左神算法进阶班6_1LFU缓存实现
【题目】
LFU也是一个著名的缓存算法,自行了解之后实现LFU中的set 和 get
要求:两个方法的时间复杂度都为O(1)
【题解】
LFU算法与LRU算法很像
但LRU是最新使用的排在使用频率最前面,也就是LRU是通过使用时间进行排序,
使用时间越新,其使用频率越高,而使用时间越久,其使用频率越低,即当空间满时,被删除的概率最大
而LFU是根据使用次数来算使用频率的,使用次数越多,其使用频率越高,使用次数越少,使用频率越低,当空间满时越容易被删除
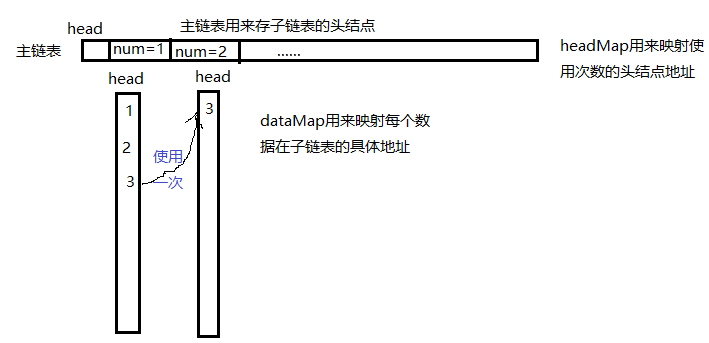
同样,使用hash_map表和双向链表进行存储;
hash表存储关键词与双向链表的节点地址
而双向链表的数据存储的是使用次数,每种使用次数仍然是一个双向链表,
当put一个数据,则在使用次数为1的链表节点下的链表中按put顺序依次存储
当每get一个数据,若存在,而在相对应使用次数的链表节点中拿出,放在下一个链表节点下,即使用次数 + 1的节点
记住,在相同的使用次数中,是按照使用时间顺序进行存放的,
所以,当空间满时,首先删除大链表的头中的头,即使用次数为1的节点中的头结点【最早放入】,若使用次数都一样,同样是删除该使用次数节点中链表的 头节点
所以,数据存放于链表尾部,数据删除于链表的头部
还有,当某个链表节点为空,则删除,某个链表节点不存在,则新建
比如,当使用次数为2的节点中无数据,则删出该节点,
当有一个新数据的使用次数为2时,发现不存在使用次数为2的节点,那么就应该新建一个节点
【代码】
#pragma once
#include <iostream>
#include <hash_map> using namespace std; struct Node//子链表
{
int key;
int val;
int num;
Node* next;
Node* pre;
Node(int a, int b, int n) :key(a), val(b), num(n), next(nullptr), pre(nullptr) {}
}; struct NodeList//主链表
{
int num;
Node* head;//子链表的头节点
Node* tail;//子链表的尾结点
NodeList* next;
NodeList* pre;
NodeList(int a) :num(a), next(nullptr), pre(nullptr)
{
head = new Node(, , a);//新建一个子链表的头结点
tail = head;
}
}; class LFU
{
public:
LFU(int size) :capacity(size) {}
void set(int key, int value);
int get(int key); private:
void getNode(Node*& p, NodeList*& h);//将节点从子链表中取出
void moveNode(Node*& p, NodeList*& h);//将节点向后移动
void deleteNode(int num, NodeList*& h);//删除子链表
void createNode(Node*p, NodeList*& h);//新建子链表,并插入在主链中
void updataNode(Node*& p, NodeList*& h);//更新函数的使用次数
void deleteData();//容量不足需要删除 private:
int capacity;
NodeList* headList = new NodeList();//主链表的头结点
hash_map<int, Node*>dataMap;//key <——> 真实数据节点地址
hash_map<int, NodeList*>headMap;//次数 <——> 链表头节点地址
}; void LFU::set(int key, int value)
{
if (this->capacity == )
return;
if (dataMap.find(key) != dataMap.end())//已经存在
{
Node* p = dataMap[key];//找到数据节点
NodeList* h = headMap[p->num];//找到头链表节点
p->val = value; updataNode(p, h);//更新数据的使用次数
}
else//如果不存在,则新建
{
if (dataMap.size() >= this->capacity)//容量不足,需要删除数据
deleteData(); Node* p = new Node(key, value, );//使用用一次
dataMap[key] = p;//记录 //将新建节点插入使用1次的子链表中
if (headMap.find() == headMap.end())//当使用1次的子链表不存在
createNode(p, headList);
else
moveNode(p, headMap[]);//插入在使用次数在1的子链表中
}
