Scrapy爬虫基本使用
一、Scrapy爬虫的第一个实例
演示HTML地址
演示HTML页面地址:http://python123.io/ws/demo.html
文件名称:demo.html
产生步骤
步骤1:建议一个Scrapy爬虫工程

生成的工程目录
python123demo/------------------------->外层目录
scrapy.cfg ------------------------->部署Scrapy爬虫的配置文件(将这样的爬虫放大特定的服务器上,并且在服务器配置好相关的操作接口,对于本机使用的爬虫来讲,不需要改变部署的配置文件)
python123demo/------------------->Scrapy框架的用户自定义python代码(Scrapy框架对应的所有文件所在的目录)
__init__.py--------------------->初始化脚本,用户不需要编写
items.py------------------------>Items代码模板(继承类),Items类代码模板,需要继承Scrapy库提供的Item的类,对于一般的例子,不需要用户编写这个文件
middlewares.py-------------->Middlewares代码模板(继续类),用户希望扩展middlewares的功能,需要把这些功能写到这个文件中
pipelines.py------------------->Pipelines代码模板(继承类)
settings.py--------------------->Scrapy爬虫的配置文件,如果希望优化爬虫功能。需要修改settings.py文件中对应的配置项
spiders/------------------------->Spiders代码模板目录(继承类),目录下存放的是python123demo这个工程中所建立的爬虫,其中的爬虫是要符合爬虫模块的约束
__init__.py--------------->初始文件,无需修改
—pycache__/----------->缓存目录,无需修改
步骤2:在工程中产生一个Scrapy爬虫
命令约定用户需要给出爬虫的名字以及所爬取的网站
D:\pycodes>cd python123demo
D:\pycodes\python123demo>scrapy genspider demo python123.io#生成一个名称为demo的spider,也就是一个爬虫
Created spider 'demo' using template 'basic' in module:
python123demo.spiders.demo
查看demo.py文件
# -*- coding: utf-8 -*-
import scrapy class DemoSpider(scrapy.Spider):#这个类必须是继承scrapy.Spider类的子类
name = 'demo'#当前爬虫的名字叫demo
allowed_domains = ['python123.io']#最开始用户提交给命令行的域名,指的这个爬虫在爬取网站的时候,只能爬取这个域名以下的相关文件
start_urls = ['http://python123.io/']#以列表包含的一个或多个url,就是scrapy框架所要爬取页面的初始页面 def parse(self, response):#解析页面的空方法
pass
parse()用于处理响应,他可以解析从网络中爬取的内容,并且形成字典类型,同时还能够对网络中爬取的内容发现其中隐含的新的需要爬取的URL
步骤3:配置产生的spider爬虫
修改demo.py文件,使他能够按照我们的要求去访问我们希望访问的那个链接,并且对相关的链接内容进行爬取
对链接的解析部分定义的功能是将返回的html页面存成文件
# -*- coding: utf-8 -*-
import scrapy class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html'] def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname,'wb') as f:
f.write(response.body)
self.log('Saved file %s.' % name)
步骤4:运行爬虫,获取网页。
D:\pycodes\python123demo>scrapy crawl demo
D:\pycodes\python123demo>scrapy crawl demo
2019-08-06 11:43:58 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: python123demo)
2019-08-06 11:43:58 [scrapy.utils.log] INFO: Versions: lxml 4.2.5.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted 18.9.0, Python 3.6.7 (v3.6.7:6ec5cf24b7, Oct 20 2018, 13:35:33) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0j 20 Nov 2018), cryptography 2.4.2, Platform Windows-10-10.0.17134-SP0
2019-08-06 11:43:58 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'python123demo', 'NEWSPIDER_MODULE': 'python123demo.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['python123demo.spiders']}
2019-08-06 11:43:58 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2019-08-06 11:43:58 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2019-08-06 11:43:58 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2019-08-06 11:43:58 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2019-08-06 11:43:58 [scrapy.core.engine] INFO: Spider opened
2019-08-06 11:43:59 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2019-08-06 11:43:59 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2019-08-06 11:43:59 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://python123.io/robots.txt> from <GET http://python123.io/robots.txt>
