java程序运行时内存分配详解
java程序运行时内存分配详解
一、 基本概念
每运行一个java程序会产生一个java进程,每个java进程可能包含一个或者多个线程,每一个Java进程对应唯一一个JVM实例,每一个JVM实例唯一对应一个堆,每一个线程有一个自己私有的栈。进程所创建的所有类的实例(也就是对象)或数组(指的是数组的本身,不是引用)都放在堆中,并由该进程所有的线程共享。Java中分配堆内存是自动初始化的,即为一个对象分配内存的时候,会初始化这个对象中变量。虽然Java中所有对象的存储空间都是在堆中分配的,但是这个对象的引用却是在栈中分配,也就是说在建立一个对象时在堆和栈中都分配内存,在堆中分配的内存实际存放这个被创建的对象的本身,而在栈中分配的内存只是存放指向这个堆对象的引用而已。局部变量 new 出来时,在栈空间和堆空间中分配空间,当局部变量生命周期结束后,栈空间立刻被回收,堆空间区域等待GC回收。
具体的概念:JVM的内存可分为3个区:堆(heap)、栈(stack)和方法区(method,也叫静态区):
堆区:
1.存储的全部是对象,每个对象都包含一个与之对应的class的信息(class的目的是得到操作指令) ;
2.jvm只有一个堆区(heap),且被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身和数组本身;
栈区:
1.每个线程包含一个栈区,栈中只保存基础数据类型本身和自定义对象的引用;
2.每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问;
3.栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令);
方法区(静态区):
1.被所有的线程共享,方法区包含所有的class(class是指类的原始代码,要创建一个类的对象,首先要把该类的代码加载到方法区中,并且初始化)和static变量。
2.方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量。
二、实例演示
AppMain.java
public class AppMain //运行时, jvm 把appmain的代码全部都放入方法区
{
public static void main(String[] args) //main 方法本身放入方法区。
{
Sample test1 = new Sample( " 测试1 " ); //test1是引用,所以放到栈区里, Sample是自定义对象应该放到堆里面
Sample test2 = new Sample( " 测试2 " ); test1.printName();
test2.printName();
}
} public class Sample //运行时, jvm 把appmain的信息都放入方法区
{
/** 范例名称 */
private String name; //new Sample实例后, name 引用放入栈区里, name 对应的 String 对象放入堆里 /** 构造方法 */
public Sample(String name)
{
this .name = name;
} /** 输出 */
public void printName() //在没有对象的时候,print方法跟随sample类被放入方法区里。
{
System.out.println(name);
}
}
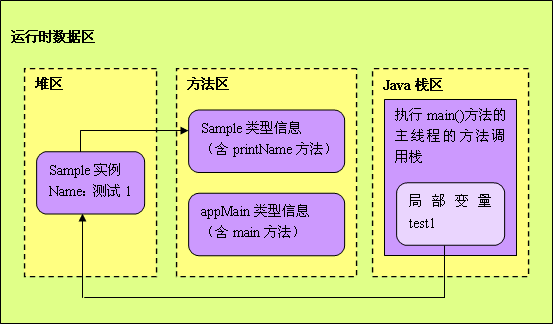
运行该程序时,首先启动一个Java虚拟机进程,这个进程首先从classpath中找到AppMain.class文件,读取这个文件中的二进制数据,然后把Appmain类的类信息存放到运行时数据区的方法区中,这就是AppMain类的加载过程。
接着,Java虚拟机定位到方法区中AppMain类的Main()方法的字节码,开始执行它的指令。这个main()方法的第一条语句就是:
该语句的执行过程:
1、
Java虚拟机到方法区找到Sample类的类型信息,没有找到,因为Sample类还没有加载到方法区(这里可以看出,java中的内部类是单独存在的,而且刚开始的时候不会跟随包含类一起被加载,等到要用的时候才被加载)。Java虚拟机立马加载Sample类,把Sample类的类型信息存放在方法区里。
2、 Java虚拟机首先在堆区中为一个新的Sample实例分配内存, 并在Sample实例的内存中存放一个方法区中存放Sample类的类型信息的内存地址。
3、 JVM的进程中,每个线程都会拥有一个方法调用栈,用来跟踪线程运行中一系列的方法调用过程,栈中的每一个元素就被称为栈帧,每当线程调用一个方法的时候就会向方法栈压入一个新帧。这里的帧用来存储方法的参数、局部变量和运算过程中的临时数据。
