用户增删改查的管理 4.实现登录认证及令牌生成 三.前 ...