2019-08-06 11:44:00 [scrapy.core.engine] DEBUG: Crawled (404) <GET https://python123.io/robots.txt> (referer: None)
2019-08-06 11:44:00 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://python123.io/ws/demo.html> from <GET http://python123.io/ws/demo.html>
2019-08-06 11:44:00 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://python123.io/ws/demo.html> (referer: None)
2019-08-06 11:44:00 [scrapy.core.scraper] ERROR: Spider error processing <GET https://python123.io/ws/demo.html> (referer: None)
Traceback (most recent call last):
File "d:\users\bj\appdata\local\programs\python\python36\lib\site-packages\twisted\internet\defer.py", line 654, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "D:\pycodes\python123demo\python123demo\spiders\demo.py", line 14, in parse
self.log('Saved file %s.' % name)
NameError: name 'name' is not defined
2019-08-06 11:44:00 [scrapy.core.engine] INFO: Closing spider (finished)
2019-08-06 11:44:00 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 888,
'downloader/request_count': 4,
'downloader/request_method_count/GET': 4,
'downloader/response_bytes': 1901,
'downloader/response_count': 4,
'downloader/response_status_count/200': 1,
'downloader/response_status_count/301': 2,
'downloader/response_status_count/404': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2019, 8, 6, 3, 44, 0, 978216),
'log_count/DEBUG': 5,
'log_count/ERROR': 1,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'spider_exceptions/NameError': 1,
'start_time': datetime.datetime(2019, 8, 6, 3, 43, 59, 189943)}
2019-08-06 11:44:00 [scrapy.core.engine] INFO: Spider closed (finished)
二、yield关键字的使用
yield是python3中33个关键字中的一个,也是非常重要的一个关键字
这个关键字与生成器这个概念息息相关
yield<---------------------------------->生成器
生成器是一个不断产生值的函数
包含yield语句的函数是一个生成器
生成器在每次运行的时候,会产生一个值(yield语句),产生值之后,生成器被冻结,直到这个函数被再次唤醒的时候,生成器继续执行,产生一个新的值
生成器唤醒时,所使用的局部变量的值跟之前执行所使用的的值是一致的。
生成器写法
def gen(n):
for i in range(n):
yield i**2
生成器的使用一般与循环搭配在一起,可以用一个for循环来调用生成器
>>> def gen(n):
... for i in range(n):
... yield i**2
...
>>> for i in gen(5):
... print(i," ",end="")
...
0 1 4 9 16
#每次返回一个值,再次被调用时,才产生第二个值,使用的存储空间仍然是一个元素的存储空间
在for循环中,每次调用生成器时,生成器会返回一个值,这个值被打印出来,同时由于for循环产生的循环遍历会把调用gen产生的所有的值都能唤醒一次
普通写法
>>> def square(n):
... ls = [i**2 for i in range(n)]
... return ls
...
>>> for i in square(5):
... print(i," ",end="")
...
0 1 4 9 16
#列表将n=5之内的所有结果存储起来,通过列表返回
为何要有生成器?
生成器相比一次列出所有内容的优势
更节省存储空间
响应更迅速
使用更灵活
三、Scrapy爬虫的基本使用
Scrapy爬虫的使用步骤
步骤1:创建一个工程和Spider模板
步骤2:编写Spider
步骤3:编写Item Pipeline(对Spider提取信息的后续处理做相关的定义)
步骤4:优化配置策略
Scrapy爬虫的数据类型
Request类
class scrapy.http.Request()
Request对象表示一个HTTP请求
由Spider生成,由Downloader执行

Response类
class scrapy.http.Response()
Response对象表示一个HTTP响应。
由Downloader生成,由Spider处理。
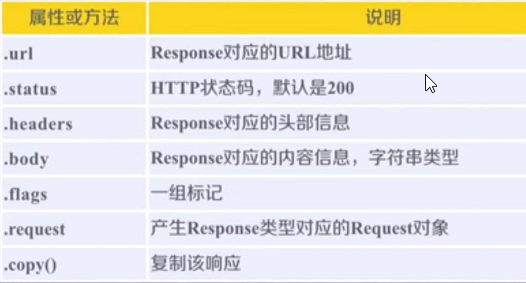
Item类(由Spider产生的信息封装的类)
class scrapy.item.Item()
Item对象表示一个从HTML页面中提取的信息内容
由Spider生成,由Item Pipeline处理
Item类似字典类型,可以按照字典类型操作
Scrapy爬虫提取信息的方法
Scrapy爬虫支持多种HTML信息提取方法
Beautlful Soup
lxml
re
XPath Selector
CSS Selector
CSS Selector的基本使用
<HTML>.css('a::attr(href)').extract() 注:a是标签名字,href标签属性
CSS Selector由W3C组织(是国际公认的,也是比较权威的推进HTML页面标准化的组织)维护并规范
Scrapy爬虫基本使用的更多相关文章
- scrapy爬虫结果插入mysql数据库
1.通过工具创建数据库scrapy
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Linux搭建Scrapy爬虫集成开发环境
安装Python 下载地址:http://www.python.org/, Python 有 Python 2 和 Python 3 两个版本, 语法有些区别,ubuntu上自带了python2.7. ...
