PLSA的EM推导
本文作为em算法在图模型中的一个应用,推导plsa的em算法。
1 em算法
em算法是解决一类带有隐变量模型的参数估计问题。
1.1 模型的定义
输入样本为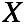 ,对应的隐变量为
,对应的隐变量为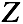 。待估计的模型参数为
。待估计的模型参数为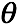 ,目标为极大化似然函数
,目标为极大化似然函数

对于上式的优化,不能通过直接对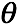 进行求导,因为一旦求导,就有如下的形式:
进行求导,因为一旦求导,就有如下的形式:
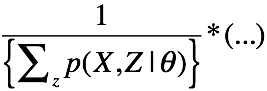
显然是不好求的。
1.2 em算法的迭代过程
a. 初始化:随机初始参数的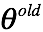
b. E step:
计算隐变量的后验分布
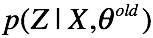
c. M step:
迭代参数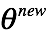
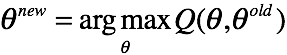
其中,Q函数为X,Z的对数联合分布在Z的后验分布下的期望
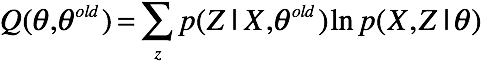 上面的式子,将样本和隐变量都表示成矩阵的形式,让人有些不太好套公式。
上面的式子,将样本和隐变量都表示成矩阵的形式,让人有些不太好套公式。
2 高斯混合模型
2.1 基本模型
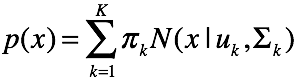 混合高斯模型认为,变量
混合高斯模型认为,变量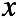 服从一个多峰的高斯分布,由数个高斯分布组合而成。所以我们首先引入隐变量
服从一个多峰的高斯分布,由数个高斯分布组合而成。所以我们首先引入隐变量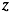 ,并且我们认为变量通过这样一个过程生成。引入隐变量的高斯混合模型用图模型表示:
,并且我们认为变量通过这样一个过程生成。引入隐变量的高斯混合模型用图模型表示:
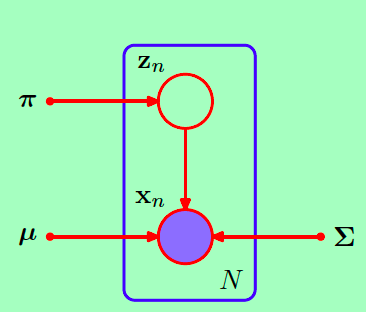
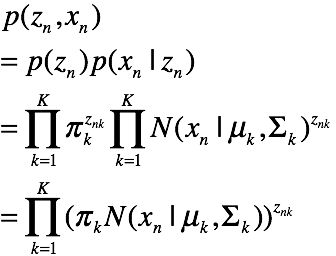
因此该图模型表示的联合概率为:
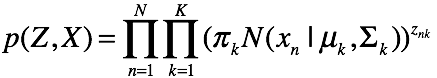 2.2 em算法的推导
2.2 em算法的推导
e step: 计算每一个样本的后验概率,遍历k等于1的各种情况
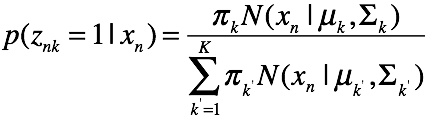
M step: 首先推导Q方程
对于每一对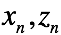
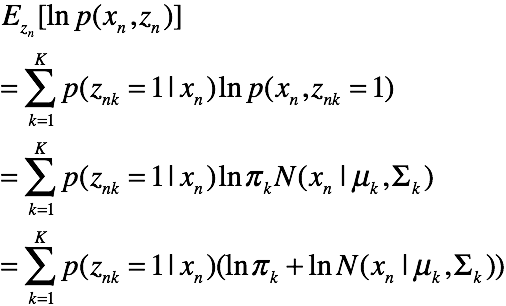
由于N个样本独立,所以有
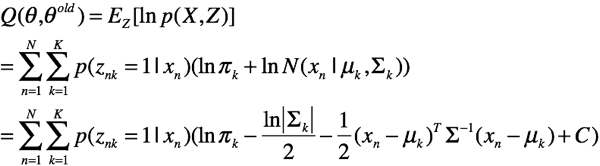
