由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享
pandas内存优化分享
缘由
最近在做Kaggle上的wiki文章流量预测项目,这里由于个人电脑配置问题,我一直都是用的Kaggle的kernel,但是我们知道kernel的内存限制是16G,如下:

在处理数据过程中发现会超出,虽然我们都知道对于大数据的处理有诸如spark等分布式处理框架,但是依然存在下面的问题:
- 对于个人来说,没有足够的资源让这些框架发挥其优势;
- 从处理数据的库丰富程度上,还是pandas等更具有优势;
- 很多时候并不是pandas无法处理,只是数据未经优化;
所以这里还是考虑针对数据进行内存方面的优化,以达到减少内存占用,并在kernel上正常运行为最终目的;
整个尝试的过程
只加载当前用到的
这个不用多说,虽然一般为了省事,都是开头一起load到内存中,但是特殊情况下,这里还是要注意的,如下:
可以看到,虽然可用数据文件很多,但是由于当前处理需要的仅仅是train2.csv,所以只加载其即可,不要小看这一步,这里每个文件加载过来都是几百M的;
类型转换
这里是在预处理部分能做的对内存影响最大的一部分,基本思路如下:
- object考虑是否需要转换为category;
- numeric,即各种数值类型,是否在允许范围内降低类型,例如假如某一列为整型且最大值为100,那么就是用用int8类型来描述;
- 对于日期类型,可以先不着急转为datetime64,我们直到datetime类型占用内存是比object还多的,可以先考虑转为category,后续处理完释放了没用对象后再转回来即可(这种方式比较少用,但是对于这个项目还是挺有用的,因为最终内存峰值也就在那几G上);
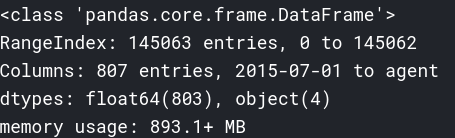
如下是未做转换前的DataFrame信息:
如下是我对原始数据各字段的类型转换以及转换后的DataFrame信息:

看到内存占用直接降了一半,不要小看这几百M,在DataFrame进行各种apply、groupby运算时,临时占用的内存是非常多的,也很容易超过峰值导致kernel重启;
PS:当然,这里如果直接加载时指定数据类型也是可以的,我这边为了展示转换前后效果,所以直接指定,实时上更常见的做法时,先直接加载,info或者describe看数据信息,然后判断数据应该的类型,修改代码为直接指定;
使用union_categoricals代替pd.concat实现表的连接
做过时序数据预测的朋友应该直到,时序数据构建时,一个特点是需要连接训练和测试数据,然后同时针对这些数据做时序上的延迟特征、各种维度的统计特征等等,因此这里就涉及到数据连接,一定要注意要用union_categoricals代替pd.concat,如果直接使用concat,那么category类型的列会被转为object,那么在连接的过程中,内存就会超过峰值,导致kernel重启,那就悲剧了。。。。
如下,是对数据做reshape的操作,这个是该竞赛数据的一个特点,由于其把每一天对应的访问数据都放到了一起,也就是一行中包含了一篇文章的每一天的访问量,而这是不利于后续做延迟特征构建的,需要将每一天的信息单独作为一行,因此需要reshape:

