综合练习: PIVOT、UNPIVOT、GROUPING SETS、GROUPING_ID_1
综合练习: PIVOT、UNPIVOT、GROUPING SETS、GROUPING_ID
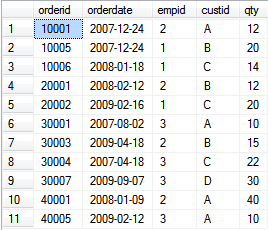
问题1:
Desired output:
empid cnt2007 cnt2008 cnt2009
----------- ----------- ----------- -----------
1 1 1 1
2 1 2 1
3 2 0 2
问题2:
Desired output:
empid orderyear numorders
----------- ----------- -----------
1 2007 1
1 2008 1
1 2009 1
2 2007 1
2 2008 2
2 2009 1
3 2007 2
3 2009 2
问题3:Write a query against the Orders table that returns the total quantities for each:
(employee, customer, and order year),
(employee and order year),
(customer and order year).
Include a result column in the output that uniquely identifies the grouping set with which the current row is associated
Desired output:
groupingset empid custid orderyear sumqty
-------------- ----------- --------- ----------- -----------
0 2 A 2007 12
0 3 A 2007 10
4 NULL A 2007 22
0 2 A 2008 40
4 NULL A 2008 40
0 3 A 2009 10
4 NULL A 2009 10
0 1 B 2007 20
4 NULL B 2007 20
0 2 B 2008 12
4 NULL B 2008 12
0 2 B 2009 15
4 NULL B 2009 15
0 3 C 2007 22
4 NULL C 2007 22
0 1 C 2008 14
4 NULL C 2008 14
0 1 C 2009 20
4 NULL C 2009 20
0 3 D 2009 30
4 NULL D 2009 30
2 1 NULL 2007 20
2 2 NULL 2007 12
2 3 NULL 2007 32
2 1 NULL 2008 14
2 2 NULL 2008 52
2 1 NULL 2009 20
2 2 NULL 2009 15
2 3 NULL 2009 40
f object_id('dbo.orders','U') is not null drop table dbo.orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL,
orderdate DATE NOT NULL,
empid INT NOT NULL,
custid VARCHAR(5) NOT NULL,
qty INT NOT NULL,
CONSTRAINT PK_Orders PRIMARY KEY(orderid)
);
GO
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES
(30001, '', 3, 'A', 10),
(10001, '', 2, 'A', 12),
(10005, '', 1, 'B', 20),
(40001, '', 2, 'A', 40),
(10006, '', 1, 'C', 14),
(20001, '', 2, 'B', 12),
(40005, '', 3, 'A', 10),
(20002, '', 1, 'C', 20),
(30003, '', 2, 'B', 15),
(30004, '', 3, 'C', 22),
/*
《Microsoft SQL Server 2008 T-SQL Fundamentals》
*/
------------------------------------------------------------------
select *
from Orders
------------------------------------------------------------------
--按照empid分组
select empid
from Orders
group by empid
------------------------------------------------------------------
--按YY分组
select datepart(yy,orderdate)
from Orders
group by datepart(yy,orderdate)
------------------------------------------------------------------ ------------------------------------------------------------------
--按empid, orderid,YY分组
select empid, orderid, datepart(yy,orderdate),
count(*)
from Orders
group by empid, orderid, datepart(yy,orderdate)
------------------------------------------------------------------
----按empid, YY分组
select empid, datepart(yy,orderdate) as YY,
count(*) as cnt
from Orders
group by empid, datepart(yy,orderdate)
------------------------------------------------------------------
----按empid, YY分组
select empid, YEAR(orderdate) as YY --, count(*) as cnt
from Orders
------------------------------------------------------------------
--从上面这个步骤,直接得出最后的结果,交叉时之前的子查询不要分组,统计, 还是多熟悉一下pivot,unpivot的语法
select empid, [], [], []
from (
select empid, datepart(yy,orderdate) as YY
from Orders
) as d
pivot(count(YY) for YY in([], [], [])) as p --对于交叉时,一直不想在这里用列举的方法,假使这里的值很多时?