好了,我们开始极大化这个期望
求均值
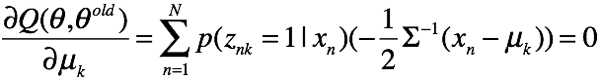 解方程得
解方程得
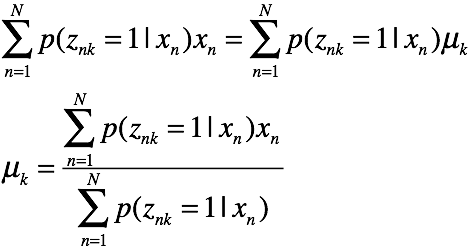
求方差比较复杂,直接给出结论:
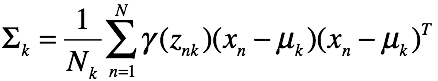
其中:
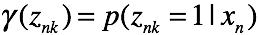
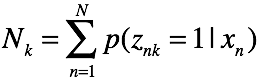 最后求
最后求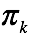 ,注意这里的概率和为1,用拉格朗日乘子法解受限优化问题。有拉格朗日函数
,注意这里的概率和为1,用拉格朗日乘子法解受限优化问题。有拉格朗日函数
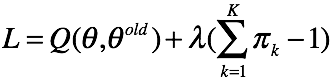
对 求偏导有
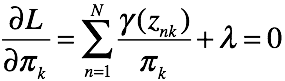
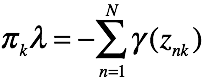
有k个关于的方程,对这些方程做累加有
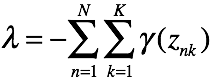
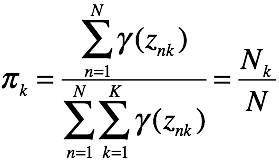 其中,
其中,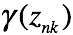 是概率,对k的累加和为1
是概率,对k的累加和为1
至此,混合高斯模型的em迭代方法推导完毕,总结如下
E step:
M step:
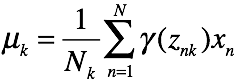
其中
好了,我们完成了混合高斯模型的推导。混合高斯模型是一般高斯模型的推广,使得概率密度估计的外延得到扩展。另外,我们搞清楚了em算法使用的细节,在e step,我们求每一对(zn,xn)的后验概率和联合概率,遍历zn的所有情况,然后求每一个对数似然函数的期望,并在N上求和,就得到了目标函数。
3 PLSA主题模型
PLSA主题模型是比较老的模型了,逐渐被LDA这种更bayesian的方法取代了。我们来看看图模型。
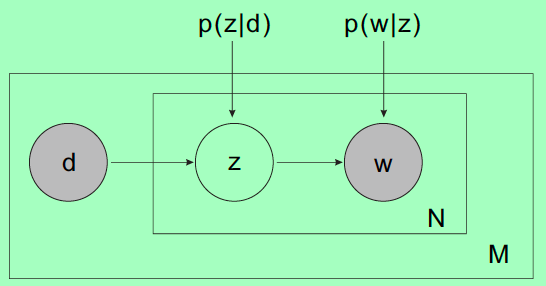
3.1 模型假设
对于一篇文档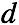 ,在每一个词的位置,首先选择一个topic,然后在topic的词分布中选择一个词作为当前位置的词
,在每一个词的位置,首先选择一个topic,然后在topic的词分布中选择一个词作为当前位置的词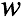 。输入样本为
。输入样本为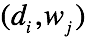 ,需要估计的参数为
,需要估计的参数为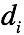 在主题上的分布
在主题上的分布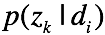 ,以及主题下词的分布
,以及主题下词的分布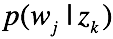 。
。
