Kudu存储实战笔记
有人会问,为啥要用这个叫啥Kudu的,Kudu是啥?
就像官网所说,Kudu是一个针对Apache hadoop 平台而开发的列式存储管理器,在本菜鸟看来,它是一种介于hdfs与hbase的一种存储。它的优势在于:
1、OLAP工作的快速处理,也就是针对于查询,很快,很牛逼。
2、针对同时运行顺序和随机工作负载的情况性能很好。
3、高可用,Table server和master使用Raft Consensus Algorithm节点来保证高可用,什么是Raft Consunsus Algorith?参考:https://www.cnblogs.com/mindwind/p/5231986.html),只要有一半以上的副本可用,该tablet便可用于读写。
4、结构化数据模型(可以理解为带schema)。
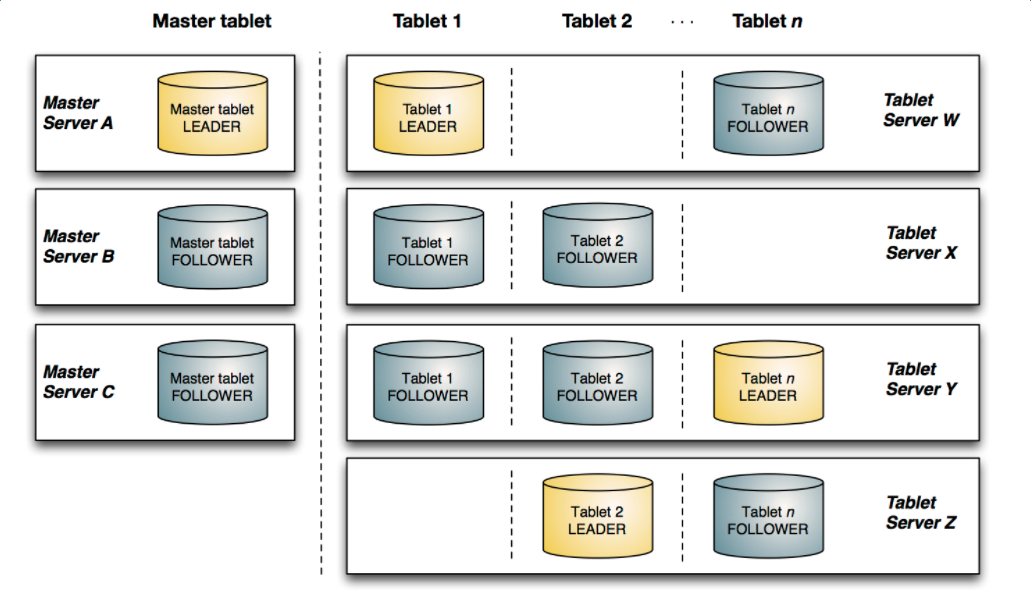
该图显示了一个具有三个 master 和多个 tablet server 的 Kudu 集群,每个服务器都支持多个 tablet。它说明了如何使用 Raft 共识来允许 master 和 tablet server 的 leader 和 f ollow。此外,tablet server 可以成为某些 tablet 的 leader,也可以是其他 tablet 的 follower。leader 以金色显示,而 follower 则显示为蓝色。
下面是一些基本概念:
Table(表)
一张 talbe 是数据存储在 Kudu 的位置。表具有 schema 和全局有序的 primary key(主键)。table 被分成称为 tablets 的 segments。
Tablet
一个 tablet 是一张 table 连续的 segment,与其它数据存储引擎或关系型数据库中的 partition(分区)相似。给定的 tablet 冗余到多个 tablet 服务器上,并且在任何给定的时间点,其中一个副本被认为是 leader tablet。任何副本都可以对读取进行服务,并且写入时需要在为 tablet 服务的一组 tablet server之间达成一致性。
Tablet Server
一个 tablet server 存储 tablet 和为 tablet 向 client 提供服务。对于给定的 tablet,一个 tablet server 充当 leader,其他 tablet server 充当该 tablet 的 follower 副本。只有 leader服务写请求,然而 leader 或 followers 为每个服务提供读请求。leader 使用 Raft Consunsus Algorithm来进行选举 。一个 tablet server 可以服务多个 tablets ,并且一个 tablet 可以被多个 tablet servers 服务着。
具体我还没有那么深入,写了些api调用玩了一把,下面慢慢讲述,Kudu的API比较恶心的哈。。
kudu的sql语法与传统的sql语法比较相似,但也不尽相同,直接解析时,具体sql语法请参考官网,下面以类似hive metastore表结构的方式封装了下。以下列sql为例:
create table combined_t6 (x int64, s string, s2 string, primary key (x, s))
partition by hash (x) partitions 10, range (x)
(
partition 0 <= values <= 49, partition 50 <= values <= 100
) REPLICAS 1
public Boolean create(Table table,String operator) {
LOGGER.info("kudu Table properties:" + table.getKvInfos().toString());
List<ColumnSchema> columns = new ArrayList(table.getTableColumnList().size());
KuduTableGenerateUtil.generateKuduColumn(table.getTableColumnList(),columns);
Schema schema = new Schema(columns);
KuduPartitionSchema kuduPartitionSchema = KuduTableGenerateUtil.parserPartition(table);
CreateTableOptions tableOptions = KuduTableGenerateUtil.generateKuduTableOptions(table,schema,kuduPartitionSchema);
try {
getKuduClient(table).createTable(table.getTableName(), schema,tableOptions);
} catch (KuduException e) {
throw new MetadataInvalidObjectException(e, " create kudu storage table error!!");
}
return true;
}
kudu的column属性中,包含有primarfyKey、encoding、compression algorithm、null table 、default value 、block size等属性,所以从上述代码中需要先将kuduColumn进行封装,构造ColumnSchema对象:
