基于IG的特征评分方法
本文简单介绍了熵、信息增益的概念,以及如何使用信息增益对监督学习的训练样本进行评估,评估每个字段的信息量。
1、熵的介绍
在信息论里面,熵是对不确定性的测量。通俗来讲,熵就是衡量随机变量随机性的指标。比如一个随机变量X的状态有{1,2,...,n},如果X取1的概率为1,其他状态为0,那么这个随机变量一点儿随机性都没有,也就是信息量为0;反之,如果每个状态的概率都相当,也就是说这个随机变量不倾向任何一个状态,因此随机性最高。(在离散情况,均匀分布的熵最高;在连续情况,正态分布的熵最高。)
熵的计算公式:
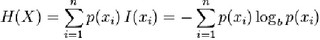
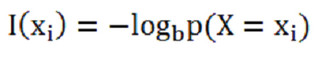
I(xi)是状态xi的信息量,H(X)是对各个状态的信息量的加权平均。如果不理解I(xi) ,可以简单地这样理解,如果p(X=xi) 很小的话,也就是说这种情况出现很罕见,因此要推测该状态就比较不容易,随机性就高,所以该状态的信息量就大。
另外,有一点需要注意的是,熵是有单位的,具体取决于用什么log底,b。比如b=2的时候,单位是bit。bit就是位,和平常我们学习的存储单位“bit”是一样的。这点如果不理解的话,大家可以做个简单的计算,令随机变量有两个状态,每个状态的概率为0.5,令b=2,这样算出来的熵是1(bit)。1bit表示我们如果要传输这个随机变量的信息的时候,需要存储量是1bit。熵还可以这样理解,熵就是我们要传输一个随机变量的信息时,需要使用的存储量。这种理解和上述是一致的,因为如果变量随机性高的话,我们传输时就需要使用更多的bit,所以,存储量大和随机性高是相同意思的。
最后,为了避免大家对概念的混淆,我们总结如下一段话:
熵越高,不确定性越高,随机性越强,信息量越大,需要的存储量就越大。
2、信息增益IG
信息增益在不同情况下,意思稍微有点区别,我们使用的概念和决策时的概念是一致的。但是,另外一种情况,即如下介绍的KL-divergence,也是可以用来筛选特征的,所以,下面,我们首先介绍一下KL-divergence,大家如果感兴趣,可以专门去了解一下。
在信息论和机器学习中,信息增益(Information Gain)或者Mutual Information都是表示Kullback–Leibler divergence,这个概念是用来描述两个随机变量之间的依赖程度,简单的理解,两个随机变量的KL-divergence就是已知某个随机变量的时候,我们还需要多少信息才能预测另一个随机变量的取值,因此,该指标是不对称的(asymmetric)。这个指标也可以用来做特征筛选,计算的指标就是一致某个特征的取值时,推测label还需要多少信息量,该量越大,说明特征提供的信息越少,否则说明特征提供的信息量很大,使得我们不需要额外的信息就可以推知label信息。
在决策树中,信息增益和KL-divergence不一样,这里信息增益指的是在划分数据集之前和之后信息发生的变化。

这里信息增益有个关键点就是对样本进行划分。像决策树,就是根据特征字段的值对样本进行划分,使得获得的信息增益最大。
3、使用IG计算字段的信息量
对于离散值的字段,我们根据该字段的取值情况对样本进行划分,将计算得到的信息增益作为字段的信息量。如果字段取值是连续性,熵和信息增益都有连续版本,但是连续版本需要求积分,计算量很大,所以,为了方便计算,我们先将字段执行离散化操作,然后计算字段的信息量。
得到字段的信息量之后,我们就可以根据一个阈值对字段进行筛选,去掉那些没有信息的字段。也可以使用topN选择最优信息量的字段。
基于IG的特征评分方法的更多相关文章
- 基于Python的信用评分卡模型分析(二)
上一篇文章基于Python的信用评分卡模型分析(一)已经介绍了信用评分卡模型的数据预处理.探索性数据分析.变量分箱和变量选择等.接下来我们将继续讨论信用评分卡的模型实现和分析,信用评分的方法和自动评分 ...
- 基于Python的信用评分卡模型分析(一)
信用风险计量体系包括主体评级模型和债项评级两部分.主体评级和债项评级均有一系列评级模型组成,其中主体评级模型可用“四张卡”来表示,分别是A卡.B卡.C卡和F卡:债项评级模型通常按照主体的融资用途,分为 ...