------------------------------------------------------------------
----按empid, YY分组,不需要的思考过程,就向后缩进
--select empid, -- datepart(yy,orderdate),
-- (case when datepart(yy,orderdate)='2007' then count(*) end) AS cnt2007,
-- (case when datepart(yy,orderdate)='2008' then count(*) end) AS cnt2008,
-- (case when datepart(yy,orderdate)='2009' then count(*) end) AS cnt2009
--from Orders
--group by empid, datepart(yy,orderdate)
------------------------------------------------------------------
----按empid,这就是最后的结果,虽然是最后的结果,是以订单数量的次数在相加
select empid, -- datepart(yy,orderdate),
count(case when datepart(yy,orderdate)='' then qty end) AS cnt2007,
count(case when datepart(yy,orderdate)='' then qty end) AS cnt2008,
count(case when datepart(yy,orderdate)='' then qty end) AS cnt2009
from Orders
group by empid
------------------------------------------------------------------
----按empid,这就是最后的结果,以出现的 “年” 相同的次数在相加
select empid, -- datepart(yy,orderdate),
count(case when year(orderdate)='' then year(orderdate) end) AS cnt2007,
count(case when year(orderdate)='' then year(orderdate) end) AS cnt2008,
count(case when year(orderdate)='' then year(orderdate) end) AS cnt2009
from Orders
group by empid
------------------------------------------------------------------
--将查询的结果集,插入到另外一个表中去,目的是什么? ---看这么查询得出这么整齐的结果,当然是想训练UNPIVOT
IF OBJECT_ID('dbo.EmpYearOrders', 'U') IS NOT NULL DROP TABLE dbo.EmpYearOrders; SELECT empid, [] AS cnt2007, [] AS cnt2008, [] AS cnt2009
INTO dbo.EmpYearOrders
FROM (SELECT empid, YEAR(orderdate) AS orderyear
FROM dbo.Orders) AS D
PIVOT(COUNT(orderyear)
FOR orderyear IN([], [], [])) AS P; SELECT * FROM dbo.EmpYearOrders;
empid cnt2007 cnt2008 cnt2009
----------- ----------- ----------- -----------
1 1 1 1
2 1 2 1
3 2 0 2
------------------------------------------------------------------
--将上面这个结果,转化为下面的,打散开
empid orderyear numorders
----------- ----------- -----------
1 2007 1
1 2008 1
1 2009 1
2 2007 1
2 2008 2
2 2009 1
3 2007 2
3 2009 2 SELECT empid, orderyear, numorders
FROM dbo.EmpYearOrders
UNPIVOT(numorders
for orderyear in(cnt2007, cnt2008,cnt2009)) AS U
where numorders <> 0
------------------------------------------------------------------ ------------------------------------------------------------------
--
--select * from Orders
select grouping(empid) as groupingset, empid, custid, year(orderdate) as orderyear, sum(qty) as sumqty
from Orders
group by
grouping sets(
(empid, custid, year(orderdate)),
(empid, year(orderdate)),
(custid, year(orderdate)) --如果分组包含(),则结果集中将会计算总的数量(sumqty = 205)
)
------------------------------------------------------------------
-- Write a query against the Orders table that returns the total quantities for each:
-- (employee, customer, and order year), (employee and order year), (customer and order year).
-- Include a result column in the output that uniquely identifies the grouping set with which the current row is associated.
-- 用GROUPING_ID函数为与每一行相关联的分组集生成唯一的标识符
select grouping_id(empid,custid,year(orderdate)) as groupingset, empid, custid, year(orderdate) as orderyear, sum(qty) as sumqty
from Orders
group by
grouping sets(
(empid, custid, year(orderdate)),
(empid, year(orderdate)),
(custid, year(orderdate))
)
感悟:也许国内出书都是以结果为导向,或者为升职、或者为名,反正出的书、或者翻译的书籍,即使自己懂、理解、或没完全理解透彻,翻译出来的书籍都不是那么理想的,
并不是在否定他们的劳动成果,你出书,面向哪个级别的书籍,就应该针对哪个级别要进行理解性的讲解。
综合练习: PIVOT、UNPIVOT、GROUPING SETS、GROUPING_ID_1的更多相关文章
- TSQL 分组集(Grouping Sets)
分组集(Grouping Sets)是多个分组的并集,用于在一个查询中,按照不同的分组列对集合进行聚合运算,等价于对单个分组使用“union all”,计算多个结果集的并集.使用分组集的聚合查询,返回 ...
- SQL Server中行列转换 Pivot UnPivot
SQL Server中行列转换 Pivot UnPivot PIVOT用于将列值旋转为列名(即行转列),在SQL Server 2000可以用聚合函数配合CASE语句实现 PIVOT的一般语法是:PI ...