new ColumnSchema.ColumnSchemaBuilder(tableColumn.getColumnName(), getKuduColumnType(tableColumn.getDataType()))
.key(checkBoolKey(columnCondition.get(MetadataConfigKey.COLUMN_KUDU_PRIMARY_KEY)))
.nullable(checkBoolKey(columnCondition.get(MetadataConfigKey.COLUMN_KUDU_SCHEMA_IS_NULLTABLE)))
.defaultValue(defaultValue)
.desiredBlockSize(getDesiredBlockSize(columnCondition.get(MetadataConfigKey.COLUMN_KUDU_SCHEMA_DESIRED_BLOCKSIZE)))
.encoding(getColumnEncoding(columnCondition.get(MetadataConfigKey.COLUMN_KUDU_SCHEMA_ENCODING)))
.compressionAlgorithm(getCompressionType(columnCondition.get(MetadataConfigKey.COLUMN_KUDU_SCHEMA_COMPRESSION_ALGORITHM)))
.build();
对于column的数据类型,有很多种,如下:
private static Type getKuduColumnType(String dataType) {
switch (dataType.toUpperCase()) {
case "INT8":
return Type.INT8;
case "INT16":
return Type.INT16;
case "INT32":
return Type.INT32;
case "INT64":
return Type.INT64;
case "BINARY":
return Type.BINARY;
case "STRING":
return Type.STRING;
case "BOOL":
return Type.BOOL;
case "FLOAT":
return Type.FLOAT;
case "DOUBLE":
return Type.DOUBLE;
case "UNIXTIME_MICROS":
return Type.UNIXTIME_MICROS;
default:
return Type.STRING;
}
}
压缩方式包括:
public static CompressionAlgorithm getCompressionType(String compressionType) {
if (StringUtils.isNotBlank(compressionType)) {
switch (compressionType.toUpperCase()) {
case "UNKNOWN":
return CompressionAlgorithm.UNKNOWN;
case "DEFAULT_COMPRESSION":
return CompressionAlgorithm.DEFAULT_COMPRESSION;
case "NO_COMPRESSION":
return CompressionAlgorithm.NO_COMPRESSION;
case "SNAPPY":
return CompressionAlgorithm.SNAPPY;
case "LZ4":
return CompressionAlgorithm.LZ4;
case "ZLIB":
return CompressionAlgorithm.UNKNOWN.ZLIB;
default:
return null;
}
}
return null;
}
随之我们要构造,Kudu Partition,Kudu Partition包含两种类型,一种是hashPartition,一种是rangePartition,其实从字面意思应该也能够想到,一种是用于对某个字段进行hash散列,一种是进行分区区间的设置,从而在查询时达到优化的效果,这里通过将sql解析后的转换的KuduPartitionSchema对象分别进行range与hash partition的组装,也就是将sql中 Partition表达式 partition 0 <= values <= 49, partition 50 <= values <= 100 封装:
public static void generateHashPartition(CreateTableOptions tableOptions, List<HashPartitionSchema> hashPartitionSchemas) {
if (null != hashPartitionSchemas && hashPartitionSchemas.size() != 0) {
hashPartitionSchemas.forEach(hashPartitionSchema ->{
tableOptions.addHashPartitions(hashPartitionSchema.getColumns(), hashPartitionSchema.getBucket());
});
}
}
public static void generateRangePartition(Schema schema, CreateTableOptions tableOptions, RangePartitionSchema rangePartitionSchema) {
