CTR预估模型演变及学习笔记
【说在前面】本人博客新手一枚,象牙塔的老白,职业场的小白。以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手]
【再啰嗦一下】如果你对智能推荐感兴趣,欢迎先浏览我的另一篇随笔:智能推荐算法演变及学习笔记
【最后再说一下】本文只对智能推荐算法中的CTR预估模型演变进行具体介绍!
一、传统CTR预估模型演变
1. LR
即逻辑回归。LR模型先求得各特征的加权和,再添加sigmoid函数。
- 使用各特征的加权和,是为了考虑不同特征的重要程度
- 使用sigmoid函数,是为了将值映射到 [0, 1] 区间
LR模型的优点在于:
- 易于并行化、模型简单、训练开销小
- 可解释性强、可拓展性强
LR模型的缺点在于:
- 只使用单一特征,无法利用高维信息,表达能力有限
- 特征工程需要耗费大量的精力
2. POLY2
POLY2对所有特征进行“暴力”组合(即两两交叉),并对所有的特征组合赋予了权重。
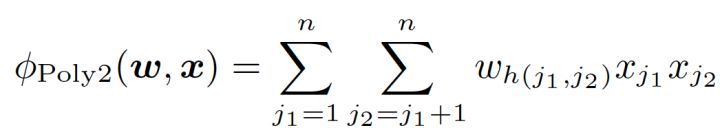
一定程度上解决了LR缺乏特征组合的问题,但是“暴力行为”带来了一些问题:
- 特征维度爆炸,特征数据过于稀疏,特征权重不易收敛
3. FM
相比于POLY2,FM为每个特征学习了一个隐权重向量 w。在特征交叉时,使用两个特征隐向量w的内积作为交叉特征的权重。

将原先n^2级别的权重数量降低到n*k(k为隐向量w的维度,n>>k),极大降低了训练开销。
4. FFM
在FM模型基础上,FFM模型引入了Field-aware。在特征交叉时,使用特征在对方特征域上的隐向量内积作为交叉特征的权重。
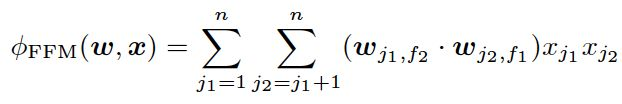
