NLP突破性成果 BERT 模型详细解读 bert参数微调
https://zhuanlan.zhihu.com/p/46997268
NLP突破性成果 BERT 模型详细解读

不懂算法的产品经理不是好的程序员
关注她
82 人赞了该文章
Google发布的论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》,提到的BERT模型刷新了自然语言处理的11项记录。最近在做NLP中问答相关的内容,抽空写了篇论文详细解读。我发现大部分关注人工智能领域的朋友看不懂里面的主要结论,为了让你快速了解论文精髓,这里特地为初学者和刚接触深度学习的朋友们奉上技能点突破roadmap。如果别人写的论文解读你看不懂,代表你需要补充基础知识啦。另外给了主要论文参考,在第五部分,希望对你在NLP领域全面的了解有所帮助。
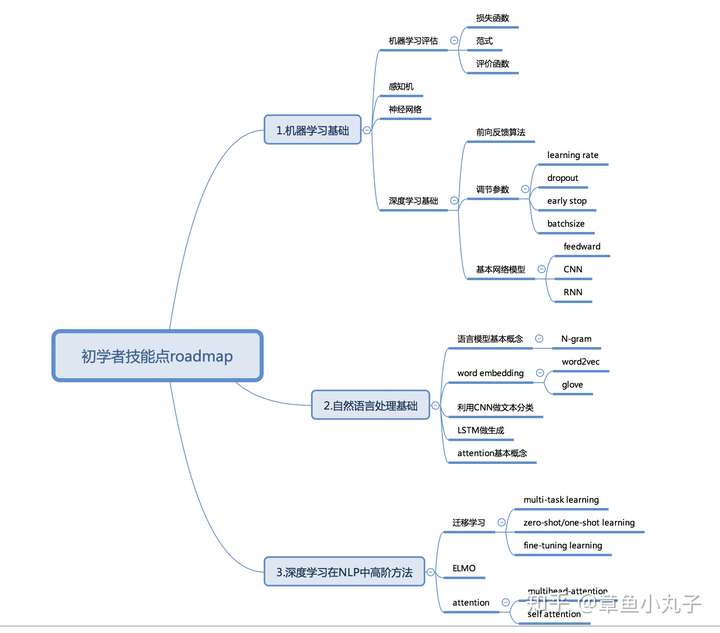
一、 总体介绍
BERT模型实际上是一个语言编码器,把输入的句子或者段落转化成特征向量(embedding)。论文中有两大亮点:1.双向编码器。作者沿用了《attention is all you need》里提到的语言编码器,并提出双向的概念,利用masked语言模型实现双向。2.作者提出了两种预训练的方法Masked语言模型和下一个句子的预测方法。作者认为现在很多语言模型低估了预训练的力量。Masked语言模型比起预测下一个句子的语言模型,多了双向的概念。
二、 模型框架
BERT模型复用OpenAI发布的《Improving Language Understanding with Unsupervised Learning》里的框架,BERT整体模型结构与参数设置都尽量做到OpenAI GPT一样,只在预训练方法做了改造。而GPT让编码器只学习每一个token(单词)与之前的相关内容。
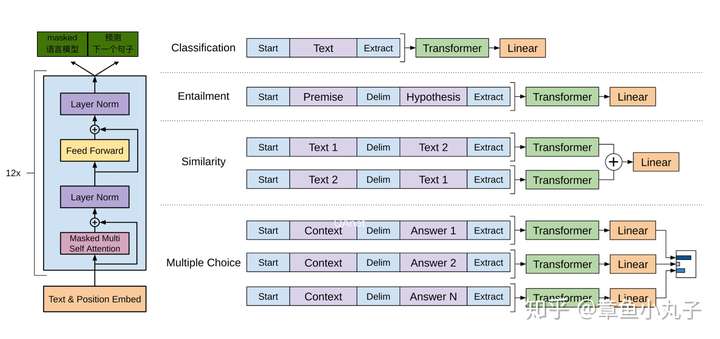
上图是根据OpenAI GPT的架构图做的改动,以便读者更清楚的了解整个过程。
整体分为两个过程:1.预训练过程(左边图)预训练过程是一个multi-task learning,迁移学习的任务,目的是学习输入句子的向量。2微调过程(右边图)可基于少量监督学习样本,加入Feedword神经网络,实现目标。因为微调阶段学习目标由简单的feedward神经网络构成,且用少量标注样本,所以训练时间短。
1.输入表示
对比其他语言模型输入是一个句子或者文档,Bert模型对输入做了更宽泛的定义,输入表示即可以是一个句子也可以一对句子(比如问答和答案组成的问答对)。
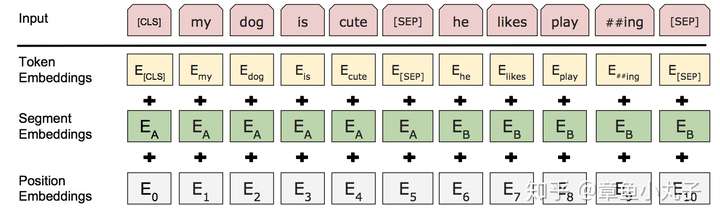
输入表示为每个词对应的词向量,segment向量,位置向量相加而成。(位置向量参考《attention is all you need》)
2.预训练过程-Masked语言模型
Masked语言模型是为了训练深度双向语言表示向量,作者用了一个非常直接的方式,遮住句子里某些单词,让编码器预测这个单词是什么。