- 【原创】xgboost 特征评分的计算原理
xgboost是基于GBDT原理进行改进的算法,效率高,并且可以进行并行化运算: 而且可以在训练的过程中给出各个特征的评分,从而表明每个特征对模型训练的重要性, 调用的源码就不准备详述,本文主要侧重的 ...
- 解决CSS垂直居中的几种方法(基于绝对定位,基于视口单位,Flexbox方法)
在CSS中对元素进行水平居中是非常简单的:如果它是一个行内元素,就对它的父元素应用 text-align: center ;如果它是一个块级元素,就对它自身应用 margin: auto.然而如果要对 ...
- XGBboost 特征评分的计算原理
xgboost是基于GBDT原理进行改进的算法,效率高,并且可以进行并行化运算,而且可以在训练的过程中给出各个特征的评分,从而表明每个特征对模型训练的重要性, 调用的源码就不准备详述,本文主要侧重的是 ...
- 基于HALCON的模板匹配方法总结
注:很抱歉,忘记从转载链接了,作者莫怪.... 基于HALCON的模板匹配方法总结 很早就想总结一下前段时间学习HALCON的心得,但由于其他的事情总是抽不出时间.去年有过一段时间的集中学习,做了许多 ...
- Javascript基于对象三大特征 -- 冒充对象
Javascript基于对象三大特征 基本概述 JavaScript基于对象的三大特征和C++,Java面向对象的三大特征一样,都是封装(encapsulation).继承(inheritance ) ...
- 经典文本特征表示方法: TF-IDF
引言 在信息检索, 文本挖掘和自然语言处理领域, IF-IDF 这个名字, 从它在 20 世纪 70 年代初被发明, 已名震江湖近半个世纪而不曾衰歇. 它表示的简单性, 应用的有效性, 使得它成为不同 ...
- 基于 Token 的身份验证方法
使用基于 Token 的身份验证方法,在服务端不需要存储用户的登录记录.大概的流程是这样的: 客户端使用用户名跟密码请求登录 服务端收到请求,去验证用户名与密码 验证成功后,服务端会签发一个 Toke ...
随机推荐
- LeetCode447. Number of Boomerangs
Description Given n points in the plane that are all pairwise distinct, a "boomerang" is a ...
- 把world转成html
本来用php转的 效果不太理想 很不稳定 最后试了下java 效果不错 只记录java的方法好了 其实他们的原理都是一样的啊,都是用到了微软的com 首先是准备工作 下载(明确dll的版本是64位的还 ...
- 第一百八十四节,jQuery-UI,验证注册表单
jQuery-UI,验证注册表单 html <form id="reg" action="123.html" title="会员注册" ...
- 在PC端或移动端应用中接入商业QQ
前两天在做一个项目XXX的时候,遇见一个问题,在页面中需要接入企业的QQ,在查找腾讯API后无果,则请求人工服务,然后人家给一网址(就是API接口),然后你只需要登录你的QQ,然后选择相应的显示类型, ...
- Unity3d NGUI UICheckbox
单选按钮: 一,常用属性: 1,CheckSprite:选中后,才显示的Sprite,即为“选中”状态; 2,Starts Checked:true,一开始就显示“选中”状态; 3,RadioButt ...
- CGI FastCGI PHP-CGI PHP-FRM
CGI(Common GateWay Interface )通用网关接口,CGI可以让一个客户端,从网页浏览器向执行在Web服务器上的程序请求数据.CGI描述了客户端和这个程序之间传输数据的一种协议标 ...
- Python操作yaml文件
基本的yaml语法 http://ansible-tran.readthedocs.io/en/latest/docs/YAMLSyntax.html YAML 还有一个小的怪癖. 所有的 YAML ...
- Python成长之路(常用模块学习)
Python 拥有很多很强大的模块 主要写一下常用的几个吧 大概就是这些内容了 模块介绍 time &datetime模块 random os sys shutil json & pi ...
- matlab7.0安装 win7系统详细使用方法附软件下载
MATLAB 7.0下载地址: 百度网盘下载地址:http://pan.baidu.com/share/link?shareid=414204&uk=2769186556 迅雷快传下载地址:h ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...