FFM模型的权重数量共n*k*f个,计算复杂度上升到k*n^2,远远大于FM模型的k*n。
5. GBDT/xgboost/lightgbm
直接使用机器学习算法中的集成学习方法。
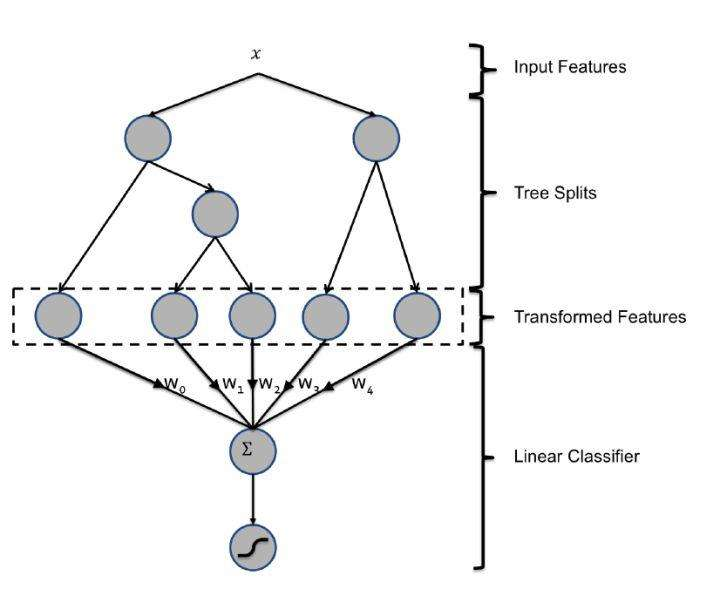
6. GBDT+LR/FM/FFM
利用GBDT自动进行特征筛选和组合,进而生成新的离散特征向量,再把该特征向量当作LR模型的输入。
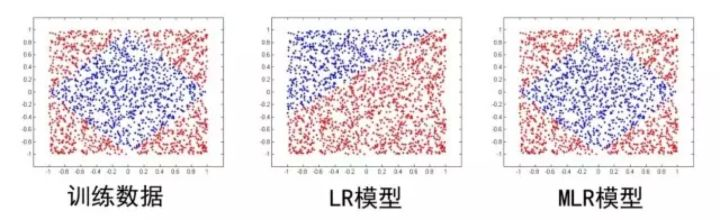
7. MLR
在LR的基础上采用分而治之的思路,先对样本进行分片,再在样本分片中应用LR进行CTR预估。
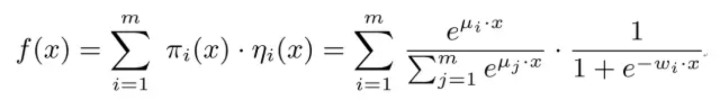
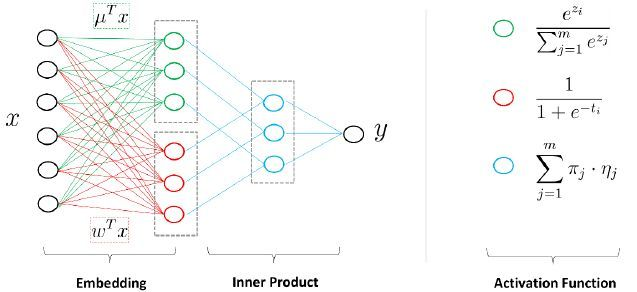
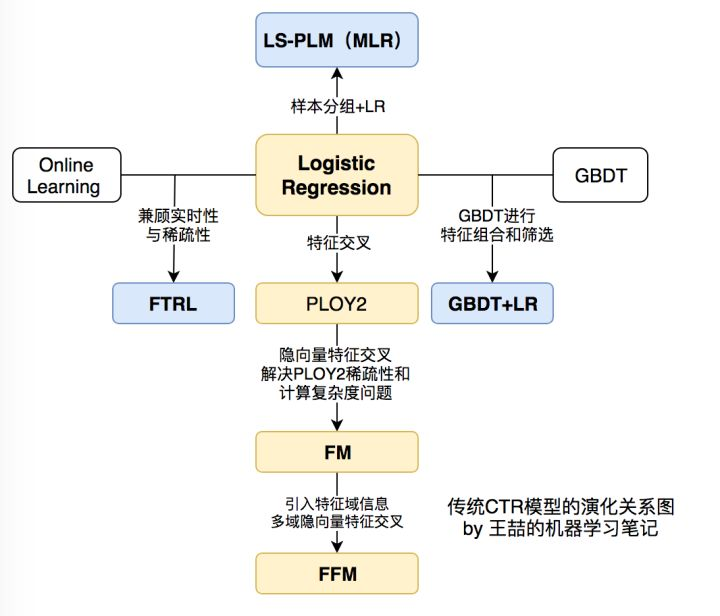
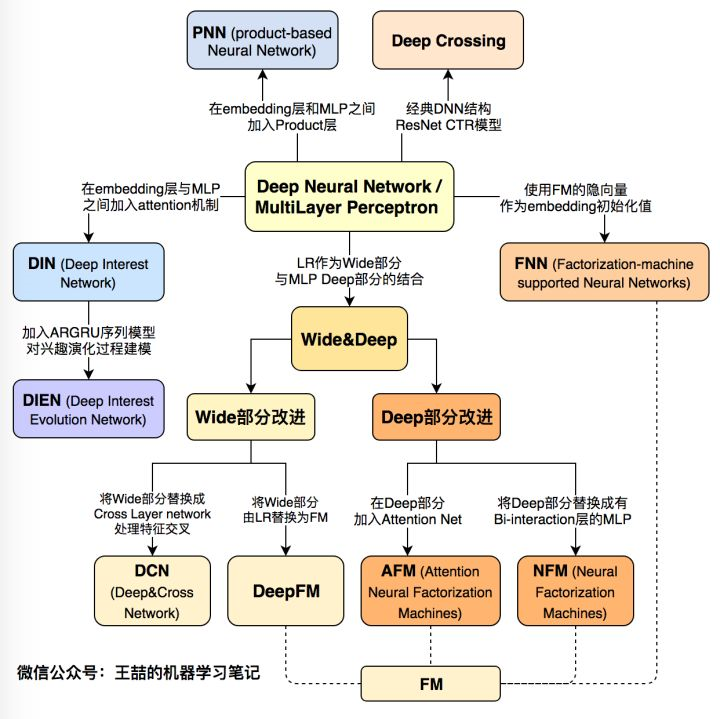
以上1-7部分可以总结为传统的CTR预估模型演变,这里分享一下大佬的关系图谱:
二、引入深度学习的CTR预估模型演变
1. Deep Crossing
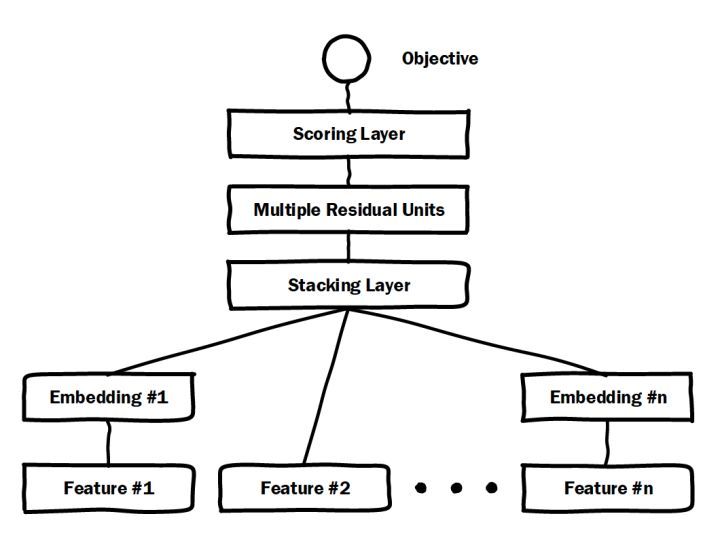
通过加入embedding层将稀疏特征转化为低维稠密特征,用stacking层连接分段的特征向量,再通过多层神经网络完成特征组合/转换。
跟经典DNN有所不同的是,Deep crossing采用的multilayer perceptron是由残差网络组成的。
2. FNN
相比于Deep Crossing,FNN使用FM的隐层向量作为user和item的Embedding,从而避免了完全从随机状态训练Embedding。
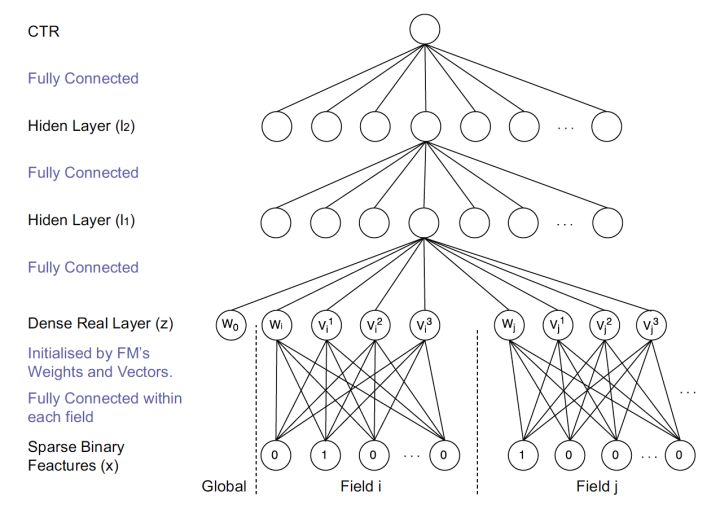
