Hive(10)-文件存储格式
Hive支持的存储数据的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET
一. 列式存储和行式存储
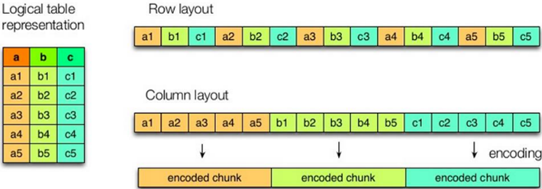
左边为逻辑表,右边第一个为行式存储,第二个为列式存储
1. 行式存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
2.列式存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
二. TextFile格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
三. Orc格式
Orc (Optimized Row Columnar)是Hive 0.11版里引入的新的存储格式。
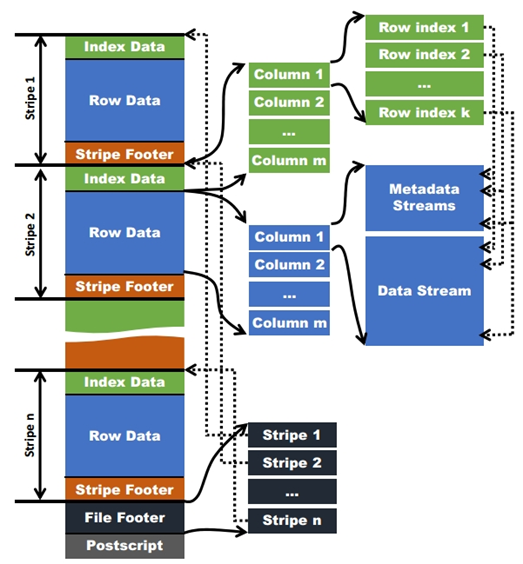
每个Orc文件由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer.
1)Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset。
2)Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
3)Stripe Footer:存的是各个Stream的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
四. Parquet格式
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
1) 行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
2) 列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
3) 页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
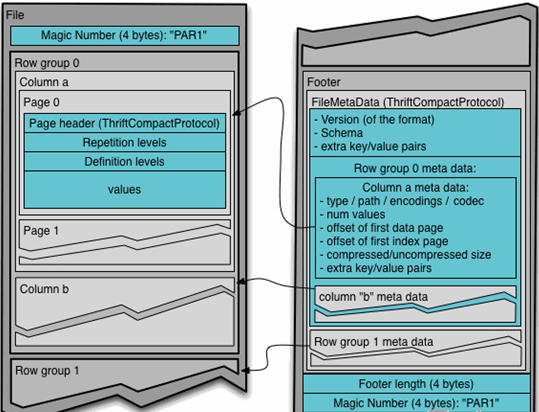
一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
Hive(10)-文件存储格式的更多相关文章
- 大数据:Hive - ORC 文件存储格式
一.ORC File文件结构 ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache ...
- Hive - ORC 文件存储格式【转】
一.ORC File文件结构 ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache ...
- 【图解】Hive文件存储格式
摘自:https://blog.csdn.net/xueyao0201/article/details/79103973 引申阅读原理篇: 大数据:Hive - ORC 文件存储格式 大数据:Parq ...
- hive常见的存储格式
Hive常见文件存储格式 背景:列式存储和行式存储 首先来看一下一张表的存储格式: 字段A 字段B 字段C A1 B1 C1 A2 B2 C2 A3 B3 C3 A4 B4 C4 A5 B5 C5 行 ...
- Hive文件存储格式
hive文件存储格式 1.textfile textfile为默认格式 存储方式:行存储 磁盘开销大 数据解析开销大 压缩的text文件 hive无法进行合并和拆分 2.sequencef ...
- Hive文件存储格式和hive数据压缩
一.存储格式行存储和列存储 二.Hive文件存储格式 三.创建语句和压缩 一.存储格式行存储和列存储 行存储可以理解为一条记录存储一行,通过条件能够查询一整行数据. 列存储,以字段聚集存储,可以理解为 ...
- Hive性能调优(一)----文件存储格式及压缩方式选择
合理使用文件存储格式 建表时,尽量使用 orc.parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量. 采用合 ...
- hive从入门到放弃(六)——常用文件存储格式
hive 存储格式有很多,但常用的一般是 TextFile.ORC.Parquet 格式,在我们单位最多的也是这三种 hive 默认的文件存储格式是 TextFile. 除 TextFile 外的其他 ...
- Hive-ORC文件存储格式
ORC文件格式是从Hive-0.11版本开始的.关于ORC文件格式的官方文档,以及基于官方文档的翻译内容这里就不赘述了,有兴趣的可以仔细研究了解一下.本文接下来根据论文<Major Techni ...
随机推荐
- Attribute+Reflection,提高代码重用
这篇文章两个目的,一是开阔设计的思路,二是实例代码可以拿来就用. 设计的思路来源于<Effective c#>第一版Item 24: 优先使用声明式编程而不是命令式编程.特别的地方是,希望 ...
- .net core系列之《.net core中使用MySql以及Dapper》
当我们决定使用.Net Core开发的时候,就放弃使用SqlServer的打算吧.那应该选择哪个数据库呢?一般选择MySql的比较多. 接下来我们来演示在.Net Core中使用MySQL吧. 1.原 ...
- Effective C++(9) 构造函数调用virtual函数会发生什么
问题聚焦: 不要在构造函数和析构函数中调用virtual函数,因为这样的调用不会带来你预想的结果. 让我先来看一下在构造函数里调用一个virtual函数会发生什么结果 Demo class Trans ...
- SQL insert语句中插入带有特殊符号
1.插入数据库字符串中海油单引号,需要转义处理,例如插入“I‘m OK!” SQL语句: INSERT INTO tableTest(FileTXT) VALUES('I''m OK!') 2.如果S ...
- Linux 下LAMP环境搭建_【all】
LAMP = Linux + Apache + Mysql + PHP 0. Linux环境搭建 Linux 系统安装[Redhat] 1.http服务软件分类及企业实战用途介绍 静态程序: Apac ...
- PHP修改图片
这篇是关于修改图片的效果,主要还是用到php中的GD库中的函数,没想到php还有这凶残能力,出乎我的预料. 先看代码upload_image.php,主要是一个上传控件,用来选择图片 <html ...
- ZT Android Debuggerd的分析及使用方法
Android Debuggerd的分析及使用方法 分类: 移动开发 android framework 2012-12-28 12:00 983人阅读 评论(0) 收藏 举报 目录(?)[+] An ...
- 020.2.2 runtime类
基本不用,简单看一下就行了 1.属于单例的一个实例,可以通过getRuntime()获取对象Runtime r = Runtime.getRuntime();r.exec("winmine. ...
- https nginx 设置
https://www.digitalocean.com/community/tutorials/how-to-create-an-ssl-certificate-on-nginx-for-ubunt ...
- 洛谷 P4783 【模板】矩阵求逆
题目分析 模板题. #include <bits/stdc++.h> using namespace std; typedef long long ll; const int mod=1e ...