API做翻页的两种思路
在开发API的时候,有时候数据太多了,就需要分页读取。
基于偏移量的分页(Offset-based)
这种方式就是会提供一个每页笔数(page size)来定义返回条目的最大数,提供一个页数(page number)来表示从哪里开始读取数据。
例如:
SELECT * FROM "CampusResumes" ORDER BY "Name" DESC LIMIT 5 OFFSET 10;
这句话的意思就是从该表中读取数据,按照Name字段降序排序,从第10笔数据后开始读取,一共读取5笔(可能不足5笔)。
这就相当于page size = 5,page number = 3的分页读取。
Offset-based分页方式实现起来非常的简单,对用户来说体验也比较好。但是还有有一些劣势的:
- 对于大规模的数据集,效率不够高。因为数据库需要进行count和skip操作。
- 如果数据经常发生变化,那么结果不可信。在查询的时候如果插入或删除了数据,那么某条数据可能会出现两次或者翻页的时候越界了。
- 在分布式系统中实现起来略麻烦。这种情况下,你可能需要扫描不同的数据碎片,然后才能得到想要的数据。
总体来说,当允许结果出现误差的时候,Offset-based分页还是很好用的。
基于游标的分页(Cursor-based)
为了解决Offset-based分页的那些问题,可以采用Cursor-based分页。
这种方式是这样的:客户端首先发送请求,请求里提供所需数据的数量。然后服务器响应请求,返回这些数量的数据(如果有这么多数据的话),同时还会返回一个游标(Cursor)。在下一次请求中,客户端除了发送请求数据的数量之外,还把这个cursor也传送过去,这个cursor就表示这次所要读取的数据的开始位置。
这看起来和Offset-based分页差别不大,但是却更有效率。数据库里面的数据可以根据cursor值来获取。
例如:
SELECT * FROM "CampusResumes" WHERE "Id" > 15 ORDER BY "Id" LIMIT 5;
这个例子里,上次请求返回的cursor(Id字段)值为15,这次要获取Id比15大的连续的5条数据。
这里的Id字段本身就是一个索引,所以查询起来非常快。
在这次请求的响应里,可以把本次结果的最后一条的Id作为cursor再返回去:
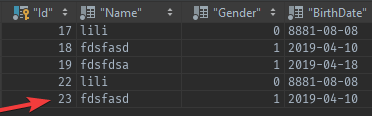
所以返回的cursor值为23,以供下次读取。
Cursor-based翻页的优点是:
- 性能好。因为cursor字段通常都是索引列,查起来很快。
- 一致性。添加和删除数据并不影响返回的结果,翻页时同一笔数据也只会被返回一次。
Cursor-based翻页通常适用于大量和动态的数据集,但是它也有一些缺点:
- 无法跳转到指定的页。Cursor-based翻页只能一页一页遍历结果。
- 结果必须基于一个唯一并且顺序的字段。不可以让添加记录到任意位置。
- 实现起来比Offset-based复杂一点,尤其对客户端来说。
对于Cursor字段的选择:
- Id,顺序的主键。
- 时间戳。
- 加密字符串。它们看起来像随机字符串,但实际上通常是Cursor里加入了额外的信息。
总体来说Cursor-based翻页还是更适合于高吞吐的应用,这种情况下客户端通常需要扫描整个数据集。
翻页的最佳实践
- 设定每页的最大笔数限制。
- 针对大数据集,尽量不要使用Offset-based分页。
- 分页的默认排序,通常会把新的数据先返回,旧的数据往后翻。
- 没分页的API尽量去实现分页。
- 分页的时候,最好把下一页的链接一同返回,并鼓励客户端使用这个链接,参考HATEOAS。这样以后你改变翻页策略的时候,客户端不会爆掉。
- 不要在Cursor里加入敏感信息。
API做翻页的两种思路的更多相关文章
- 把JSON数据载入到页面表单的两种思路(对easyui自带方法进行改进)
#把JSON数据载入到页面表单的两种思路(对easyui自带方法进行改进) ##背景 项目中经常需要把JSON数据填充到页面表单,一开始我使用easyui自带的form load方法,觉得效率很低,经 ...
- 点击页面div弹窗以外隐藏的两种思路
在本文为大家介绍两种思路实现点击页面其它地方隐藏该div,第一种是对document的click事件绑定事件处理程序.. 第一种思路分两步 第一步:对document的click事件绑定事件处理程序, ...