} int LFU::get(int key)
{
if (dataMap.find(key) == dataMap.end())//数据不存在
return -;
Node* p = dataMap[key];//找到数据节点
NodeList* h = headMap[p->num];
updataNode(p, h); return p->val;
} void LFU::getNode(Node*& p, NodeList*& h)//将节点从子链表中取出
{
p->pre->next = p->next;
if (p->next == nullptr)
h->tail = p->pre;
else
p->next->pre = p->pre;
} void LFU::moveNode(Node*& p, NodeList*& q)//将节点向后移动
{
p->next = q->tail->next;
q->tail->next = p;
p->pre = q->tail;
q->tail = p;
} void LFU::deleteNode(int num, NodeList*& h)//删除子链表
{
headMap.erase(num);//从map中删除
h->pre->next = h->next;
if (h->next != nullptr)
h->next->pre = h->pre;
delete h;
h = nullptr;
} void LFU::createNode(Node*p, NodeList*& h)//新建子链表,并插入在主链中
{
NodeList* q = new NodeList(p->num);//新建一个子链表
headMap[p->num] = q;//保存对应的地址 moveNode(p, q);////将节点放入子链表中 //将新子链插入主链表中
q->next = h->next;
if (h->next != nullptr)
h->next->pre = q;
h->next = q;
q->pre = h;
} void LFU::updataNode(Node*& p, NodeList*& h)//更新函数的使用次数
{
int num = p->num;
p->num++;//使用次数+1 //将p从子链表中取出
getNode(p, h); //将该数据向后面移动
if (headMap.find(p->num) == headMap.end())//不存在num+1的节点,那么新建
createNode(p, h);
else
moveNode(p, headMap[p->num]);////将节点放入子链表中 //如果该子链表为空,将该子链表删除,并从map中删除
if (h->head == h->tail)
deleteNode(num, h);
} void LFU::deleteData()//容量不足需要删除
{
NodeList* p = headList->next;
Node* q = p->head->next;//删除子链表排在最前面的数据
if (q == p->tail)//要删除的数据就是最后一个数据,则删除该节点和子链表
deleteNode(q->num, p);
else
{
p->head->next = q->next;
q->next->pre = p->head;
}
dataMap.erase(q->key);//删除记录
delete q;//删除
q = nullptr;
} void Test()
{
LFU* f = new LFU();
f->set(, );
f->set(, );
f->set(, );
cout << f->get() << endl;
f->set(, );
cout << f->get() << endl;
cout << f->get() << endl;
cout << f->get() << endl;
cout << f->get() << endl;
cout << f->get() << endl;
cout << f->get() << endl;
cout << f->get() << endl;
cout << f->get() << endl;
cout << f->get() << endl;
f->set(, );
cout << f->get() << endl;
cout << f->get() << endl; }
左神算法进阶班6_1LFU缓存实现的更多相关文章
- 左神算法进阶班5_4设计可以变更的缓存结构(LRU)
[题目] 设计一种缓存结构,该结构在构造时确定大小,假设大小为K,并有两个功能: set(key, value):将记录(key, value)插入该结构. get(key):返回key对应的valu ...
- 左神算法进阶班1_5BFPRT算法
在无序数组中找到第k大的数1)分组,每N个数一组,(一般5个一组)2)每组分别进行排序,组间不排序3)将每个组的中位数拿出来,若偶数,则拿上 / 下中位数, 成立一个一个新数组.4)新数组递归调用BF ...
