openstack中region、az、host aggregate、cell 概念
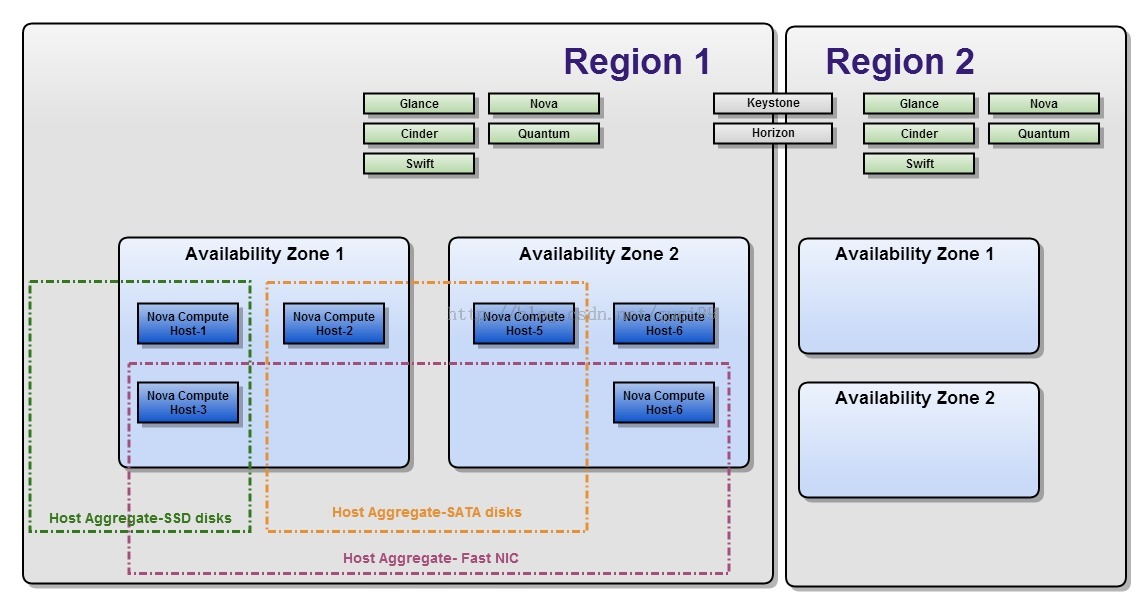
1. region
更像是一个地理上的概念,每个region有自己独立的endpoint,regions之间完全隔离,但是多个regions之间共享同一个keystone和dashboard。(注:目前openstack的dashboard还不支持多region)
所以除了提供隔离的功能,region的设计更多侧重地理位置的概念,用户可以选择离自己更近的region来部署自己的服务。
2. cell
cell是openstack一个非常重要的概念,主要用来解决openstack的扩展性和规模瓶颈。众所周知,openstack是由很多的组件通过松耦合构成,那么当达到一定的规模后,某些模块必然成为整个系统的瓶颈。比较典型的组件就是database和AMQP了,所以,每个cell有自己独立的DB和AMQP。
另外,由于cell被实现为树形结构,自然而然引入了分级调度的概念。通过在每级cell引入nova-cell服务,实现了以下功能:
- Messages的路由,即父cell通过nova-cell将Messages路由到子cell的AMQP模块
- 分级调度功能,即调度某个instances的时候先要进行cell的选择,目前只支持随机调度,后续会增加基于filter和weighing策略的调度
- 资源统计,子cell定时的将自己的资源信息上报给父cell,用来给分级调度策略提供决策数据和基于cell的资源监控
- cell之间的通信(通过rpc完成)
最后,所有的子cell公用底层cell的nova-api,子cell包含除了nova-api之外的其他nova服务,当然所有的cell都共用keystone服务。
(注:nova-*是指除了nova-api之外的其他nova服务,子cell + 父cell才构成了完整的nova服务)
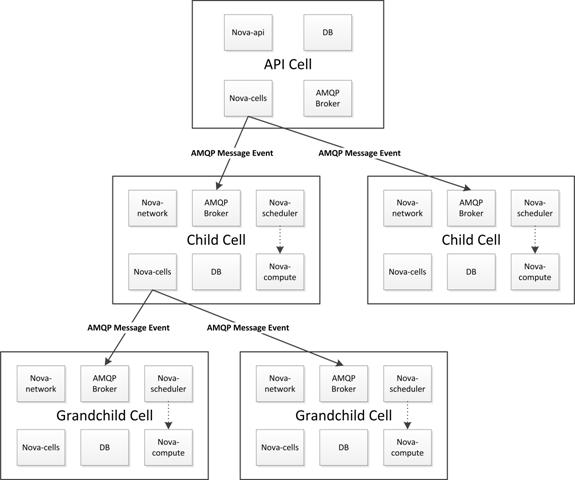
每一个 Cell 包含独立的 Message Broker 以及 Database,其中 API Cell 主要包含 nova-api 服务,用于接收用户请求,并将用户请求通过 message 的形式发送至指定的 Cell;Child Cell 包含除 nova-api 之外的所有 nova-*服务,实现具体的 Nova Compute 节点服务;API Cell 与 Child Cell 共享 Glance 服务,且各 Cells 之间的通信均通过 nova cells 服务进行。Cell 调度独立于与 host 调度,在创建新的实例时,首先由 nova-cells 选择一个 Cell。当 Cell 确定后,实例创建请求会被送达目标 Cell 的 nova-cells 服务,随后该请求会被交给本 Cell 的主机调度机制处理,此时主机调度机制会像未配置 Cell 的环境一样处理该请求。
http://www.ibm.com/developerworks/cn/cloud/library/1409_zhaojian_openstacknovacell/index.html
3. Availability Zone
AZ可以简单理解为一组节点的集合,这组节点具有独立的电力供应设备,比如一个个独立供电的机房,一个个独立供电的机架都可以被划分成AZ。所以,AZ主要是通过冗余来解决可用性问题。
AZ是用户可见的一个概念,用户在创建instance的时候可以选择创建到哪些AZ中,以保证instance的可用性。
4. Host Aggregate (http://docs.openstack.org/havana/config-reference/content/host-aggregates.html)
AZ是一个面向用户的概念和能力,而host aggregate是管理员用来根据硬件资源的某一属性来对硬件进行划分的功能,只对管理员可见,主要用来给nova-scheduler通过某一属性来进行instance的调度。其主要功能就是实现根据某一属性来划分物理机,比如按照地理位置,使用固态硬盘的机器,内存超过32G的机器,根据这些指标来构成一个host group。
Example: Specify compute hosts with SSDs
/etc/nova/nova.conf:
scheduler_default_filters=AggregateInstanceExtraSpecsFilter,AvailabilityZoneFilter,RamFilter,ComputeFilter $ nova aggregate-create fast-io nova
+----+---------+-------------------+-------+----------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+-------+----------+
| 1 | fast-io | nova | | |
+----+---------+-------------------+-------+----------+ $ nova aggregate-set-metadata 1 ssd=true
+----+---------+-------------------+-------+-------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+-------+-------------------+