4、位于“=”前的Test1是一个在main()方法中定义的一个变量(一个Sample对象的引用),因此,它被会添加到了执行main()方法的主线程的JAVA方法调用栈中。而“=”将把这个test1变量指向堆区中的Sample实例。
5、JVM在堆区里继续创建另一个Sample实例,并在main方法的方法调用栈中添加一个Test2变量,该变量指向堆区中刚才创建的Sample新实例。
6、JVM依次执行它们的printName()方法。当JAVA虚拟机执行test1.printName()方法时,JAVA虚拟机根据局部变量test1持有的引用,定位到堆区中的Sample实例,再根据Sample实例持有的引用,定位到方法去中Sample类的类型信息,从而获得printName()方法的字节码,接着执行printName()方法包含的指令,开始执行。
三、辨析
在Java语言里堆(heap)和栈(stack)里的区别 :
1. 栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
2.
栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享(详见下面的介绍)。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
Java中的2种数据类型:
一种是基本类型(primitive types), 共有8类,即int, short, long, byte, float,
double, boolean, char(注意,并没有string的基本类型)。这种类型的定义是通过诸如int a = 3; long b =
255L;的形式来定义的,称为自动变量。自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在。如int a = 3;
这里的a是一个指向int类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。
栈有一个很重要的特性:存在栈中的数据可以共享。假设我们同时定义: int a = 3; int b = 3;
编译器先处理int a =
3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,如果没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int
b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。
这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完a与
b的值后,再令a=4;那么,b不会等于4,还是等于3。在编译器内部,遇到a=4;时,它就会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。
另一种是包装类数据,如Integer, String, Double等将相应的基本数据类型包装起来的类。这些类数据全部存在于堆中,Java用new()语句来显示地告诉编译器,在运行时才根据需要动态创建,因此比较灵活,但缺点是要占用更多的时间。
四、总结
java内存分配条理还是很清楚的,如果要彻底搞懂,可以去查阅JVM相关的书籍。在java中,内存分配最让人头疼的是String对象,由于其特殊性,所以很多程序员容易搞混淆,下一篇文章再详细讲解。
java程序运行时内存分配详解的更多相关文章
- java程序运行时内存分配详解 (转)
转自:http://www.tuicool.com/articles/uU77v2 一. 基本概念 每运行一个java程序会产生一个java进程,每个java进程可能包含一个或者多个线程,每一个Ja ...
- java运行时内存分配详解
一. 基本概念 每运行一个java程序会产生一个java进程,每个java进程可能包含一个或者多个线程,每一个Java进程对应唯一一个JVM实例,每一个JVM实例唯一对应一个堆,每一个线程有一个自己私 ...
- Java程序运行时内存划分
1.Java程序跨平台运行的原因 主要原因是:各种平台的JVM和字节码文件 Java源程序--具体平台的机器代码文件---被编译器翻译成平台无关的Class文件,又用特定JVM运行字节码文件,JVM在 ...
- Java 虚拟机运行时数据区详解
本文摘自深入理解 Java 虚拟机第三版 概述 Java 虚拟机在执行 Java 程序的过程中会把它所管理的内存划分为若干个不同的数据区域,这些区域有各自的用途,以及创建和销毁的时间,有的区域随着虚拟 ...
- [Java]Java类和对象内存分配详解
描述 代码说明: 一.当Person p1 = new Person();第一次被调用时需要做两件事: 1.先判断类加载器是否加载过Person类,如果没有则加载到Person类型到方法区 2.在堆中 ...