- Scrapy 爬虫
Scrapy 爬虫 使用指南 完全教程 scrapy note command 全局命令: startproject :在 project_name 文件夹下创建一个名为 project_name ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- 同时运行多个scrapy爬虫的几种方法(自定义scrapy项目命令)
试想一下,前面做的实验和例子都只有一个spider.然而,现实的开发的爬虫肯定不止一个.既然这样,那么就会有如下几个问题:1.在同一个项目中怎么创建多个爬虫的呢?2.多个爬虫的时候是怎么将他们运行起来 ...
- 如何让你的scrapy爬虫不再被ban之二(利用第三方平台crawlera做scrapy爬虫防屏蔽)
我们在做scrapy爬虫的时候,爬虫经常被ban是常态.然而前面的文章如何让你的scrapy爬虫不再被ban,介绍了scrapy爬虫防屏蔽的各种策略组合.前面采用的是禁用cookies.动态设置use ...
- 如何让你的scrapy爬虫不再被ban
前面用scrapy编写爬虫抓取了自己博客的内容并保存成json格式的数据(scrapy爬虫成长日记之创建工程-抽取数据-保存为json格式的数据)和写入数据库(scrapy爬虫成长日记之将抓取内容写入 ...
- scrapy爬虫成长日记之将抓取内容写入mysql数据库
前面小试了一下scrapy抓取博客园的博客(您可在此查看scrapy爬虫成长日记之创建工程-抽取数据-保存为json格式的数据),但是前面抓取的数据时保存为json格式的文本文件中的.这很显然不满足我 ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
随机推荐
- appium知识点
1 appium元素获取技巧 # 就是页面滑动 driver.swipe(x1, y1, x1, y2, t) # 拿到所有跟元素有关的标签,其实是个列表 driver.find_elements_b ...
- 二叉堆(3)SkewHeap
斜堆. 测试文件 main.cpp: #include <iostream> #include "SkewHeap.h" using std::cout; using ...
- Vue前端挂载对象时一些思考
最近,在Vue前端调试http请求,无论如何如何也是拦截不了某些http请求.场景是这样的:Java后端组装好Vue对象,然后送到前端,前端通过id来挂载该Vue对象,而该对象中有上传文件或者图片的控 ...
- LaTeX绘图
http://math.uchicago.edu/~weinan/programs/tex_diagrams/diagrams.html 给大家分享下这个,用鼠标画diagrams,然后可以一键复制l ...
- 01-SV入门及仿真环境搭建
1.SV入门 参考书籍<SystemVerilog验证 测试平台编写指南> [美]克里斯·斯皮尔 著 2.仿真环境搭建 仿真工具:modelsim se 2019.2,它不仅支持Veril ...
- 简单的登录验证小程序_python
一.要求 输入用户名密码,验证成功之后显示欢迎信息,输错三次后锁定. 程序: #!/usr/bin/env python# _*_ coding:utf-8 _*_#Author:chenxz #将黑 ...
- linux用户管理相关命令
查看用户以及用户组: cat /etc/group [root@izuf60kjjii4iwkhdsly3bz html]# cat /etc/group 内容具体分析 /etc/group ...
- sql 分组后查询出排序字段
select row_number() over(partition by CODE order by SEQUENCE) as RowIndex from Table 注:根据表的CODE 字 ...
- phpstorm同步服务器文件
配置服务器 1.连接配置 打开菜单栏 Tools -> Deployment -> Configuration 点击 + 选择 SFTP,并填写相关服务器信息: Type:连接类型,这里选 ...
- js - 文字
居右 style="float:right;" 文字底部对齐(默认居中对齐) vertical-align:bottom; 文字居中 text-align:middle text- ...