[论文阅读] ImageNet Classification with Deep Convolutional Neural Networks(传说中的AlexNet)
这篇文章使用的AlexNet网络,在2012年的ImageNet(ILSVRC-2012)竞赛中获得第一名,top-5的测试误差为15.3%,相比于第二名26.2%的误差降低了不少。
本文的创新点:
1) 训练了(当时)最大的一个卷积神经网络,在ImageNet数据集上取得(当时)最好的结果;
2) 写了一个高度优化的GPU实现的2维卷积;
3) 包含了一些新的特点,来提高网络的泛化能力和减少网络的训练时间
4) 使用了一些有效的方法来减轻过拟合;
5) 网络使用了5层卷积层和3层全连接层,如果减少任何一个卷积层,效果将会变差
数据集
使用的数据集为ImageNet数据集。
预处理:将所有图片大小调整为固定分辨率256x256,对于长方形的图片,首先将短边大小调整为256,然后再从中间区域裁剪出256x256大小的图片。
(每张图片)subtracting the mean activity over the training set from each pixel. So we trained our network on the (centered) raw RGB values of the pixels.
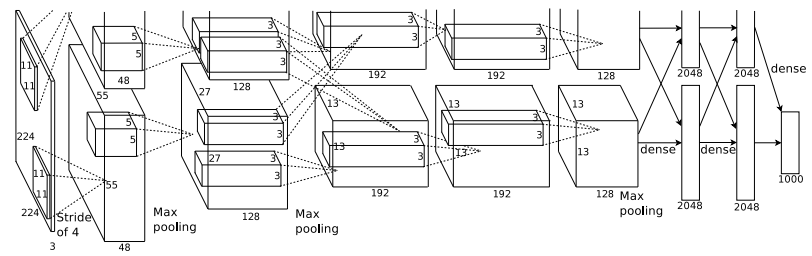
当时由于GPU性能的限制,所有使用了两个GPU进行训练。上面的结果比较简略,省略了一些细节。
完整的AlexNet网络结构如下:
[227x227x3] INPUT
[55x55x96] CONV1: 96 11x11 filters at stride 4, pad 0 注:(227 - 11)/ 4 + 1 = 55
[55x55x96] RELU1: activation
[27x27x96] MAX POOL1: 3x3 filters at stride 2 注:(55 - 3)/ 2 + 1 = 27
[27x27x96] NORM1: Normalization layer
[27x27x256] CONV2: 256 5x5 filters at stride 1, pad 2 注:(27+2x2-5)/ 1 + 1 = 27
[27x27x256] RELU2: activation
[13x13x256] MAX POOL2: 3x3 filters at stride 2 注:(27-3)/ 2 + 1 = 13
[13x13x256] NORM2: Normalization layer
[13x13x384] CONV3: 384 3x3 filters at stride 1, pad 1 注:(13+1x2-3)/ 1 + 1 = 13
[13x13x384] RELU3: activation
[13x13x384] CONV4: 384 3x3 filters at stride 1, pad 1 注:(13+1x2-3)/ 1 + 1 = 13
[13x13x384] RELU4: activation
[13x13x256] CONV5: 256 3x3 filters at stride 1, pad 1 注:(13+1x2-3)/ 1 + 1 = 13
[13x13x256] RELU5: activation
[6x6x256] MAX POOL3: 3x3 filters at stride 2 注:(13-3)/ 2 + 1 = 6
[4096] FC6: 4096 neurons
[4096] RELU6: activation
[4096] DROPOUT
[4096] FC7: 4096 neurons
[4096] RELU7: activation
[4096] DROPOUT
[1000] FC8: 1000 neurons (class scores)
网络的一些重要的特点
ReLU
ReLU全称为Rectified Linear Units。计算公式为f(x) = max(0, x)。相比于sigmoid和tanh激活函数,ReLU可以加快网络收敛速度,减少训练时间。
Local Response Normalization(局部响应归一化)