tableOptions.setRangePartitionColumns(rangePartitionSchema.getColumns());
List<RangeSplit> ranges = rangePartitionSchema.getRanges();
ranges.forEach(range -> {
tableOptions.addRangePartition(
getPartialRow(
range.getLower(),
schema,
rangePartitionSchema.getColumns()),
getPartialRow(
range.getUpper(),
schema,
rangePartitionSchema.getColumns()),
getRangePartitionBound(
range.getLowerBoundType()),
getRangePartitionBound(
range.getUpperBoundType())
);
});
}
public static RangePartitionBound getRangePartitionBound(String boundType) {
if (StringUtils.isNotBlank(boundType)) {
switch (boundType) {
case "EXCLUSIVE_BOUND":
return RangePartitionBound.EXCLUSIVE_BOUND;
case "INCLUSIVE_BOUND":
return RangePartitionBound.INCLUSIVE_BOUND;
default:
return null;
}
}
return null;
}
最后构造,CreateTableOptions对象:
public static CreateTableOptions generateKuduTableOptions(Table table, Schema schema, KuduPartitionSchema kuduPartitionSchema) {
CreateTableOptions tableOptions = new CreateTableOptions();
String numReplicas = table.getKvInfos().get(MetadataConfigKey.TABLE_KUDU_REPLICAS);
if (StringUtils.isNotBlank(numReplicas)) {
tableOptions.setNumReplicas(Integer.valueOf(numReplicas));
}
if (kuduPartitionSchema.getHashPartitionSchemaList() != null && kuduPartitionSchema.getHashPartitionSchemaList().size() != 0) {
generateHashPartition(tableOptions, kuduPartitionSchema.getHashPartitionSchemaList());
}
if (kuduPartitionSchema.getRangePartitionSchema() != null) {
generateRangePartition(schema, tableOptions, kuduPartitionSchema.getRangePartitionSchema());
}
return tableOptions;
}
没有hbase编程便捷。。不过对于kudu的连接而言,只需要配置kudu master的地址,便可创建连接。
public KuduClient getKuduClient(Table table){
if(null == kuduClient){
try{
String kuduMaster = table.getStorageClusterKvs().get(MetadataConfigKey.CLUSTER_KUDU_MASTER);
kuduClient = new KuduClient.KuduClientBuilder(kuduMaster).build();
}catch(Exception e){
throw new MetadataRuntimeException(e, " create kuduClient error!!");
}
}
return kuduClient;
}
活儿干不完啊~改天再深入完 哈哈~
Kudu存储实战笔记的更多相关文章
- 机器学习实战笔记-k-近邻算法
机器学习实战笔记-k-近邻算法 目录 1. k-近邻算法概述 2. 示例:使用k-近邻算法改进约会网站的配对效果 3. 示例:手写识别系统 4. 小结 本章介绍了<机器学习实战>这本书中的 ...
- mysql颠覆实战笔记(五)--商品系统设计(二):定时更新商品总点击量
继续回到沈老师的MYSQL颠覆实战,首先回顾下上一节课的内容,请大家会看下上节课写的存储过程. 打开prod_clicklog表, 我们只要把日期(不含时分秒)的部分存在数据库中, 如果同一日期有相同 ...
- mysql颠覆实战笔记(四)--商品系统设计(一):商品主表设计
版权声明:笔记整理者亡命小卒热爱自由,崇尚分享.但是本笔记源自www.jtthink.com(程序员在囧途)沈逸老师的<web级mysql颠覆实战课程 >.如需转载请尊重老师劳动,保留沈逸 ...