- 使用 CUDA 进行计算优化的两种思路
前言 本文讨论如何使用 CUDA 对代码进行并行优化,并给出不同并行思路对均值滤波的实现. 并行优化的两种思路 思路1: global 函数 在 global 函数中创建出多个块多个线程对矩阵每个元素 ...
- C++关于数字逆序输出的两种思路,及字符串逆序输出
C++关于数字逆序输出的两种思路,及字符串逆序输出 作者:GREATCOFFEE 发布时间:NOVEMBER 15, 2012 分类:编程的艺术 最近在跟女神一起学C++(其实我是不怀好意),然后女神 ...
- 第七篇:使用 CUDA 进行计算优化的两种思路
前言 本文讨论如何使用 CUDA 对代码进行并行优化,并给出不同并行思路对均值滤波的实现. 并行优化的两种思路 思路1: global 函数 在 global 函数中创建出多个块多个线程对矩阵每个元素 ...
- Java实现快排+小坑+partition的两种思路
在做一道剑指Offer的题的时候,有道题涉及到快排的思路,一开始就很快根据以前的思路写出了代码,但似乎有些细节不太对劲,自己拿数据试了下果然.然后折腾了下并记录下一些小坑,还有总结下划分方法parti ...
- php 冒泡排序的两种思路以及优化
php冒泡排序,两种思路,时间复杂度都是O(n^2),当然最优的时间复杂度就是O(n),以下说的都是正序排列(倒序的话,把内层循环的大于号换成小于号就好了) 第一种冒泡排序 思路就是把第一个数跟所有的 ...
- 点击页面其它地方隐藏该div的两种思路
思路一 第一种思路分两步 第一步:对document的click事件绑定事件处理程序,使其隐藏该div 第二步:对div的click事件绑定事件处理程序,阻止事件冒泡,防止其冒泡到document,而 ...
- 对抗栈帧地址随机化/ASLR的两种思路和一些技巧
栈帧地址随机化是地址空间布局随机化(Address space layout randomization,ASLR)的一种,它实现了栈帧起始地址一定程度上的随机化,令攻击者难以猜测需要攻击位置的地址. ...
随机推荐
- 推荐Python、Django中文文档地址
协作翻译网:http://usyiyi.cn/ 老牌的Python中文社区:http://woodpecker.org.cn/ The Django Book2.0中文版:http://djangob ...
- 使用 Babylon.js 在 HTML 页面加载 3D 对象
五一 Windwos Blogs 推了一篇博客, Babylon.js v3.2 发布了.因为一直有想要在自己博客上加载 3D 对象的冲动,这两天正好看到了,就动手研究研究.本人之前也并没有接触过 W ...
- Scala编程入门---函数式编程
高阶函数 Scala中,由于函数时一等公民,因此可以直接将某个函数传入其他函数,作为参数.这个功能是极其强大的,也是Java这种面向对象的编程语言所不具备的. 接收其他函数作为函数参数的函数,也被称作 ...
- 分享一下 常用的转换方法(例如:数字转金钱,文本与html互转等)
public sealed class SAFCFormater { /// <summary> /// 文本格式到HTML /// </summary> /// <pa ...
- 关于overflow的问题
<head> <title></title> <style type="text/css"> body { margin: 0; p ...
- zfs文件系统简单使用
关于ubuntu下zfs的使用参考:https://github.com/zfsonlinux/zfs/wiki/Ubuntu%2016.04%20Root%20on%20ZFS 安装zfs: 启动z ...
- Selenium2Lib库之操作浏览器相关的关键字实战
1.1 操作浏览器相关的关键字 Selenium2Lib提供了与浏览器交互的关键词 1.1.1 Open Browser关键字 按F5 查看Open Browser关键字的说明,如下图: Open ...
- 杨老师课堂之JavaScript定时器_农夫山泉限时秒杀案例
预览效果图: 使用到的知识点: 定时器 setInterval(函数,毫秒):在指定的毫秒数后调用函数或执行一段代码 取消定时器 clearInterval:取消由setInterval设置的定时器 ...
- Oracle数据库查询优化方案(处理上百万级记录如何提高处理查询速度)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引.2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引 ...
- PAT1120: Friend Numbers
1120. Friend Numbers (20) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue Two in ...