- JAVA中堆栈和内存分配详解(摘抄)
在Java中,有六个不同的地方可以存储数据: 1.寄存器:最快的存储区, 由编译器根据需求进行分配,我们在程序中无法控制. 2. 栈:存放基本类型的变量数据和对象的引用,但对象本身不存放在栈中,而是存 ...
- Java程序运行的内存分配
Java的内存分配 A:栈 存储局部变量 B:堆 存储所有new出来的 C:方法区(程序代码及方法相关) D:本地方法区(系统相关) E:寄存器(CPU使用) 注意: a:局部变量 在方法定义中或者方 ...
- Java学习之二维数组定义与内存分配详解
二维数组:就是元素为一维数组的一个数组. 格式1: 数据类型[][] 数组名 = new 数据类型[m][n]; m:表示这个二维数组有多少个一维数组. n:表示每一个一维数组的元素有多少个. 注意: ...
- Sublime Text3 for Java 编译运行环境配置 入门详解 - 精简归纳
Sublime Text3 for Java 编译运行环境配置 入门详解 - 精简归纳 JERRY_Z. ~ 2020 / 9 / 24 转载请注明出处!️ 目录 Sublime Text3 for ...
随机推荐
- spring AOP的注解实例
上一篇写了spring AOP 的两种代理,这里开始AOP的实现了,个人喜欢用注解方式,原因是相对于XML方式注解方式更灵活,更强大,更可扩展.所以XML方式的AOP实现就被我抛弃了. 实现Sprin ...
- Struts2中struts.multipart.maxSize配置
今天使用Struts2的文件上传控件时,在struts.xml中,将处理上传的action中的fileUpload拦截器的maximumSize参数设置为5000000,上传了一个3M的文件后发现控制 ...
- 20155201 实验三《Java面向对象程序设计》实验报告
20155201 实验三<Java面向对象程序设计>实验报告 一.实验内容 XP基础 XP核心实践 相关工具 二.实验要求 1.没有Linux基础的同学建议先学习<Linux基础入门 ...
- 线程访问ui,托管
1.在类中声明 delegate void setDebugDelegate(string info);//线程访问textbox委托函数 private void setDebug(string i ...
- 漏洞利用之Metasploit使用过程
漏洞利用之Metasploit使用过程 先扫描端口,看开放的服务,如开放ftp,版本是vsftpd 2.3.4:使用search搜索vsftp查看是否在相应的漏洞利用exploit,输入search ...
- 【大型web架构】一个大型web系统架构设计和技术选型的讨论摘录
1.数据库压力问题 所有的压力最终都会反映到数据库方面,一定要对数据库有一个整体的规划. 可以按照业务.区域等等特性对数据库进行配置,可以考虑分库.使用rac.分区.分表等等策略,确保数据库能正常的进 ...
- [BZOJ1257][CQOI2007]余数之和
题目大意 给你 \(n, k\),计算 $ \sum_{i=1}^n k \bmod i$ 解析 注意到 $ k\bmod i=k-[k/i] \times i$ 则上式等于 $ n \times k ...
- HDU 3315 My Brute(二分图最佳匹配+尽量保持原先匹配)
http://acm.hdu.edu.cn/showproblem.php?pid=3315 题意: 有S1到Sn这n个勇士要和X1到Xn这n个勇士决斗,初始时,Si的决斗对象是Xi. 如果Si赢了X ...
- 用 SQL 对关系型数据库进行查询
前面几节中,我们已经掌握了如何向 SQLite 数据库中写入数据.这一节,我们将学习如何根据需求对数据库进行查询,进而从中获取数据.接下来的例子中会使用 data/datasets.sqlite(之前 ...
- 大数据时代,IT行业竟有如此多高薪职位!
近年来云计算.大数据.BYOD.社交媒体.3D打印机.物联网……在互联网时代,各种新词层出不穷,令人应接不暇.这些新的技术.新兴应用和对应的IT发展趋势,使得IT人必须了解甚至掌握最新的IT技能. 另 ...