Hystrix压测
背景介绍
JSF(京东服务框架,类似dubbo)默认配置了可伸缩的最大到200的工作线程池,每一个向外提供的服务都在其中运行(这里我们是服务端),这些服务内部调用外部依赖时(这里我们是客户端)一般是同步调用,不单独限制调用并发量,因为同步调用时会阻塞原服务线程,因此实际上所有外部调用共享了JSF的200工作线程池。
Hystrix框架为了隔离依赖相互影响,默认使用了线程隔离机制,为每个依赖提供一个小的线程池,如果该线程池已满新的调用将被立即拒绝,默认不排队加快失败返回。这与JSF原来的机制非常不一样,我们的问题是:
额外的线程池是否有太大的性能开销?
线程池大小设置多少合理?
希望通过本次测试调研得到答案。
用例介绍
构造两个接口,分别调用原生mock方法和调用经过hystrix包装的mock方法,两个mock方法内部都是一个Thread.sleep,根据不同参数模拟不同性能的外部依赖调用。其中JSF线程池为默认值最大200,hystrix单个线程池大小为默认值10,默认超时1000ms,为了排除干扰禁用断路器。根据两个接口、不同mock参数和不同压测线程数组合构造出共11个测试用例。
部署单台只包括这两个接口的生产机器,使用分布式压测平台(多台Jmeter)对其进行压测,主要通过接口内部的UMP进行性能和JVM状态监控,JVM使用JDK8并且开启G1收集器(压测中无full gc)。
@Service
public class MockJsfServiceRef {
@HystrixCommand(commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled", value = "false")
})
public String doHystrix(Integer param) throws Exception {
Thread.sleep(param);
return "1";
}
public String doNative(Integer param) throws Exception {
Thread.sleep(param);
return "1";
}
}
压测数据及解析
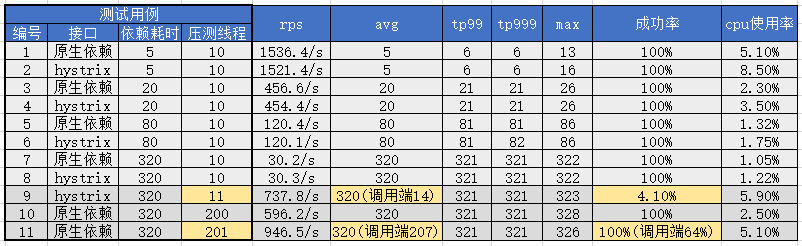
首先前8个用例和结果数据体现了在相同的正常压力下(10线程)不同调用方式和不同性能依赖的吞吐量和性能指标,可以看出:
同样耗时依赖条件下,hystrix会占用更多的cpu资源,但是并不显著,并且当耗时增加时该影响持续减小(由于压测接口无任何计算逻辑因此整体cpu使用很低,推测实际服务逻辑耗费CPU较多时hystrix的性能影响更不明显,有待生产环境验证)。
相同的压测线程(hystrix处理线程也是10)下依赖耗时以及与之对应的平均耗时avg直接影响了接口的吞吐量(rps,每秒请求数)。观察该规律可以得到公式:threads / avg(s) = rps,下面举例:
avg=320时,10 / 0.32 = 31.25,观察用例7,8分别得到原生30.2和hystrix的30.3,基本吻合。
avg=80时,10 / 0.08 = 125,观察用例5,6分别得到原生120.4和hystrix的120.1,有所损耗后吻合。
avg=20时,10 / 0.02 = 500,观察用例3,4分别得到原生456.6和hystrix的454.4,损耗增加。
avg=5时,10 / 0.005 = 2000,观察用例1,2分别得到原生1536.4和hystrix的1521.4,损耗较大。
其他信息:从上面数据也可以看出当rps增加到较高时线程调度本身带来的损耗增加显著,CPU使用率也显著上升,即线程调度压力开始显著增加,无论是否使用hystrix这都是无法避免。hystrix在相同耗时对比中增加部分cpu使用率,对max指标有所影响,个别数据下对tp999也有所影响,但是影响都比较小。
后面三组测试用例则继续提高压测线程,由于hystrix默认配置10个线程,因此当压测超过10个线程时,多出来的请求则会处理不过来,体现为线程池满后直接拒绝,快速返回失败,同时快速返回后压测端又会立刻请求,结果就是rps迅速上升同时成功率急速下降,线程池正常处理的请求则未受影响,用例9体现了这一现象(服务端监控avg=320而客户端由于大量1ms的快速失败返回使avg=14)。
用例10和11是原生调用,我们继续提高压测线程到200和201,以期测试JSF的200线程池,得到结果符合预期,即JSF线程被打满后无法处理额外的请求,与用例9表现相似,但是临界值从10线程到200线程,更多的线程带来了更多吞吐量。还有一点不同的细节在于,hystrix线程满后返回异常时可以触发我们的UMP监控,捕捉到成功率下降,但是JSF线程池满后,直接拒绝请求,服务端无法监控到这些失败,只有调用端能得到成功率下降的信息。
结论
通过上面压测数据解析,我们可以对开始的问题进行解答。
额外的线程池是否有太大的性能开销?
