python网络爬虫之解析网页的XPath(爬取Path职位信息)[三]
@
前言
本章同样是解析网页,不过使用的解析技术为XPath。
相对于之前的BeautifulSoup,我感觉还行,也是一个比较常用的一种解析方式
,
并且更加的符合我们之前的一个逻辑思维,不过看情况吧,看各位准备怎么用吧。
XPath的使用方法
同样的先下载lxml插件,并且导入里面的etree
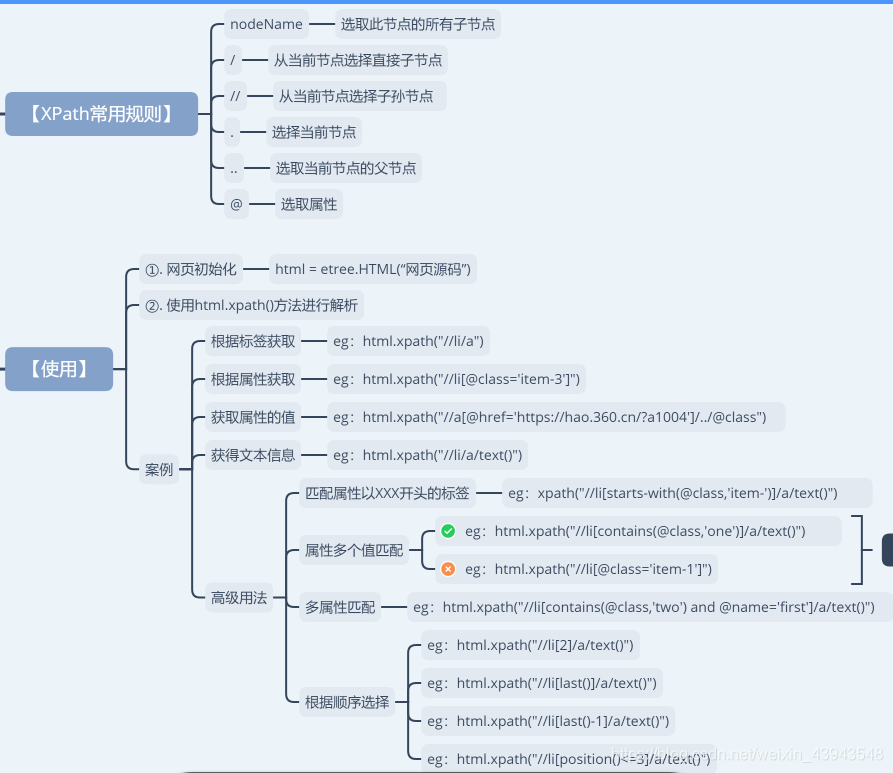
"""
XPath的学习
"""
from lxml import etree
# 案例文件
html_doc = """
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="item-1 one" name="first"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-1 two" name="first"><a href="https://blog.csdn.net/qq_25343557">myblog2</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">bbb</a>
<li class="aaa"><a href="https://hao.360.cn/?a1004">aaa</a>
"""
html = etree.HTML(html_doc)
# 1、获取所有li下的所有a标签
print(html.xpath("//li/a"))
#2、获取指定的li标签item-0
print(html.xpath("//li[@class='item-0']"))
#3、获取指定的li标签item-0下面的a标签
print(html.xpath("//li[@class='item-0']/a"))
#4、获取指定的li标签item-0下面的a标签里面的内容
print(html.xpath("//li[@class='item-0']/a/text()"))
# 高级进阶用法
# 1、匹配属性以什么类型开头的class(starts-with())
print(html.xpath("//li[starts-with(@class,'item-')]"))
# 2、匹配里面所有相同的item-1,(contains())
print(html.xpath("//li[contains(@class,'item-1')]"))
# 3、多属性的匹配(and)
print(html.xpath("//li[contains(@class,'one') and contains(@name,'first')]/a/text()"))
# 4、按顺序来排序
# 第2个
print(html.xpath("//li[2]/a/text()"))
# 最后一个
print(html.xpath("//li[last()]/a/text()"))
# 最后一个-1个
print(html.xpath("//li[last()-1]/a/text()"))
# 小于等于3的序号li
print(html.xpath("//li[position()<=3]/a/text()"))
XPath爬取数据