3. Wide & Deep
把单输入层的Wide部分和经过多层感知机的Deep部分连接起来,一起输入最终的输出层。
- wide部分:高维特征+特征组合的LR
- deep部分:deep learning
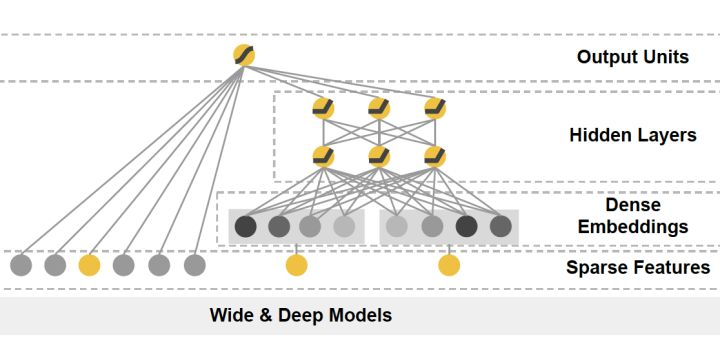
4. DeepFM
DeepFM对Wide & Deep的改进之处在于,用FM替换掉了原来的Wide部分,加强了浅层网络部分特征组合的能力。
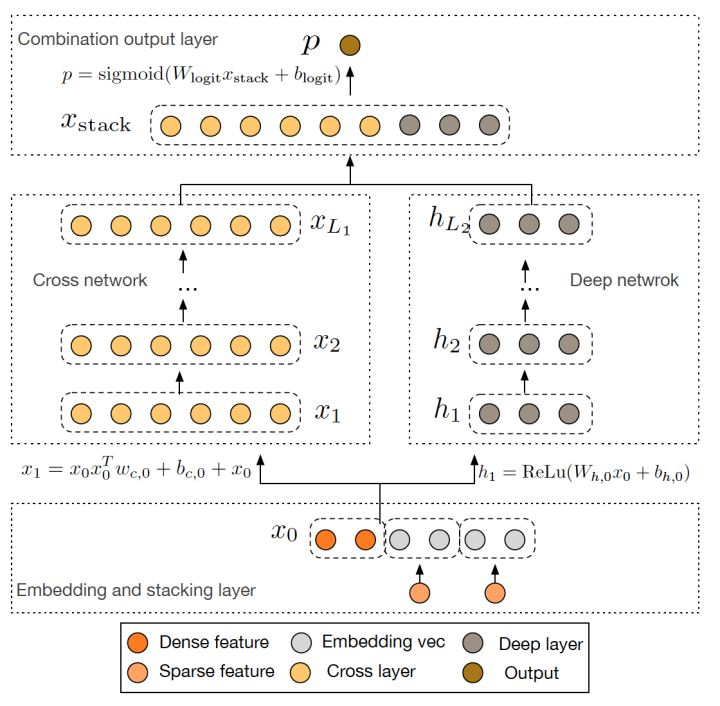
5. Deep & Cross (DCN)
使用Cross网络替代了原来的Wide部分。Cross网络使用多层cross layer对输入向量进行特征交叉,增加特征之间的交互。
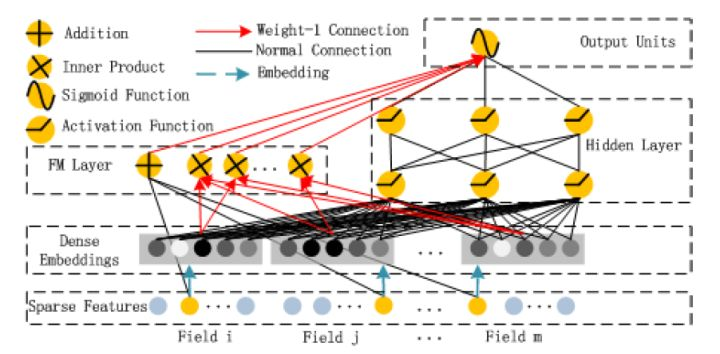
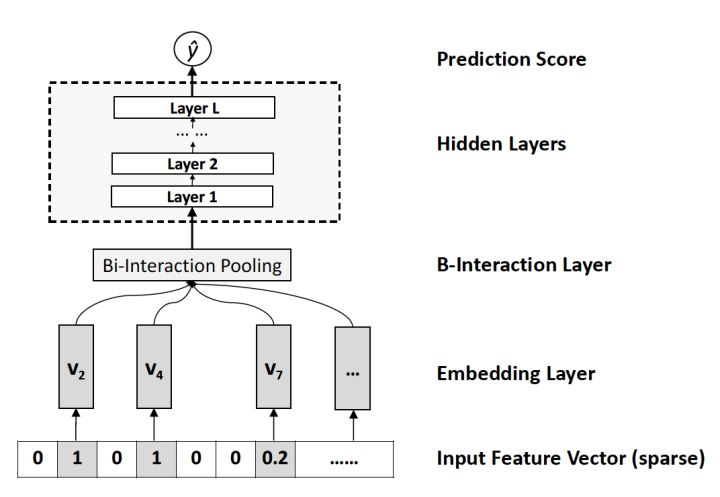
6. NFM
相对于DeepFM和DCN对于Wide&Deep Wide部分的改进,NFM可以看作是对Deep部分的改进。
NFM用一个带Bi-interaction Pooling层的DNN替换了FM的特征交叉部分。
7. Deep Interest Network (DIN)
在模型的embedding layer和concatenate layer之间加入了attention unit,使模型能够根据候选商品的不同,调整不同特征的权重。

以上1-7部分可以总结为引入深度学习的CTR预估模型演变,这里分享一下大佬的关系图谱:
三、深度学习推荐模型的上线问题
对于深度学习推荐模型的离线训练自然不是问题,一般可以采用比较成熟的离线并行训练环境。
对于深度学习推荐模型的上线问题,其线上时效性至关重要。