上述测试中hystrix对性能损耗并不大,不管是CPU使用率的增加已经性能指标的影响都不明显,但是由于测试用例的局限性,不能说明所有情况,但我认为达到了到生产环境小范围使用的条件,可以通过继续积累使用经验解答该问题。
The Netflix API processes 10+ billion HystrixCommand executions per day using thread isolation.
Each API instance has 40+ thread-pools with 5-20 threads in each (most are set to 10).
线程池大小设置多少合理?
我们在测试中得到了公式:threads / avg(s) = rps,实际上hystrix的文档中也有一段类似的描述:
requests per second at peak when healthy × 99th percentile latency in seconds + some breathing room
30 rps * 0.2 second = 6 + breaking room = 10 threads
初看这段描述时难以理解,但是通过我们上面的压测数据和公式可以明了,它将avg替换为了tp99,同时再增加了更多余量,以期尽量避免正常流量增长和依赖波动导致线程池被打满的情况。
举一个实际例子,小金库当前并发量最大的接口A,在去年双十一压测中达到了22.6W的RPS(是平时峰值10倍),一共有201台实例,单实例RPS=1124,tp99=6ms(avg=2ms),以此计算 1124 * 0.006 = 6.7,因此增加余量到10(或15)即可满足需求。
新问题,线程池满了怎么办?
在上面测试数据解析中,我们发现由于hystrix为每个依赖严格限制了一个小的线程池,当线程池满了后拒绝服务似乎影响很大。根据我们的公式threads = rps * avg(s),当流量过高时或依赖耗时增加过多时都会触发线程池打满。首先针对流量过高我们可以通过监控报警(主动增加线程数,可以动态配置生效) + 提前预设足够的余量解决。其次针对依赖耗时增加过多的问题,前面的做法也能部分解决该问题,但是回归起点来说,某个依赖突然变得非常慢,以至于打满JSF线程池造成应用整体不可用,这本来就是我们要用hystrix解决的问题,使用hystrix后故障依赖的调用快速失败,同时失败率积累到阈值后断路器熔断降级,在该依赖恢复后自动关闭断路器,恢复对其调用 。
Hystrix压测的更多相关文章
- mysql每秒最多能插入多少条数据 ? 死磕性能压测
前段时间搞优化,最后瓶颈发现都在数据库单点上. 问DBA,给我的写入答案是在1W(机械硬盘)左右. 联想起前几天infoQ上一篇文章说他们最好的硬件写入速度在2W后也无法提高(SSD硬盘) 但这东西感 ...
- Http压测工具wrk使用指南
用过了很多压测工具,却一直没找到中意的那款.最近试了wrk感觉不错,写下这份使用指南给自己备忘用,如果能帮到你,那也很好. 安装 wrk支持大多数类UNIX系统,不支持windows.需要操作系统支持 ...
- 使用mysqlslap对mysql进行压测,观察Azure虚拟机cpu使用率
一直想做这个测试,原因很简单,很多人一直比较怀疑Azure的虚拟机性能,说相同的配置凭啥比阿里的虚拟机贵那么多,其实,我自己以前也怀疑过,但是接触Azure的几个月,确实发现Azure的虚拟机性能真的 ...