- grouping sets从属子句的运用
grouping sets主要是用来合并多个分组的结果. 对于员工目标业绩表'businessTarget': employeeId targetDate idealDistAmount 如果需要分别 ...
- 【转】rollup、cub、grouping sets、grouping、grouping_id在报表中的应用
摘自 http://blog.itpub.net/26977915/viewspace-734114/ 在报表语句中经常要使用各种分组汇总,rollup和cube就是常用的分组汇总方式. 第一:gro ...
- 转:GROUPING SETS、ROLLUP、CUBE
转:http://blog.csdn.net/shangboerds/article/details/5193211 大家对GROUP BY应该比较熟悉,如果你感觉自己并不完全理解GROUP BY,那 ...
- SQL Server 之 GROUP BY、GROUPING SETS、ROLLUP、CUBE
1.创建表 Staff CREATE TABLE [dbo].[Staff]( ,) NOT NULL, ) NULL, ) NULL, ) NULL, [Money] [int] NULL, [Cr ...
- hive中grouping sets的使用
hive中grouping sets 数量较多时如何处理? 可以使用如下设置来 set hive.new.job.grouping.set.cardinality = 30; 这条设置的意义在于 ...
- Grouping Sets:CUBE和ROLLUP从句
在上一篇文章里我讨论了SQL Server里Grouping Sets的功能.从文中的例子可以看到,通过简单定义需要的分组集是很容易进行各自分组.但如果像从所给的列集里想要有所有可能的分布——即所谓的 ...
- SQL Server里Grouping Sets的威力
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务).我不是说在生产里使用开发版,也不是说安装盗版SQL Server. 不可能的任务 ...
随机推荐
- Ubuntu下配置Hyperledger Fabric环境
在win10系统的台式机上安装配置Hyperledger Fabric环境 安装Ubuntu 16.04 双系统 镜像下载地址:https://www.ubuntu.com/download/desk ...
- JavaScript Basic
Exercise-1 Write a JavaScript program to display the current day and time in the following format. T ...
- sql语句中的删除操作
drop: drop table tb; 删除内容和定义,释放空间.简单来说就是把整个表去掉.以后不能再新增数据,除非新增一个表. truncate: truncate table tb; 删除内容. ...
- java内部类简单用法
package innerClass; /** * 特点 * 1:增强封装性,通过把内部类隐藏在外部类的里面,使得其他类不能访问外部类. * 2:增强可维护性. * 3:内部类可以访问外部的成员. * ...
- 图解MySQL索引(二)—为什么使用B+Tree
失踪人口回归,近期换工作一波三折,耽误了不少时间,从今开始每周更新~ 索引是一种支持快速查询的数据结构,同时索引优化也是后端工程师的必会知识点.各个公司都有所谓的MySQL"军规" ...
- 07 . Nginx常用模块及案例
访问控制 用户访问控制 ngx_http_auth_basic_module 有时我们会有这么一种需求,就是你的网站并不想提供一个公共的访问或者某些页面不希望公开,我们希望的是某些特定的客户端可以访问 ...
- SRAM电路工作原理
近年来,片上存储器发展迅速,根据国际半导体技术路线图(ITRS),随着超深亚微米制造工艺的成熟和纳米工艺的发展,晶体管特征尺寸进一步缩小,半导体存储器在片上存储器上所占的面积比例也越来越高.接下来宇芯 ...
- Kubernetes笔记(四):详解Namespace与资源限制ResourceQuota,LimitRange
前面我们对K8s的基本组件与概念有了个大致的印象,并且基于K8s实现了一个初步的CI/CD流程,但对里面涉及的各个对象(如Namespace, Pod, Deployment, Service, In ...
- 解锁网络编程之NIO的前世今生
个人博客网:https://wushaopei.github.io/ (你想要这里多有) NIO 内容概览: NIO 网络编程模型 NIO 网络编程详解 NIO 网络编程实战 NIO 网络编程缺 ...
- Java实现 LeetCode 377 组合总和 Ⅳ
377. 组合总和 Ⅳ 给定一个由正整数组成且不存在重复数字的数组,找出和为给定目标正整数的组合的个数. 示例: nums = [1, 2, 3] target = 4 所有可能的组合为: (1, 1 ...