cache和内存屏障
1 cache简介
1.1 cache缓存映射规则
tag查看cache是否匹配,set index
|tag |set index |block offset |
|20-bit |7-bit |5bit |
1.2 cache 组织方式
Cache 全关联
cache 组关联
cache 4路组关联
四路组关联:
cache包括128个cache set(不为0表示组关联,为0表示全关联fully Associative cache)
每个cache set包含四个cache line(四路,同一数据可能在四个cache位置中的一个缓存)
每个cache line是32字节大小
PIPT 物理地址索引物理地址标签
VIPT 虚拟地址索引物理地址标签
VIVT 虚拟地址索引虚拟地址标签
2 Cache-coherency MESI协议
以cache line为最小单元进行一致性内存管理
2.1 MESI协议状态
modified独占&修改过:其他CPU的该cache是无效的、换出该cache需要写回memory
exclusive独占:其他CPU的该cache是无效的、
share共享: 其他CPU的该cache可以是共享的共同读取该cache
Invalid无效: 表示该cache是无效的,需要读入才能生效
2.2 MESI协议消息
read:表示要读取特定cache
read response:其他chache或memory响应read指令。
invalidate:通知其他cpu将cache的数据设置为无效,后续接收所有CPU的invalidate Acknowledge。
invalidate Acknowledge:所有其他cache收到invalidate移除数据后发送的响应指令。
read invalidate:read+invalidate,期望收到read response和所有CPU的invalidate Acknowledge。
writeback:modified状态下的cacheline写回时候发出。
2.3 MESI状态迁移
|
状态转换|目标状态 原状态 |
Modified | Exclusive | Share | Invalid |
| Modified |
M->E 执行writeback操作 将cacheline的数据写回到memory |
M->S 收到read请求 发送read response |
M->I 收到read invalidate请求 发送read response传递最新数据 清除数据 发送invalidate acknowledge |
|
| Exclusive |
E->M cpu将数据写入cacheline |
E->S 收到read请求 发送read response |
E->I 收到read invalidate 发送read response传递最新数据 清除数据 发送invalidate acknowledge |
|
| Share |
S->M 执行一个原子的read-modify-write操作 发送invalidate 接收invalidate acknowledge |
S->E 发送invalidate 接收invalidate acknowledge |
S->I 收到invalidate 清除数据 发送invalidate acknowledge |
|
| Invalid |
I->M 执行一个原子的read-modify-write操作 发送read invalidate 接收read response传递的最新数据 接收invalidate acknowledge |
I->E 发送read invalidate 接收read response传递的最新数据 接收invalidate acknowledge |
I->S 发送read 接收read response传递的最新数据 |
3. MESI协议优化引起的问题
3.1 store buffer的引入
写入内存时如果没有cache,则会先写入到store buffer中
这样可能会引起其他CPU看到的写入顺序与实际的写入顺序不相同的问题。
3.2 invalidate queue的引入
CPU收到invalidate命令后将invalidate存入invalidate queue中直接返回invalidate acknowledge。
会引起read操作读取到的数据已经失效,但是失效命令在invalidate queue中排队。
4 memory barrier
4.1 memory barrier如何解决上一节描述的问题
write memory barrier:标记当前store buffer中的所有项,如果store buffer中有标记项则后续store都会保存在store中,而不会直接写入cache。
执行现象就是CPU一定是先完成wmb之前的store,然后再完成wmb之后的store。
read memory barrier:将Invalidate Queue中的message处理完成。
执行现象就是CPU一定是先完成rmb之前的load,然后再完成rmb之后的load。
4.2 linux 定义的memory barrier
linux定义的互斥原语(spinlocks、reader-writer locks semaphores、RCU。。。)都隐含需要的memory barrier原语。
4.2.1 编译器优化屏障barrier()
主要解决编译器优化重拍的问题
4.2.2 内存优化屏障
内存优化屏障宏内部包含编译器优化屏障,防止编译器对指令进行重排
write memory barrier(smp_wmb())、read memory barrier(smp_rmb())、memory barrier(smp_mb()):
主要用于CPU间的交互顺序保证
smp_read_barrier_depends():表示依赖关系(例如前一个的操作是取后一个要操作memory的地址),只在Alpha上实现不为空。
mmiowb() :保护spin lock保护的MMIO write操作顺序。有些CPU architecture平台中,spinlock中的memory barrier操作已经保证了MMI的写入顺序,那么这个宏是空的。TODO:不理解mmio具体
up版本memory barrier:wmb()、rmb()、mb()、read_barrier_depends()。
主要用于CPU和外设交互时的顺序保证
5 处理器相关
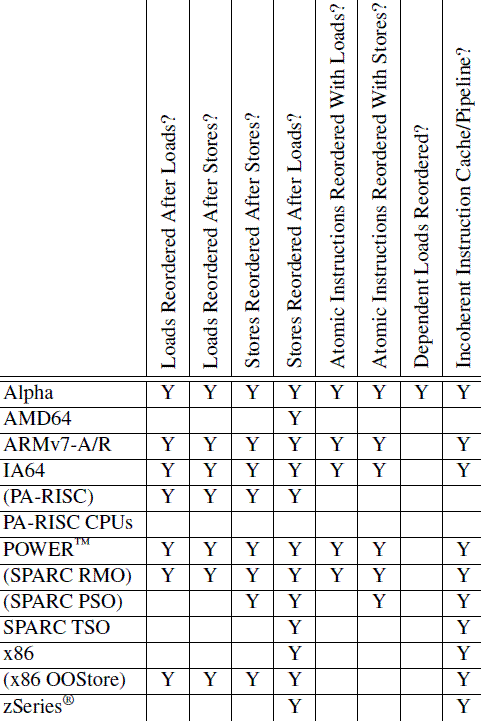
5.1 ARM
DMB(data memory barrier):可以指定内存操作类型(store或store+load)和作用域 (单处理器、一组处理器inner、全局outer),约束观察到的顺序。
DSB(data synchronization barrier):真正对指令执行的约束。
ISB(instruction synchronization barrier):刷新指令缓存,保证之前对指令部分的修改在之后的执行中可见。
参考文献:
http://www.wowotech.net/kernel_synchronization/Why-Memory-Barriers.html
http://www.wowotech.net/kernel_synchronization/why-memory-barrier-2.html
cache和内存屏障的更多相关文章
- JVM内存模型、指令重排、内存屏障概念解析
在高并发模型中,无是面对物理机SMP系统模型,还是面对像JVM的虚拟机多线程并发内存模型,指令重排(编译器.运行时)和内存屏障都是非常重要的概念,因此,搞清楚这些概念和原理很重要.否则,你很难搞清楚哪 ...