- MySQL mysqlslap压测
200 ? "200px" : this.width)!important;} --> 介绍 mysqlslap是mysql自带的一个性能压测工具:mysqlslap用于和其 ...
- 真刀真枪压测:基于TCPCopy的仿真压测方案
郑昀 基于刘勤红和石雍志的实践报告 创建于2015/8/13 最后更新于2015/8/19 关键词:压测.TCPCopy.仿真测试.实时拷贝流量 本文档适用人员:技术人员 提纲: 为什么要做仿真测试 ...
- Netty NIO 框架性能压测-短链接-对比Tomcat
压测方案 准备多个文件大小分别为 1k 10k 100k 300k 使用ab分别按 [50,2000](按50逐渐叠加)压测服务,每次请求10W次 硬件信息:CPU:Intel(R) Xeon(R) ...
- 图解jmeter压测http接口
此次压力测试是以一个http json的后台接口为例. 1. 创建相应的部件 2. 设置相应的参数 线程组主要用于设置一共要测试的线程数量(上图1000),每秒起的线程数(上图10),几秒内启动完单循 ...
- Python Locust对指定网站“一键压测”
[本文出自天外归云的博客园] 前篇 前篇:Python Locust性能测试框架实践 本篇 承上——归纳过程 在前篇的基础上,我们可以利用Locust性能测试框架编写python脚本对指定网站或者接口 ...
- JMeter压测Rest请求
下载及安装 官网下载JMeter3.0: 找到bin目录下的jmeter.bat启动: 压测Rest请求 1.添加线程组 路径:右键“测试计划”->添加“Threads(Users)”-> ...
随机推荐
- ios--->ios消息机制(NSNotification 和 NSNotificationCenter)
问题的背景 IOS中委托模式和消息机制基本上开发中用到的比较多,一般最开始页面传值通过委托实现的比较多,类之间的传值用到的比较多,不过委托相对来说只能是一对一,比如说页面A跳转到页面B,页面的B的值改 ...
- String字符串性能优化的几种方案
String字符串是系统里最常用的类型之一,在系统中占据了很大的内存,因此,高效地使用字符串,对系统的性能有较好的提升. 针对字符串的优化,我在工作与学习过程总结了以下三种方案作分享: 一.优化构建的 ...
- IDEA debug下取消后续操作
有时进行测试时,不想后面的代码执行 具体应该怎么请看下文: 测试代码 public class demo { public static void main(String[] args) { Syst ...
- Java并发专栏
1. Java并发 2. 守护线程与非守护线程 3. 为什么启动线程用start()而不用run()? 4. Java线程join方法总结 5. 生产者与消费者 6. wait.notify/noti ...
- jdk源码Object类解析
一 简介 java.lang.Object,是Java所有类的父类,在你编写一个类的时候,若无指定父类(没有显式extends一个父类),会默认的添加Object为该类的父类. 在JDK 6之前是编译 ...
- windows RabbitMQ安装与配置
windows RabbitMQ安装与配置 1.安装Erlang 下载地址: http://www.erlang.org/downloads 注意: 右键以管理员身份进行安装,否则将导致后续无法启动 ...
- 这个菜鸟花几个小时写的 DEMO 被码云推荐上首页 ?
写在最前 没有接触过 AntV 的诸位看客可通过这篇不成文的文章稍作了解.最近 病毒猖獗,遂抽空做了一个相关小 DEMO.数据可视化方面的使用的是 AntV F2,前端框架使用 Vue 快速成 ...
- systemctl中添加mysql服务
由于mysql的版本更新,许多术语有了新含义,所以需要特别指出,mysqld.service 等价于mysqld vim /usr/lib/systemd/system/mysqld.service ...
- react 获取input的值 ref 和 this.setState({})
1.ref //class my_filter(reg){ const inpVal = this.input.value; console.log(inpVal) ...
- 如何准备Java面试?如何把面试官的提问引导到自己准备好的范围内?
Java能力和面试能力,这是两个方面的技能,可以这样说,如果不准备,一些大神或许也能通过面试,但能力和工资有可能被低估.再仔细分析下原因,面试中问的问题,虽然在职位介绍里已经给出了范围,但针对每个点, ...