首先求联合概率。对于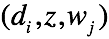 这一Complete样本,
这一Complete样本,
有联合概率
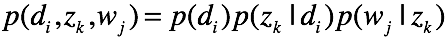
有后验概率
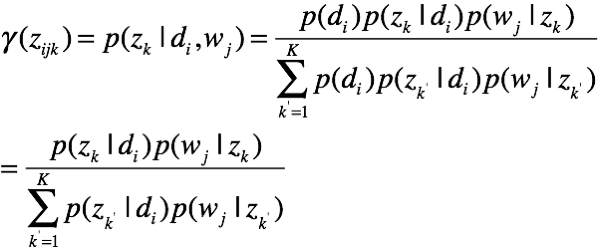 有一对样本的期望函数
有一对样本的期望函数
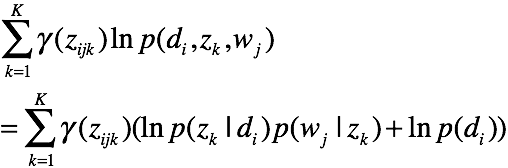
这里,我们取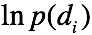 为常数。得到了整体的期望函数
为常数。得到了整体的期望函数
 这里,我们没有考虑词与词之间的相互顺序。接下来,我们要优化这个问题。
这里,我们没有考虑词与词之间的相互顺序。接下来,我们要优化这个问题。
(1) 对于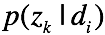 ,根据拉格朗日乘子法有代价函数:
,根据拉格朗日乘子法有代价函数:
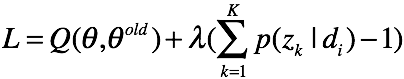 对 求偏导,有
对 求偏导,有
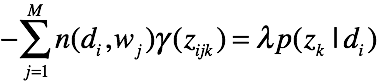
对K个主题方程求和,可得
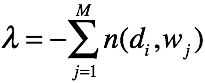
可得
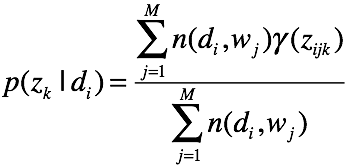
(2) 对于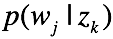 ,根据拉格朗日乘子法有代价函数:
,根据拉格朗日乘子法有代价函数:
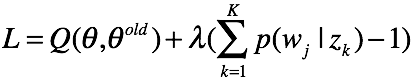
对求偏导,有
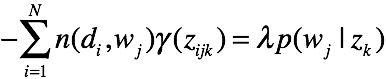
对M个词累加,可得
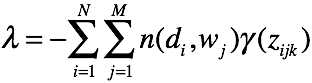
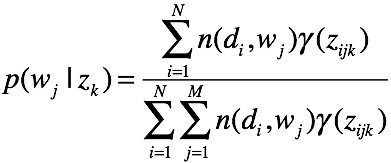 好的,我们可以总结一下过程了。
好的,我们可以总结一下过程了。
E step
计算后验概率
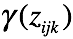
M step
迭代更新
好了,我们推导了一遍混合高斯模型,又自行推导了一遍plsa.EM算法的精华基本掌握了。
PLSA的EM推导的更多相关文章
- PLSA及EM算法
前言:本文主要介绍PLSA及EM算法,首先给出LSA(隐性语义分析)的早期方法SVD,然后引入基于概率的PLSA模型,其参数学习采用EM算法.接着我们分析如何运用EM算法估计一个简单的mixture ...
- 梯度下降和EM算法,kmeans的em推导
I. 牛顿迭代法给定一个复杂的非线性函数f(x),希望求它的最小值,我们一般可以这样做,假定它足够光滑,那么它的最小值也就是它的极小值点,满足f′(x0)=0,然后可以转化为求方程f′(x)=0的根了 ...
- NLP —— 图模型(三)pLSA(Probabilistic latent semantic analysis,概率隐性语义分析)模型
LSA(Latent semantic analysis,隐性语义分析).pLSA(Probabilistic latent semantic analysis,概率隐性语义分析)和 LDA(Late ...