| 1 | fast-io | nova | [] | {u'ssd': u'true'} |
+----+---------+-------------------+-------+-------------------+ $ nova aggregate-add-host 1 node1
+----+---------+-------------------+-----------+-------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+------------+-------------------+
| 1 | fast-io | nova | [u'node1'] | {u'ssd': u'true'} |
+----+---------+-------------------+------------+-------------------+ $ nova aggregate-add-host 1 node2
+----+---------+-------------------+---------------------+-------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+----------------------+-------------------+
| 1 | fast-io | nova | [u'node1', u'node2'] | {u'ssd': u'true'} |
+----+---------+-------------------+----------------------+-------------------+
$ nova flavor-create ssd.large 6 8192 80 4
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+-------------+
| ID | Name | Memory_MB | Disk | Ephemeral | Swap | VCPUs | RXTX_Factor | Is_Public | extra_specs |
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+-------------+
| 6 | ssd.large | 8192 | 80 | 0 | | 4 | 1 | True | {} |
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+-------------+
# nova flavor-key set_key --name=ssd.large --key=ssd --value=true
$ nova flavor-show ssd.large
+----------------------------+-------------------+
| Property | Value |
+----------------------------+-------------------+
| OS-FLV-DISABLED:disabled | False |
| OS-FLV-EXT-DATA:ephemeral | 0 |
| disk | 80 |
| extra_specs | {u'ssd': u'true'} |
| id | 6 |
| name | ssd.large |
| os-flavor-access:is_public | True |
| ram | 8192 |
| rxtx_factor | 1.0 |
| swap | |
| vcpus | 4 |
+----------------------------+-------------------+
Now, when a user requests an instance with the ssd.large flavor, the scheduler only considers hosts with the ssd=true key-value pair. In this example, these are node1 and node2.
另外,G版中,默认情况下,对Nova服务分为两类,一类是controller节点的服务进程,如nova-api, nova-scheduler, nova-conductor等;另一类是计算节点进程,nova-compute。对于第一类服务,默认的zone是配置项internal_service_availability_zone,而nova-compute所属的zone由配置项default_availability_zone决定。(这两个配置项仅在nova-api的节点起作用,horizon界面才会刷新)。
可能是社区的开发人员意识到,让管理员通过配置的方式管理zone不太合适,不够灵活,所以在G版中将这一方式修改。就改用nova aggregate-create 命令,在创建一个aggregate的同时,指定一个AZ。
root@controller:~# nova help aggregate-create
usage: nova aggregate-create <name> [<availability-zone>] Create a new aggregate with the specified details. Positional arguments:
<name> Name of aggregate.