- mysql颠覆实战笔记(一)--设计一个项目需求,灌入一万数据先
版权声明:笔记整理者亡命小卒热爱自由,崇尚分享.但是本笔记源自www.jtthink.com(程序员在囧途)沈逸老师的<web级mysql颠覆实战课程 >.如需转载请尊重老师劳动,保留沈逸 ...
- mysql颠覆实战笔记(七)--白话理解事务
今天我们学习web开发级mysql颠覆实战课程第9课没MYSQL事务(一):白话理解事务.前面有两节课第7讲:商品系统设计(四):商品属性设计之自定义属性,第8讲:商品系统设计(五):一维属性的商品价 ...
- mysql颠覆实战笔记(六)--商品系统设计(三):商品属性设计之固定属性
今天我们来讲一下商品属性 我们知道,不同类别的商品属性是不同的. 我们先建一个表prod_class_attr:
- mysql颠覆实战笔记(三)-- 用户登录(二):保存用户操作日志的方法
版权声明:笔记整理者亡命小卒热爱自由,崇尚分享.但是本笔记源自www.jtthink.com(程序员在囧途)沈逸老师的<web级mysql颠覆实战课程 >.如需转载请尊重老师劳动,保留沈逸 ...
- mysql颠覆实战笔记(二)-- 用户登录(一):唯一索引的妙用
版权声明:笔记整理者亡命小卒热爱自由,崇尚分享.但是本笔记源自www.jtthink.com(程序员在囧途)沈逸老师的<web级mysql颠覆实战课程 >.如需转载请尊重老师劳动,保留沈逸 ...
- Unity3D项目实战笔记(10):Unity3D编译IPA的PostEvents–节约时间利器
最近,SDK支付等接入差不多了,就从Unity3D生成IPA (企业版License), 然,需要手动执行的PostEvents竟然多大10项+, 这些我默默的承受了1周时间,每次约浪费20分钟-额外 ...
随机推荐
- 【JDBC】Java 连接 MySQL 基本过程以及封装数据库工具类
一. 常用的JDBC API 1. DriverManager类 : 数据库管理类,用于管理一组JDBC驱动程序的基本服务.应用程序和数据库之间可以通过此类建立连接.常用的静态方法如下 static ...
- 【开发技术】JAutodoc使用指南
JAutodoc使用指南 下载地址:http://sourceforge.net/projects/jautodoc/?source=directory 使用方法:http://wenku.baidu ...
- windows安装xampp时出现,unable to realloc xxxxxxxx bytes
摘录自:http://blog.csdn.net/lz610756247/article/details/70842166 Windows虚拟内存的设置 问题描述:由于开启虚拟内存会导致硬盘IO性能下 ...
- java实现最小生成树的prim算法和kruskal算法
在边赋权图中,权值总和最小的生成树称为最小生成树.构造最小生成树有两种算法,分别是prim算法和kruskal算法.在边赋权图中,如下图所示: 在上述赋权图中,可以看到图的顶点编号和顶点之间邻接边的权 ...
- -------- ROOTKIT 核心技术——系统服务调度表挂钩调试(PART III) --------
---------------------------------------------------------------------------------------- 本篇开始进行真枪实弹的 ...
- 简单的线性规划-scipy
根据描述,我们用线性规划带约束来求解问题 # coding=utf-8 from scipy.optimize import linprog import numpy as np def maxGai ...
- 用Python实现几种排序算法
#coding=utf-8 # 1 快速排序算法 def qksort(list): if len(list)<=1: return list else: pivot = list[0] les ...
- XML,HTML,XHTML
对于上面3种技术,我们经常使用到,这里具体的做一个总结,来对比一下这3个东西. 什么是XML? XML即Extentsible Markup Language(可扩展标记语言),是用来定义其它语言的一 ...
- Spring MVC 基础笔记
spring mvc功能: 以Controller为中心完成对系统流程的控制管理 从请求中搜集数据 对传入的参数进行验证 将结果返回给视图 针对不同的视图提供不同的解决方案 针对jsp视图技术提供标签 ...
- docker入门(一)
1. Docker是什么? 官方的解释地址: Docker是一个开源的引擎,可以轻松的为任何应用创建一个轻量级的.可移植的.自给自足的容器.开发者在笔记本上编译测试通过的容器可以批量地在生产环境中部署 ...