- [百度空间] [转]内存屏障 - MemoryBarrier
处理器的乱序和并发执行 目前的高级处理器,为了提高内部逻辑元件的利用率以提高运行速度,通常会采用多指令发射.乱序执行等各种措施.现在普遍使用的一些超标量处理器通常能够在一个指令周期内并发执行多条指令. ...
- [面试]volatile类型修饰符/内存屏障/处理器缓存
volatile类型修饰符 本篇文章的目的是为了自己梳理面试知识点, 在这里做一下笔记. 绝大部分内容是基于这些文章的内容进行了copy+整理: 1. http://www.infoq.com/cn/ ...
- Linux并发与同步专题 (1)原子操作和内存屏障
关键词:. <Linux并发与同步专题 (1)原子操作和内存屏障> <Linux并发与同步专题 (2)spinlock> <Linux并发与同步专题 (3) 信号量> ...
- JVM内存模型、指令重排、内存屏障概念解析(转载)
在高并发模型中,无是面对物理机SMP系统模型,还是面对像JVM的虚拟机多线程并发内存模型,指令重排(编译器.运行时)和内存屏障都是非常重要的概念,因此,搞清楚这些概念和原理很重要.否则,你很难搞清楚哪 ...
- C和C++中的volatile、内存屏障和CPU缓存一致性协议MESI
目录 1. 前言2 2. 结论2 3. volatile应用场景3 4. 内存屏障(Memory Barrier)4 5. setjmp和longjmp4 1) 结果1(非优化编译:g++ -g -o ...
- LINUX内核内存屏障
================= LINUX内核内存屏障 ================= By ...
- CPU缓存和内存屏障
CPU性能优化手段 - 缓存 为了提高程序的运行性能, 现代CPU在很多方面对程序进行了优化例如: CPU高速缓存, 尽可能的避免处理器访问主内存的时间开销, 处理器大多会利用缓存以提高性能 多级缓存 ...
- volatile 和 内存屏障
接下来看看volatile是如何解决上面两个问题的: 被volatile修饰的变量在编译成字节码文件时会多个lock指令,该指令在执行过程中会生成相应的内存屏障,以此来解决可见性跟重排序的问题. 内存 ...
随机推荐
- Nginx配置不同端口号映射二级域名
upstream xx{ #ip_hash; server 127.0.0.1:1008; } server { listen 80; server_name xx.xxx.com; location ...
- ajxa的TypeError: $.ajax is not a function的冲突问题
在加载onclick的方法异步过程中,浏览器报错 首先自我检查 原因一:没有加载Jquery库,原因二:$.ajax没有在$(function(){$.ajax();})中. 发现都不是 原因三:有没 ...
- 第二阶段冲刺个人任务——four
今日任务: 优化统计团队博客结果界面的显示. 昨日成果: 优化统计个人博客结果页面的显示.
- sense8影评摘抄
“卡尔维诺在<为什么读经典>中<西诺拉在月球>一章里如是记述: 月球上的贵族光着身子四处走,仿佛这样还够,他们还在腰间悬挂阳具造型的铜饰.“我觉得这个习俗真是奇特.在我们的世界 ...
- [SDOI2010]魔法猪学院(A*,最短路)
[SDOI2010]魔法猪学院(luogu) Description 题目描述 iPig在假期来到了传说中的魔法猪学院,开始为期两个月的魔法猪训练.经过了一周理论知识和一周基本魔法的学习之后,iPig ...
- jQuery学习总结(三)
这篇文章讲的是jQuery里的ajax发送data的三种方式,利用ajax发送数据的好处是把数据发送到了servlet后,当前页面不进行跳转. jQuery的里的ajax发送data的方式主要有三种, ...
- 数据结构与算法 --- js描述集合
js描述集合 function Set(){ this.datasource=[]; this.add=add; this.remove=remove; //this.size=size; //thi ...
- geoserver wfs属性查询
Geoserver参考连接:http://docs.geoserver.org/latest/en/user/services/wfs/reference.html 使用实例: http://loca ...
- Typora常用快捷键
目录 无序列表:输入-之后输入空格 有序列表:输入数字+"."之后输入空格 任务列表:-[空格]空格 文字 标题:ctrl+数字 表格:ctrl+t 生成目录:按回车 选中一整行: ...
- 实验7:交换机IOS升级
交换机IOS升级首先需要有IOS文件,如果没有备份原文件的话,可以找个同一版本的IOS来替代. 第一种方法:X-Modem 以前我曾经尝试过一种方法,就是当Flash被删除后,启动无法进入系统,可以用 ...