训练方法为:作者随机遮住15%的单词作为训练样本。
(1)其中80%用masked token来代替。
(2)10%用随机的一个词来替换。
(3)10%保持这个词不变。
作者在论文中提到这样做的好处是,编码器不知道哪些词需要预测的,哪些词是错误的,因此被迫需要学习每一个token的表示向量。另外作者表示,每个batchsize只有15%的词被遮盖的原因,是性能开销。双向编码器比单项编码器训练要慢。
3.预测下一个句子。
预训练一个二分类的模型,来学习句子之间的关系。预测下一个句子的方法对学习句子之间关系很有帮助。
训练方法:正样本和负样本比例是1:1,50%的句子是正样本,随机选择50%的句子作为负样本。

[CLS]为句子起始符,[MASK]为遮蔽码,[SEP]为分隔符和截止符
4.预训练阶段参数
(1)256个句子作为一个batch,每个句子最多512个token。
(2)迭代100万步。
(3)总共训练样本超过33亿。
(4)迭代40个epochs。
(5)用adam学习率, 1 = 0.9, 2 = 0.999。
(6)学习率头一万步保持固定值,之后线性衰减。
(7)L2衰减,衰减参数为0.01。
(8)drop out设置为0.1。
(9)激活函数用GELU代替RELU。
(10)Bert base版本用了16个TPU,Bert large版本用了64个TPU,训练时间4天完成。
(论文定义了两个版本,一个是base版本,一个是large版本。Large版本(L=24, H=1024, A=16, Total Parameters=340M)。base版本( L=12, H=768, A=12, Total Pa- rameters=110M)。L代表网络层数,H代表隐藏层数,A代表self attention head的数量。)
5.微调阶段
微调阶段根据不同任务使用不同网络模型。在微调阶段,大部分模型的超参数跟预训练时差不多,除了batchsize,学习率,epochs。
训练参数:
Batch size: 16, 32
Learning rate (Adam): 5e-5, 3e-5, 2e-5
Number of epochs: 3, 4
三、实验效果
1.分类数据集上的表现
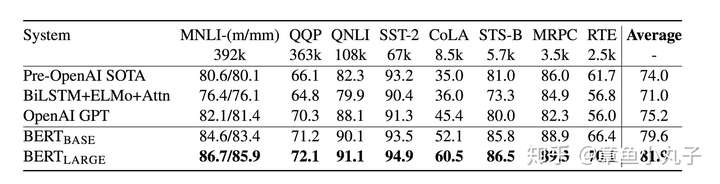
2.问答数据集上的表现
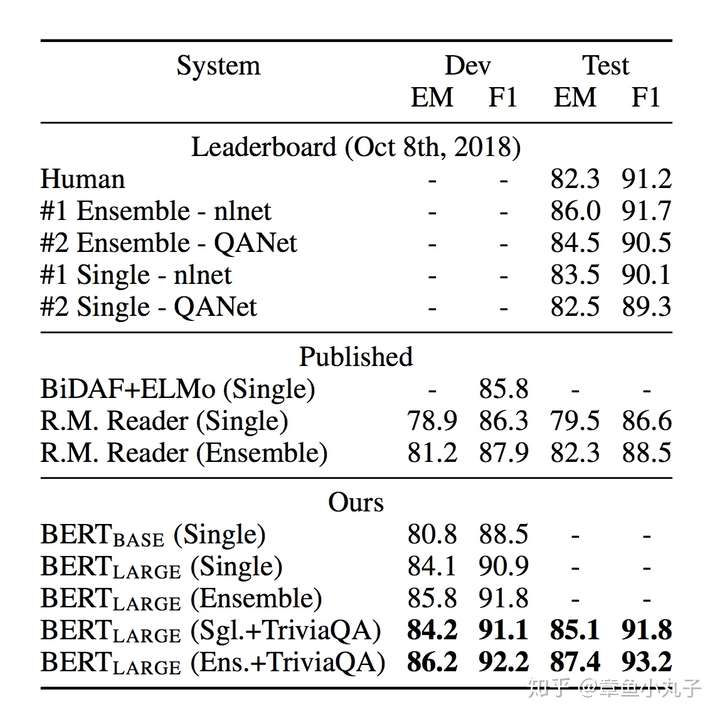
在问答数据集SQuAD v1.1上的表现,TriviaQA是一个问答数据集。EM的基本算法是比较两个字符串的重合率。F1是综合衡量准确率和召回率的一个指标。
3.命名实体识别上的表现
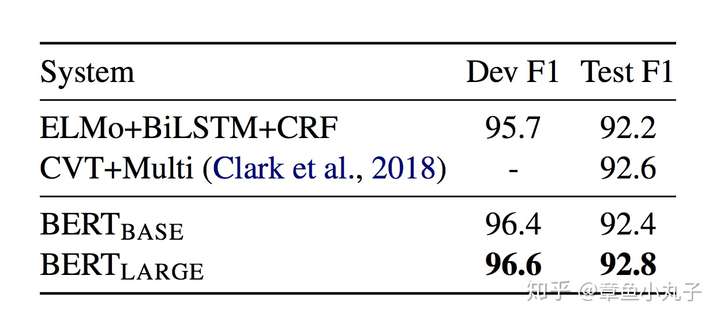
4.常识推理上的表现

四、模型简化测试
Blation study就是为了研究模型中所提出的一些结构是否有效而设计的实验。对该模型推广和工程化部署有极大作用。
1.预训练效果测试
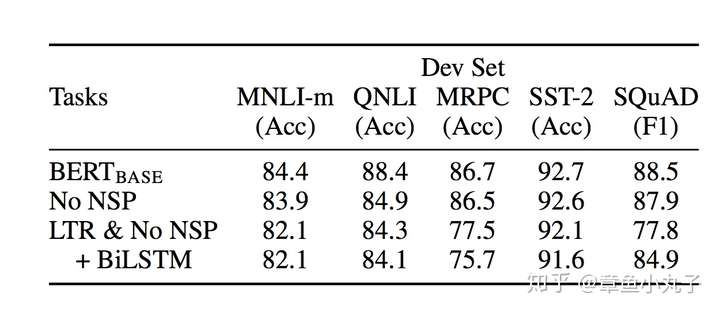