1. “特征实时性”
这里分享一下大佬画的智能推荐系统主流技术架构图,博主认知有限,就不展开介绍了。

2. “模型实时性”
与“特征实时性”相比,推荐系统模型的实时性往往是从更全局的角度考虑问题,博主认知有限,就不展开介绍了。
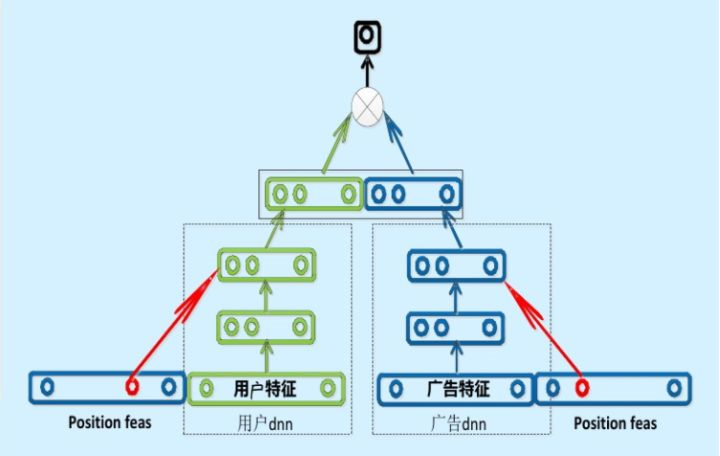
3. “服务实时性”:双塔模型
很多公司采用“复杂网络离线训练,生成embedding存入内存数据库,线上实现LR或浅层NN等轻量级模型拟合优化目标”的上线方式。
以百度的双塔模型举例说明:
(1)分别用复杂网络对“用户特征”和“广告特征”进行embedding,这就形成了两个独立的“塔”,因此称为双塔模型。
(2)在完成双塔模型的训练后,可以把最终的用户embedding和广告embedding存入内存数据库。
(3)线上推理时,只需要实现最后一层的逻辑,从内存数据库中取出用户/广告的embedding,通过简单计算即可得到预估结果。
最后感叹一句,深度学习CTR模型的发展实在是太迅速了,要保持学习啊!
本文参考了大佬的知乎专栏:https://zhuanlan.zhihu.com/p/51117616
如果你对智能推荐感兴趣,欢迎先浏览我的另一篇随笔:智能推荐算法演变及学习笔记
如果您对数据挖掘感兴趣,欢迎浏览我的另一篇博客:数据挖掘比赛/项目全流程介绍
如果您对人工智能算法感兴趣,欢迎浏览我的另一篇博客:人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)
如果你是计算机专业的应届毕业生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的应届生,你如何准备求职面试?
如果你是计算机专业的本科生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的本科生,你可以选择学习什么?
如果你是计算机专业的研究生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的研究生,你可以选择学习什么?
如果你对金融科技感兴趣,欢迎浏览我的另一篇博客:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之后博主将持续分享各大算法的学习思路和学习笔记:hello world: 我的博客写作思路
CTR预估模型演变及学习笔记的更多相关文章
- 人工智能中小样本问题相关的系列模型演变及学习笔记(二):生成对抗网络 GAN
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手] [再啰嗦一下]本文衔接上一个随笔:人工智能中小样本问题相关的系列模型演变及学习 ...
- 深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图] [补充说明]深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻 ...
- 主流CTR预估模型的演化及对比
https://zhuanlan.zhihu.com/p/35465875 学习和预测用户的反馈对于个性化推荐.信息检索和在线广告等领域都有着极其重要的作用.在这些领域,用户的反馈行为包括点击.收藏. ...
- 闲聊DNN CTR预估模型
原文:http://www.52cs.org/?p=1046 闲聊DNN CTR预估模型 Written by b manongb 作者:Kintocai, 北京大学硕士, 现就职于腾讯. 伦敦大学张 ...