<availability-zone> The availability zone of the aggregate (optional).
因此创建一个aggregate后,同时把它作为一个zone,此时aggregate=zone。因为大家知道,aggregate是管理员可见,普通用户不可见的对象,那么这个改变,就可以使普通用户能够通过使用zone的方式来使用aggregate。
创建完aggregate之后,向aggregate里加主机时,该主机就自动属于aggregate表示的zone。
在G版之后,可以认为aggregate在操作层面与AZ融合在一起了,但同时又不影响aggregate与flavor的配合使用,因为这是两个调度层面。同时又要注意,一个主机可以加入多个aggregate中,所以G版中一个主机可以同时属于多个Availability Zone,这一点也与之前的版本不同。
openstack中region、az、host aggregate、cell 概念的更多相关文章
- OpenStack中Keystone的基本概念理解
原文http://www.kankanews.com/ICkengine/archives/10788.shtml Keystone简介 Keystone(OpenStack Identity Ser ...
- 管理openstack多region介绍与实践
转:http://www.cnblogs.com/zhoumingang/p/5514853.html 概念介绍 所谓openstack多region,就是多套openstack共享一个keyston ...
- openstack多region介绍与实践---转
概念介绍 所谓openstack多region,就是多套openstack共享一个keystone和horizon.每个区域一套openstack环境,可以分布在不同的地理位置,只要网络可达就行.个人 ...
- openstack多region介绍与实践
版权声明:本文为原创文章,转载请注明出处. 概念介绍 所谓openstack多region,就是多套openstack共享一个keystone和horizon.每个区域一套openstack环境,可以 ...
- 探索 OpenStack 之(14):OpenStack 中 RabbitMQ 的使用
本文是 OpenStack 中的 RabbitMQ 使用研究 两部分中的第一部分,将介绍 RabbitMQ 的基本概念,即 RabbitMQ 是什么.第二部分将介绍其在 OpenStack 中的使用. ...
- OpenStack中memcached的使用和实现
概述 主要分享下个人对Liberty版本openstack中cache使用的理解,由于作者水平有限,难免有所错误,疏漏,还望批评指正. openstack中可以使用cache层来缓存数据,Libert ...
- Multipath在OpenStack中的faulty device的成因及解决(part 1)
| 版权:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接.如有问题,可以邮件:wangxu198709@gmail.com 简介: Multip ...
- OpenStack中的Multipath faulty device的成因及解决(part 1)
| 版权:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接.如有问题,可以邮件:wangxu198709@gmail.com 简介: Multip ...
- OpenStack 中 RabbitMQ 的使用
OpenStack 中 RabbitMQ 的使用 本文是 OpenStack 中的 RabbitMQ 使用研究 两部分中的第一部分,将介绍 RabbitMQ 的基本概念,即 RabbitMQ 是什么. ...
随机推荐
- 最火的.NET开源项目[转]
综合类 微软企业库 微软官方出品,是为了协助开发商解决企业级应用开发过程中所面临的一系列共性的问题, 如安全(Security).日志(Logging).数据访问(Data Access).配置管理( ...
- 从webview中加载assets中的html文件
private void readHtmlFormAssets(){ WebSettings webSettings = tipsWebView.getSettings(); webSettings. ...
- 【题解搬运】PAT_A1020 树的遍历
题目 Suppose that all the keys in a binary tree are distinct positive integers. Given the postorder an ...
- Ubuntu 添加中文字体
查看系统类型 cat /proc/version 查看中文字体 fc-list :lang=zh-cn 安装字体 sudo apt install -y --force-yes --no-instal ...
- web相关基础知识4
一.定位的盒子居中 Css可见性 overflow: hidden; 溢出隐藏 常用在超出盒子之后就隐藏 visibility: hidden; 隐藏元素 隐藏之后还占据原来的位 ...
- idea tomcat 启动报错 org.apache.catalina.core.StandardService.initInternal Failed to initialize connector
org.apache.catalina.core.StandardService.initInternal Failed to initialize connector org.apache.cata ...
- Google Play sign sha1 转 Facebook login 需要的 hashkey
:4E:::::3A:1F::A6:0F:F6:A1:C2::E5::::2E | xxd -r -p | openssl base64 输出 M05IhBlQOh9jpg/2ocIx5QE4VS4= ...
- 【python】python 中的三元表达式(三目运算符)
python中的三目运算符不像其他语言其他的一般都是 判定条件?为真时的结果:为假时的结果 如 result=5>3?1:0 这个输出1,但没有什么意义,仅仅是一个例子.而在python中的格式 ...
- tomcat 路径"/"表示根目录
- kudu介绍及安装配置
kudu介绍及安装配置 介绍 Kudu 是一个针对 Apache Hadoop 平台而开发的列式存储管理器.Kudu 共享 Hadoop 生态系统应用的常见技术特性: 它在 commodity har ...