NO NSP: 用masked语言模型,没用下一个句子预测方法(next sentence prediction)
LTR&NO NSP: 用从左到右(LTR)语言模型,没有masked语言模型,没用下一个句子预测方法
+BiLSTM: 加入双向LSTM模型做预训练。
2.模型结构的复杂度对结果的影响
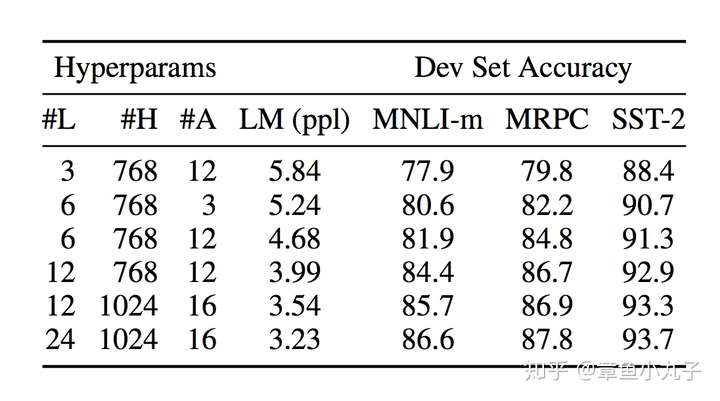
L代表网络层数,H代表隐藏层数,A代表self attention head的数量。
3.预训练中training step对结果的影响

4.基于特征的方法对结果的影响

五、重要参考论文
如何你想了解2017年到2018年NLP领域重要发展趋势,你可以参考以下几篇论文。google直接就可以下载。
《Attention is all you need》2017年NLP领域最重要突破性论文之一。
《Convolutional Sequence to Sequence Learning》2017年NLP领域最重要突破性论文之一。
《Deep contextualized word representations》2018年NAACL最佳论文,大名鼎鼎的ELMO。
《Improving Language Understanding by Generative PreTraining》,OpenAI GPT,Bert模型主要借鉴和比较对象。
《An efficient framework for learning sentence representations》句子向量表示方法。
《Semi-supervised sequence tagging with bidirectional language models》提出双向语言模型。
六、个人观点
个人觉得如果你大概了解近两年NLP的发展的话,BERT模型的突破在情理之中,大多思想是借用前人的突破,比如双向编码器想法是借助这篇论文《Semi-supervised sequence tagging with bidirectional language models》。并且,他提出的一些新的思想,是我们自然而然就会想到的。(十一在家的时候,在做问答模型的时候,我就在想,为什么不能把前一个句子和后一个句子作为标注数据,组成一个二分类模型来训练呢。)
整片论文最有价值的部分,我认为是预训练的两种方法,不需要大量标注数据,在工程实践和一些NLP基础训练中具有很大借鉴意义。
自然语言处理领域2017年和2018年的两个大趋势:一方面,模型从复杂回归到简单。另一方面,迁移学习和半监督学习大热。这两个趋势是NLP从学术界向产业界过渡的苗头,因为现实情况往往是,拿不到大量高质量标注数据,资源设备昂贵解决不了效率问题。
NLP突破性成果 BERT 模型详细解读 bert参数微调的更多相关文章
- [NLP自然语言处理]谷歌BERT模型深度解析
我的机器学习教程「美团」算法工程师带你入门机器学习 已经开始更新了,欢迎大家订阅~ 任何关于算法.编程.AI行业知识或博客内容的问题,可以随时扫码关注公众号「图灵的猫」,加入”学习小组“,沙雕博主 ...