- 左神算法进阶班3_1构造数组的MaxTree
题目 一个数组的MaxTree定义: 数组必须没有重复元素 MaxTree是一棵二叉树,数组的每一个值对应一个二叉树节点 包括MaxTree树在内且在其中的每一棵子树上,值最大的节点都是树的头 给定一 ...
- 左神算法进阶班8_1数组中累加和小于等于aim的最长子数组
[题目] 给定一个数组arr,全是正数:一个整数aim,求累加和小于等于aim的,最长子数组,要求额外空间复杂度O(1),时间复杂度O(N) [题解] 使用窗口: 双指针,当sum <= aim ...
- 左神算法进阶班1_4Manacher算法
#include <iostream> #include <string> using namespace std; //使用manacher算法寻找字符中最长的回文子串 in ...
- 左神算法进阶班1_1添加最少字符得到原字符N次
Problem: 给定一个字符串str1,只能往str1的后面添加字符变成str2. 要求1:str2必须包含两个str1,两个str1可以有重合,但是不能以同一个位置开头. 要求2:str2尽量短最 ...
- 左神算法进阶班4_2累加和为aim的最长子数组
[题目] 给定一个数组arr,和一个整数aim,求在arr中,累加和等于num的最长子数组的长度 例子: arr = { 7,3,2,1,1,7,7,7 } aim = 7 其中有很多的子数组累加和等 ...
- 左神算法基础班4_1&2实现二叉树的先序、中序、后序遍历,包括递归方式和非递归
Problem: 实现二叉树的先序.中序.后序遍历,包括递归方式和非递归方式 Solution: 切记递归规则: 先遍历根节点,然后是左孩子,右孩子, 根据不同的打印位置来确定中序.前序.后续遍历. ...
- 左神算法基础班5_1设计RandomPool结构
Problem: 设计RandomPool结构 [题目] 设计一种结构,在该结构中有如下三个功能: insert(key):将某个key加入到该结构,做到不重复加入. delete(key):将原本在 ...
随机推荐
- 【转】详解tomcat的连接数与线程池
对tomcat线程池.Connector的BIO.NIO解析的很透彻的一篇文章. 原文链接:https://www.cnblogs.com/kismetv/p/7806063.html 前言 在使用t ...
- Producer-Consumer 生产者,消费者
这个模式跟Guarded模式有点类似,不过需要一个控制台限制请求方和处理方的频度和数量. public class ProducerConsumerTest { /** * @param args * ...
- (转)protobuf-----Mac 机器安装
转自: https://blog.csdn.net/u014534808/article/details/80203018 安装之旅 1. 下载protobufprotobuf下载页面 在此页面选择合 ...
- EntityFrameworkCore 根据实体类自动创建数据库
1.首先新建 Asp.Net Core WebApi 项目 2.添加一下引用 : 2.1 Pomelo.EntityFrameworkCore.MySql(我用的Mysql 根据自己情况引用就行) ...
- 导出sheet到新文件夹当中
Sub 导出当前客户达成分析()Application.ScreenUpdating = FalsemyName1 = Sheets("日期统计表").Range("B1 ...
- 实现div里面有placeholder形式
样式中设置content为元素的data-值 p{ color: deepskyblue; } p:before{ content: attr(data-beforeContent); color: ...
- java String,StringBuilder和StringBuffer类的区别
对String而言: String是只读字符串,所引用的字符串不能被改变,一经定义,无法再增删改. String 定义的字符串保存在常量池里面,进行+操作时不能直接在原有基础上拼接. 每次+操作 : ...
- SQL Server Download
{ https://www.microsoft.com/zh-cn/sql-server/sql-server-downloads }
- layui点击按钮自动刷新页面问题
问题 <button class="layui-btn layui-btn-primary" onclick="findData()">查询< ...
- CF377D Developing Game
题目链接: luogu 题目分析: 把每个人当成一个三元组\([l_i, r_i, v_i]\) 考虑每个人对哪个能力区间\([L, R]\)有贡献 应该是左端点在\([l_i, v_i]\),右端点 ...