"""
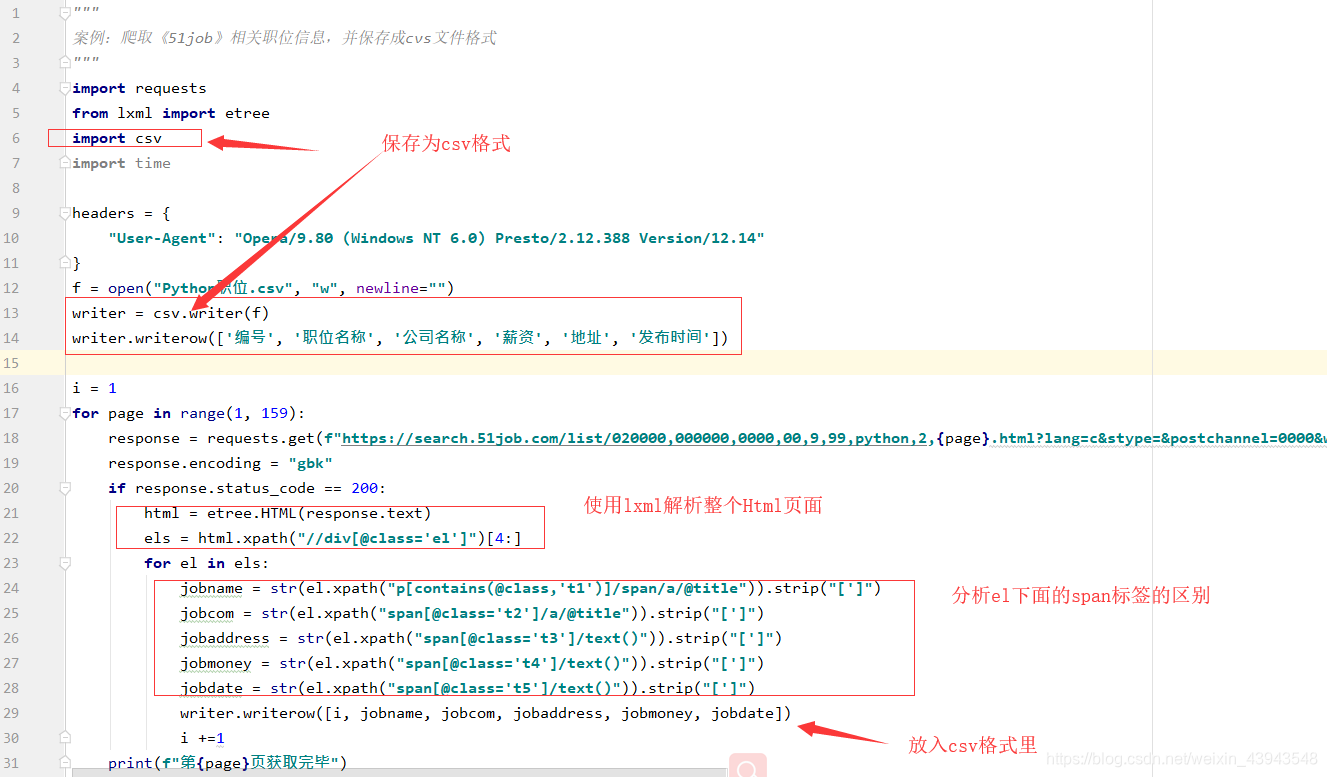
案例:爬取《51job》相关职位信息,并保存成cvs文件格式
"""
import requests
from lxml import etree
import csv
import time
headers = {
"User-Agent": "Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14"
}
f = open("Python职位.csv", "w", newline="")
writer = csv.writer(f)
writer.writerow(['编号', '职位名称', '公司名称', '薪资', '地址', '发布时间'])
i = 1
for page in range(1, 159):
response = requests.get(f"https://search.51job.com/list/020000,000000,0000,00,9,99,python,2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=", headers=headers)
response.encoding = "gbk"
if response.status_code == 200:
html = etree.HTML(response.text)
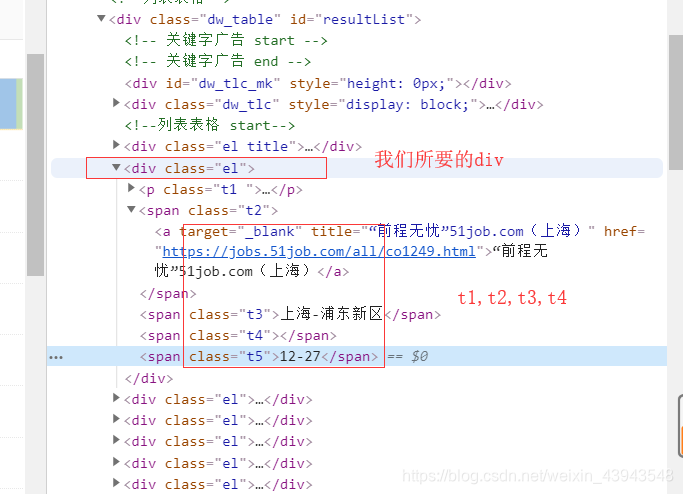
els = html.xpath("//div[@class='el']")[4:]
for el in els:
jobname = str(el.xpath("p[contains(@class,'t1')]/span/a/@title")).strip("[']")
jobcom = str(el.xpath("span[@class='t2']/a/@title")).strip("[']")
jobaddress = str(el.xpath("span[@class='t3']/text()")).strip("[']")
jobmoney = str(el.xpath("span[@class='t4']/text()")).strip("[']")
jobdate = str(el.xpath("span[@class='t5']/text()")).strip("[']")
writer.writerow([i, jobname, jobcom, jobaddress, jobmoney, jobdate])
i +=1
print(f"第{page}页获取完毕")
后言
多学一种解析网页的方式多一种选择
python网络爬虫之解析网页的XPath(爬取Path职位信息)[三]的更多相关文章
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- Python 网络爬虫 007 (编程) 通过网站地图爬取目标站点的所有网页
通过网站地图爬取目标站点的所有网页 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyCharm 2016 ...