- BERT模型总结
BERT模型总结 前言 BERT是在Google论文<BERT: Pre-training of Deep Bidirectional Transformers for Language U ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- BERT模型
BERT模型是什么 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为de ...
- Bert模型实现垃圾邮件分类
近日,对近些年在NLP领域很火的BERT模型进行了学习,并进行实践.今天在这里做一下笔记. 本篇博客包含下列内容: BERT模型简介 概览 BERT模型结构 BERT项目学习及代码走读 项目基本特性介 ...
- Pytorch | BERT模型实现,提供转换脚本【横扫NLP】
<谷歌终于开源BERT代码:3 亿参数量,机器之心全面解读>,上周推送的这篇文章,全面解读基于TensorFlow实现的BERT代码.现在,PyTorch用户的福利来了:一个名为Huggi ...
- NLP学习(3)---Bert模型
一.BERT模型: 前提:Seq2Seq模型 前提:transformer模型 bert实战教程1 使用BERT生成句向量,BERT做文本分类.文本相似度计算 bert中文分类实践 用bert做中文命 ...
- NLP与深度学习(六)BERT模型的使用
1. 预训练的BERT模型 从头开始训练一个BERT模型是一个成本非常高的工作,所以现在一般是直接去下载已经预训练好的BERT模型.结合迁移学习,实现所要完成的NLP任务.谷歌在github上已经开放 ...
随机推荐
- JZOJ 5459 购物
Description X 城的商场中,有着琳琅满目的各种商品.一日,小X 带着小Y 前来购物,小Y 一共看中了n件商品,每一件商品价格为Pi.小X 现在手中共有m个单位的现金,以及k 张优惠券.小X ...
- webpack学习之—— Plugins
Plugins are the backbone of webpack! webpack 自身也是构建于你在 webpack 配置中用到的相同的插件系统之上! 插件目的在于解决 loader 无法实现 ...
- Codeforces 3D
题目链接 D. Least Cost Bracket Sequence time limit per test 1 second memory limit per test 64 megabytes ...
- 理解async和await
async 是“异步”的简写,而 await 可以认为是 async wait 的简写. 所以应该很好理解 async 用于申明一个 function 是异步的,而 await 用于等待一个异步方法执 ...
- 为什么无法定义1px左右高度的容器
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xht ...
- MySQL——外键
概念 关键字:foreign key,也叫做外键约束! 如果一个实体A的某个字段,刚好指向另一个实体B的主键,那么实体A的这个字段就叫做外键: 所以,简单来说,外键就是本表的某个字段指向外表的主键! ...
- spss命令数据整理中compute与record命令的区别
spss命令数据整理中compute与record命令的区别 record修改存在的变量,或者生成新的变量 spss变量定义说明 1.Name:变量名,定义规则与其它软件中的雷同,如第一个字符必须为字 ...
- TRS OM error
http://192.168.1.1/ http://tplogin.cn/admin888 wddqaz123456789 package="com.trs.om.bean" m ...
- 七.Deque的应用案例-回文检查
- 回文检测:设计程序,检测一个字符串是否为回文. - 回文:回文是一个字符串,读取首尾相同的字符,例如,radar toot madam. - 分析:该问题的解决方案将使用 deque 来存储字符串 ...
- Laravel请求和输入
该篇文章主要介绍Laravel获取用户请求和输入信息的方法.获取基本输入信息: //获取输入数据,不用担心所使用的HTTP方法 $id = Input::get('id'); //可以指定默认值 $i ...