- 深度CTR预估模型中的特征自动组合机制演化简史 zz
众所周知,深度学习在计算机视觉.语音识别.自然语言处理等领域最先取得突破并成为主流方法.但是,深度学习为什么是在这些领域而不是其他领域最先成功呢?我想一个原因就是图像.语音.文本数据在空间和时间上具有 ...
- 【转】- 从FM推演各深度CTR预估模型(附代码)
从FM推演各深度CTR预估模型(附代码) 2018年07月13日 15:04:34 阅读数:584 作者: 龙心尘 && 寒小阳 时间:2018年7月 出处: 龙心尘 寒小阳
- PaddlePaddle分布式训练及CTR预估模型应用
前言:我在github上创建了一个新的repo:PaddleAI, 准备用Paddle做的一系列有趣又实用的案例,所有的案例都会上传数据代码和预训练模型,下载后可以在30s内上手,跑demo出结果,让 ...
- 基于.net的分布式系统限流组件 C# DataGridView绑定List对象时,利用BindingList来实现增删查改 .net中ThreadPool与Task的认识总结 C# 排序技术研究与对比 基于.net的通用内存缓存模型组件 Scala学习笔记:重要语法特性
基于.net的分布式系统限流组件 在互联网应用中,流量洪峰是常有的事情.在应对流量洪峰时,通用的处理模式一般有排队.限流,这样可以非常直接有效的保护系统,防止系统被打爆.另外,通过限流技术手段,可 ...
- 几句话总结一个算法之CTR预估模型
背景 假设现在有个商品点击预测的任务,有用户端特征性别.年龄.消费力等,商品侧特征价格.销量等,样本为0或者1,现在对特征进行one hot encode,如性别特征用二维表示,男为[1,0],女为[ ...
随机推荐
- L2 Softmax与分类模型
softmax和分类模型 内容包含: softmax回归的基本概念 如何获取Fashion-MNIST数据集和读取数据 softmax回归模型的从零开始实现,实现一个对Fashion-MNIST训练集 ...
- CodeForces - 855B ring 前缀和
邓布利多教授正在帮助哈利摧毁魂器.当他怀疑一个魂器出现在那里时,他去了冈特沙克.他看到Marvolo Gaunt的戒指,并将其确定为魂器.虽然他摧毁了它,但仍然受到诅咒的影响.斯内普教授正在帮助邓布利 ...
- PHP出现SSL certificate:unable to get local issuer certificate的解决办法
当本地curl需要访问https时,如果没有配置证书,会出现SSL certificate: unable to get local issuer certificate错误信息. 解决办法: 1.下 ...
- 谈谈MySQL的索引
目录 索引 前言 是什么 B树 B+树 B树和B+树结构上异同 有什么用 怎么用 索引 前言 总所周知,数据库查询是数据库的最主要功能之一.我们都希望查询数据的速度能尽可能的快.而支撑这一快速的背后就 ...
- 编码理解的漫漫长路(Unicode、GBK、ISO)
Ø 那么现在开始康康都有哪些编码方式 1. ASCII
- [一道蓝鲸安全打卡Web分析] 文件上传引发的二次注入
蓝鲸打卡的一个 web 文件上传引发二次注入的题解和思考 蓝鲸文件管理系统 源代码地址:http://www.whaledu.com/course/290/task/2848/show 首先在设置文件 ...
- 这份Mybatis总结,我觉得你很需要!
前言 只有光头才能变强. 文本已收录至我的GitHub精选文章,欢迎Star:https://github.com/ZhongFuCheng3y/3y Mybatis应该是国内用得最多的「数据访问层」 ...
- MVC-过滤器-Action
四个方法执行顺序是OnActionExecuting——>OnActionExecuted——>OnResultExecuting——>OnResultExecuted. demo代 ...
- JasperReports入门教程(三):Paramters,Fields和Detail基本组件介绍
JasperReports入门教程(三):Paramter,Field和Detail基本组件介绍 前言 前两篇博客带领大家进行了入门,做出了第一个例子.也解决了中文打印的问题.大家跟着例子也做出了de ...
- MySQL之慢日志记录、分页
1.慢日志记录 slow_query_log = OFF #是否开启慢日志记录 long_query_time = 2 #时间限制,超过此时间,则记录 slow_query_log_file = C: ...