如下这种连接、即时销毁的方式虽然看着丑,但是效果还是可以的:
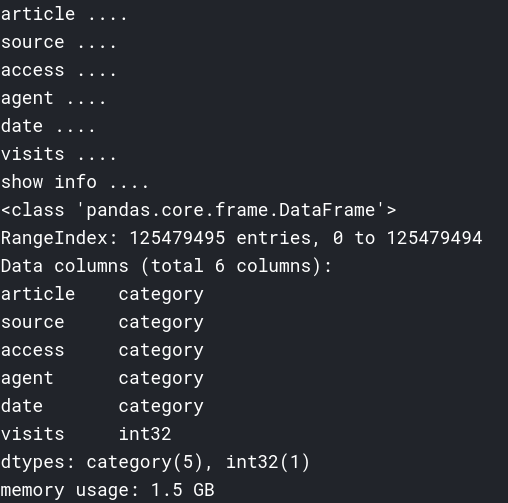
如下是采取这种方式链接后的DataFrame信息,其实难点不在于DataFrame多大,而是它在运算过程中的内存峰值会超过限制:
注意
- 即时del掉不用的对象;
- 对于category列的连接,使用union_categoricals;
- 在不同类型的列连接时,结果类型会取大的那个,比如int8连接int64,那么结果就都是int64;
- 关于category类型,不仅可以降低内存占用,而且还能加快运算速度,关键在于特征的取值可能数量是否远小于行数;
Kaggle竞赛链接
https://www.kaggle.com/c/web-traffic-time-series-forecasting
Kaggle kernel链接,该kernel已经设置为public,大家可以随意copy
https://www.kaggle.com/holoong9291/web-traffic-time-series-forecasting
最后
大家可以到我的Github上看看有没有其他需要的东西,目前主要是自己做的机器学习项目、Python各种脚本工具、数据分析挖掘项目以及Follow的大佬、Fork的项目等:
https://github.com/NemoHoHaloAi
由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享的更多相关文章
- Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测
Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测 2017年12月13日 17:39:11 机器之心V 阅读数:5931 近日,Artur Suilin 等人发布了 Kaggl ...
- 教程 | Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测
https://mp.weixin.qq.com/s/JwRXBNmXBaQM2GK6BDRqMw 选自GitHub 作者:Artur Suilin 机器之心编译 参与:蒋思源.路雪.黄小天 近日,A ...
- 如何使用Python在Kaggle竞赛中成为Top15
如何使用Python在Kaggle竞赛中成为Top15 Kaggle比赛是一个学习数据科学和投资时间的非常的方式,我自己通过Kaggle学习到了很多数据科学的概念和思想,在我学习编程之后的几个月就开始 ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- 《机器学习及实践--从零开始通往Kaggle竞赛之路》
<机器学习及实践--从零开始通往Kaggle竞赛之路> 在开始说之前一个很重要的Tip:电脑至少要求是64位的,这是我的痛. 断断续续花了个把月的时间把这本书过了一遍.这是一本非常适合基于 ...
- 《Python机器学习及实践:从零开始通往Kaggle竞赛之路》
<Python 机器学习及实践–从零开始通往kaggle竞赛之路>很基础 主要介绍了Scikit-learn,顺带介绍了pandas.numpy.matplotlib.scipy. 本书代 ...
- kaggle竞赛分享:NFL大数据碗(上篇)
kaggle竞赛分享:NFL大数据碗 - 上 竞赛简介 一年一度的NFL大数据碗,今年的预测目标是通过两队球员的静态数据,预测该次进攻推进的码数,并转换为该概率分布: 竞赛链接 https://www ...
- Kaggle竞赛入门:决策树算法的Python实现
本文翻译自kaggle learn,也就是kaggle官方最快入门kaggle竞赛的教程,强调python编程实践和数学思想(而没有涉及数学细节),笔者在不影响算法和程序理解的基础上删除了一些不必要的 ...
- Kaggle竞赛入门(二):如何验证机器学习模型
本文翻译自kaggle learn,也就是kaggle官方最快入门kaggle竞赛的教程,强调python编程实践和数学思想(而没有涉及数学细节),笔者在不影响算法和程序理解的基础上删除了一些不必要的 ...
随机推荐
- linux设备驱动文件结构
struct file, 定义于 <linux/fs.h>, 是设备驱动中第二个最重要的数据结构. 注意 file 与用户空间程序的 FILE 指针没有任何关系. 一个 FILE 定义在 ...
- P1002 Hello,World!
题目描述 输出"Hello Wolrd!". 输入格式 无. 输出格式 输出一行"Hello World!". 样例输入 无. 样例输出 Hello World ...
- Webstorm 配置 Less编译
配置less编译
- Jenkins 配置自动合并 release 分支到 master 分支
本文告诉大家如何在 Jenkins 配置合并到 release 的内容自动合并到 gitlab 的 master 分支 首先需要两个仓库,一个是 gitlab 的仓库,另一个是 Jenkins 的仓库 ...
- 2018.11.2浪在ACM集训队第三次测试赛
2018.11.2 浪在ACM 集训队第三次测试赛 整理人:孔晓霞 A 珠心算测试 参考博客:[1]李继朋 B 比例简化 参考博客: [1]李继朋 C 螺旋矩阵 参考博客:[1]朱远迪 D 子矩阵 ...
- dotnet 动态代理魔法书
看到标题的小伙伴是不是想知道什么是魔法书,如果你需要写一段代码,这段代码是在做神奇的业务,只有你查询到了魔法书你才能找到这个对象,同时你还需要实现自己的接口,通过自己实现的接口调用才能用到有趣的方法 ...
- gulp 批量添加类名 在一个任务中使用多个文件来源
1.首先安装环境 1.安装gulp: npm install gulp 2.安装gulp-clean-css npm install gulp-clean-css 3.安装gulp-css-wrap ...
- 企业级Docker私有仓库Harbor
一.Harbor简介 1.Harbor介绍 Harbor是一个用于存储和分发Docker镜像的企业级Registry服务器,通过添加一些企业必需的功能特性,例如安全.标识和管理等,扩展了开源Docke ...
- Android生命周期函数执行顺序
转载自:http://blog.csdn.net/intheair100/article/details/39061473 程序正常启动:onCreate()->onStart()->on ...
- 看各类框架源码淘来的一些JavaScript技巧
1. 创建定长的JavaScript数组,并赋空值: 出自VUE文档Render函数讲解 // 创建定长20的JavaScript数组,并把每个项的值设为null Array.apply(null, ...