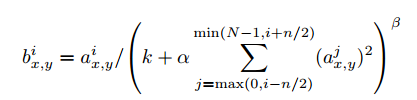
其中a是每一个神经元的激活,即第i个kernel map中(x, y)坐标的值,n是在同一个位置上临近的kernel map的数目,N是kernel的总数目,k,alpha,beta都是预设的一些hyper-parameters,其中k=2,n=5,alpha = 1*e-4,beta = 0.75,这些值都是在验证集上测试得到的。
好处:有利于增加泛化能力,做了平滑处理,识别率提高了1~2%。LRN层模仿生物神经系统的侧抑制机制,对局部神经元的活动创建竞争机制,使得响应比较大的值相对更大,提高模型的泛化能力。
重叠池化
pooling区域为z*z=3*3,间隔距离为s=2.对比z=2,s=2的无重叠方式;使用重叠pooling,不容易过拟合。
减少过拟合
数据增强
第一种方法是,从256x256图像(包括原图像和水平镜像后的图像)中随机地裁剪出224x224的patch,然后对这些224x224的patch送入网络进行训练(这就是网络为什么使用224x224x3作为输入大小的原因)。这种方法可以使得数据增加2048倍。
在测试的时候,将预测的图片(和其水平镜像的图片)上下左右四个角落,中间裁取5x2=10个patch,送入网络进行预测,最后取这10个结果的平均值。
第二种方法是,改变训练图像中RGB通道的强度。对于每个训练图像,我们成倍增加已有主成分,比例大小为对应特征值乘以一个从均值为0,标准差为0.1的高斯分布中提取的随机变量。在训练集像素值的RGB颜色空间进行PCA, 得到RGB空间的3个主方向向量(特征向量),3个特征值, p1, p2, p3, λ1, λ2, λ3. 对每幅图像的每个像素Ixy=[IRxy,IGxy,IBxy]T进行加上如下的变化:
[p1,p2,p3][α1λ1,α2λ2,α3λ3]T
其中,αi是均值为0,标准差为0.1的高斯分布中的一个随机变量。
Dropout
以0.5的概率将每个隐层神经元的输出设置为零。这些被“dropped out”的神经元既不会在前向传播起作用,也不会参与反向传播。因此,每次进行一次输入,整个网络都会改变一次结构,但是这些所有的结构的权值是共享的。由于每个神经元不能依赖其他特定的神经元,因此,会强迫网络学习更加鲁棒的特征。测试的时候,会使用每个神经元,但是会将其权值乘以0.5。
本文只在在第一个全连接层和第二个全连接层使用dropout。
训练细节
使用随机梯度下降法(SGD)进行训练,batch size为128,momentum为0.9,weight decay为0.0005(weight decay很重要,不仅仅是正则化,还可以减少模型训练误差)。
权重w的更新公式为:
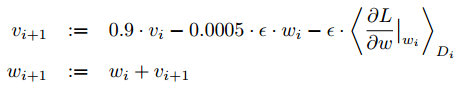
其中,i是迭代次数,v是momentum变量,是学习率, 是第i个batch(称为Di)对w的平均偏导数。
是第i个batch(称为Di)对w的平均偏导数。
每一层的weight初始化方法为:均值为0,标准差为0.01的高斯分布。第2,4,5层的卷积层和3个全连接层的bias初始化都设置为1,其余层的bias初始化为0。这样设置初始化参数可以加速收敛。
对于学习率的设置,每一层的学习率相同,学习率初始化为0.01,后面的时候,当模型在验证集的误差不变时,将当前的学习率除以10,然后再接着训练。我们120万的训练集上训练了90次。
[论文阅读] ImageNet Classification with Deep Convolutional Neural Networks(传说中的AlexNet)的更多相关文章
- AlexNet论文翻译-ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks 深度卷积神经网络的ImageNet分类 Alex Krizhevsky ...
- 《ImageNet Classification with Deep Convolutional Neural Networks》 剖析
<ImageNet Classification with Deep Convolutional Neural Networks> 剖析 CNN 领域的经典之作, 作者训练了一个面向数量为 ...