- [IR] Concept Search and PLSA
[Topic Model]主题模型之概率潜在语义分析(Probabilistic Latent Semantic Analysis) 感觉LDA在实践中的优势其实不大,学好pLSA才是重点 阅读笔记 ...
- [Bayes] Concept Search and PLSA
[Topic Model]主题模型之概率潜在语义分析(Probabilistic Latent Semantic Analysis) 感觉LDA在实践中的优势其实不大,学好pLSA才是重点 阅读笔记 ...
- EM算法笔记
EM算法在很多地方都用使用到,比如简单的K-means算法,还有在隐马尔可夫里面,也涉及到了EM算法,可见EM算法在机器学习领域的重要地位.在这里就写一下我对于EM算法的一些理解笔记.后续有新的理解也 ...
- 混合高斯模型的EM求解(Mixtures of Gaussians)及Python实现源代码
今天为大家带来混合高斯模型的EM推导求解过程. watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQveHVhbnl1YW5zZW4=/font/5a6L5L2T/ ...
- LDA( Latent Dirichlet Allocation)主题模型 学习报告
1 问题描述 LDA由Blei, David M..Ng, Andrew Y..Jordan于2003年提出,是一种主题模型,它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一 ...
- AI人工智能顶级实战工程师 课程大纲
课程名称 内容 阶段一.人工智能基础 — 高等数学必知必会 1.数据分析 "a. 常数eb. 导数c. 梯度d. Taylore. gini系数f. 信息熵与组合数 ...
随机推荐
- TPS和QPS区别
TPS和QPS区别 http://blog.csdn.net/kobejayandy/article/details/9374747
- 蓝桥杯 算法训练 ALGO-36 传纸条
算法训练 传纸条 时间限制:1.0s 内存限制:512.0MB 问题描述 小渊和小轩是好朋友也是同班同学,他们在一起总有谈不完的话题.一次素质拓展活动中,班上同学安排做成一个m行n列的矩阵,而 ...
- FTP mget without prompt
# ftp 192.168.100.2Connected to 192.168.100.2.220 Microsoft FTP ServiceName (192.168.100.2:root): ja ...
- .net中webconfig自定义配置
在configuration节点,也就是文件的根节点下,增加如下节点 <appSettings> <!--<add key="propPath" value ...
- 关于 Mybatis的原生连接池 和 DBCP 连接池
一 遇到的问题: 项目用的play框架,数据库DB2, 持久化框架是Mybatis, 连接池用的是Mybatis原生的,遇到的问题是:有时候抛出如下异常: play.api.UnexpectedEx ...
- Py修行路 python基础 (十)装饰器
装饰器 一.定义 装饰器:顾名思义,就是对某个东西起到装饰修饰的功能. python中的装饰器,其本质上就是一个python函数,它可以让其他函数在不需要任何代码变动的前提下增加额外功能.通俗理解就是 ...
- js中的Generators函数
js中的Generators函数 generator一般操作 generator函数的作用就是函数体分段执行,yield表示分隔点 function *test() { console.log(1); ...
- java成神之——jaxb操作xml的基本使用
JAXB 依赖 读取xml配置 写配置 自定义写配置 结语 JAXB 依赖 <dependency> <groupId>javax.activation</groupId ...
- python与桶排序
问题提出: 将以下数据: 6, 8, 2, 3, 4, 0, 9, 1, 5,1 按从小到达排列. 桶排序原理: 桶排序也叫计数排序,简单来说,就是将数据集里面所有元素按顺序列举出来,然后统计元素出现 ...
- Django Rest Framework 3
目录 一.版本 二.解析器 三.序列化 四.请求数据验证 一.版本 程序也来越大时,可能通过版本不同做不同的处理 没用rest_framework之前,我们可以通过以下这样的方式去获取. 1 clas ...