- (转)Python网络爬虫实战:世纪佳缘爬取近6万条数据
又是一年双十一了,不知道从什么时候开始,双十一从“光棍节”变成了“双十一购物狂欢节”,最后一个属于单身狗的节日也成功被攻陷,成为了情侣们送礼物秀恩爱的节日. 翻着安静到死寂的聊天列表,我忽然惊醒,不行 ...
- 爬虫系列3:Requests+Xpath 爬取租房网站信息并保存本地
数据保存本地 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 爬虫系列2:https://www ...
- 爬虫系列4:Requests+Xpath 爬取动态数据
爬虫系列4:Requests+Xpath 爬取动态数据 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参 ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
随机推荐
- 实现排行榜神器——redis zset
需求:假如现在需要搞个 “运动消耗卡路里排行榜”,例似微信步数排名,显示排名前20人的信息和消耗的卡里路,怎样实现排序? 一般思路:存储信息,然后数据库查询,排序?(假如有几十万人参与排名,这样查my ...
- 修改centos history记录数上限
修改/etc/profile [root@ ~]# sed -i 's/^HISTSIZE=1000/HISTSIZE=200/' /etc/profile [root@ ~]# source /et ...
- 【C语言】利用递归函数求n的阶乘
递归实现n的阶乘 什么是阶乘:0!= 1,n!=n * (n - 1) * (n - 2)......3 * 2 * 1: 解题思路: 1> 分析题意,很明显0是递归出口: ...
- java基础(七)之子类实例化
知识点;1.生成子类的过程2.使用super调用父类构造函数的方法 首先编写3个文件. Person.java class Person{ String name; int age; Person() ...
- 对C#面向对象三大特性的一点总结
一.三大特性 封装: 把客观事物封装成类,并把类内部的实现隐藏,以保证数据的完整性 继承:通过继承可以复用父类的代码 多态:允许将子对象赋值给父对象的一种能力 二.[封装]特性 把类内部的数据隐藏,不 ...
- C++继承、多态与虚表
继承 继承的一般形式 子类继承父类,是全盘继承,将父类所有的东西都继承给子类,除了父类的生死,就是父类的构造和析构是不能继承的. 继承的访问权限从两方面看: 1.对象:对象只能直接访问类中公有方法和成 ...
- QT+VS中使用qDebug()打印调试信息无法显示
首先右键点击项目名称,找到最后一项属性 然后依次设置为如图所示即可 再次编译后,会弹出CMD窗口,出现qDebug的调试信息.
- python开发基础04-列表、元组、字典操作练习
练习1: # l1 = [11,22,33]# l2 = [22,33,44]# a. 获取内容相同的元素列表# b. 获取 l1 中有, l2 中没有的元素列表# c. 获取 l2 中有, l1 中 ...
- Lenet 神经网络-实现篇(1)
Lenet 神经网络结构为: ①输入为 32*32*1 的图片大小,为单通道的输入: ②进行卷积,卷积核大小为 5*5*1,个数为 6,步长为 1,非全零填充模式: ③将卷积结果通过非线性激活函数: ...
- Kubernetes 与 Helm:使用同一个 Chart 部署多个应用
k8s 集群搭建好了,准备将 docker swarm 上的应用都迁移到 k8s 上,但需要一个一个应用写 yaml 配置文件,不仅要编写 deployment.yaml 还要编写 service.y ...