- ImageNet Classification with Deep Convolutional Neural Networks(译文)转载
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geo ...
- 中文版 ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks 摘要 我们训练了一个大型深度卷积神经网络来将ImageNet LSVRC ...
- 论文阅读笔记二-ImageNet Classification with Deep Convolutional Neural Networks
分类的数据大小:1.2million 张,包括1000个类别. 网络结构:60million个参数,650,000个神经元.网络由5层卷积层,其中由最大值池化层和三个1000输出的(与图片的类别数相同 ...
- ImageNet Classification with Deep Convolutional Neural Networks 论文解读
这个论文应该算是把深度学习应用到图片识别(ILSVRC,ImageNet large-scale Visual Recognition Challenge)上的具有重大意义的一篇文章.因为在之前,人们 ...
- 论文解读《ImageNet Classification with Deep Convolutional Neural Networks》
这篇论文提出了AlexNet,奠定了深度学习在CV领域中的地位. 1. ReLu激活函数 2. Dropout 3. 数据增强 网络的架构如图所示 包含八个学习层:五个卷积神经网络和三个全连接网络,并 ...
- 阅读笔记:ImageNet Classification with Deep Convolutional Neural Networks
概要: 本文中的Alexnet神经网络在LSVRC-2010图像分类比赛中得到了第一名和第五名,将120万高分辨率的图像分到1000不同的类别中,分类结果比以往的神经网络的分类都要好.为了训练更快,使 ...
- AlexNet——ImageNet Classification with Deep Convolutional Neural Networks
1. 摘要 本文的模型采用了 5 层的卷积,一些层后面还紧跟着最大池化层,和 3 层的全连接,最后是一个 1000 维的 softmax 来进行分类. 为了减少过拟合,在全连接层采取了 dropout ...
随机推荐
- JAVA基本数据类型和引用数据类型的区别
[基本数据类型] 基本数据类型:声明时直接在栈内存中开辟空间,并直接在当前内存中存放数据,赋值时传递的是变量中的值,总的来说,基本数据类型是传值的. [引用数据类型] 声明引用数据类型(数组或对象), ...
- Java 容器 接口
Java 中容器框架的内容可以分为三层: 接口(模型), 模板和具体实现. 在开发中使用容器正常的流程是,首先根据需求确定使用何种容器模型,然后选择一个符合性能要求的容器实现类或者自己实现一个容器类. ...
- spring boot jsp页面
相关内容访问: http://www.cnblogs.com/zj0208/p/5985698.html
- nginx+lua 根据指定路径反向代理
location /imgproxytest{ if ($uri ~ ".*\.(jpg|png|jpeg|bmp|gif|swf|css)$"){ rewrite_by_lua ...
- 理解python的元类
看了一篇文档,借鉴一下!写下自己对python元类的理解,欢迎各位大神给出意见. 我的理解就是 type用来创建元类,元类用来创建类,类用来创建实例 这样一想,是不是可以认为元类创建类的过程等同于类创 ...
- Vue常用开源项目汇总
前言:Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架.与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用.Vue 的核心库只关注视图层,不仅易于上手,还 ...
- Android API
http://www.cnblogs.com/over140/tag/Android%20API%20%E4%B8%AD%E6%96%87/
- Spring Boot + Freemarker多语言国际化的实现
最近在写一些Web的东西,技术上采用了Spring Boot + Bootstrap + jQuery + Freemarker.过程中查了大量的资料,也感受到了前端技术的分裂,每种东西都有N种实现, ...
- Android开发之漫漫长途 XVI——ListView与RecyclerView项目实战
该文章是一个系列文章,是本人在Android开发的漫漫长途上的一点感想和记录,我会尽量按照先易后难的顺序进行编写该系列.该系列引用了<Android开发艺术探索>以及<深入理解And ...
- react native 增量升级方案(转)
前言 facebook的react-native给我们带来了用js写出原生应用的同时,也使得使用RN编写的代码的在线升级变得可能,终于可以不通过应用市场来进行升级,极大的提升了app修bug和赋予新功 ...