线性回归预测PM2.5----台大李宏毅机器学习作业1(HW1)
一、作业说明
给定训练集train.csv,要求根据前9个小时的空气监测情况预测第10个小时的PM2.5含量。
训练集介绍:
(1)、CSV文件,包含台湾丰原地区240天的气象观测资料(取每个月前20天的数据做训练集,12月X20天=240天,每月后10天数据用于测试,对学生不可见);
(2)、每天的监测时间点为0时,1时......到23时,共24个时间节点;
(3)、每天的检测指标包括CO、NO、PM2.5、PM10等气体浓度,是否降雨、刮风等气象信息,共计18项;
(4)、数据集地址:https://pan.baidu.com/s/1o2Yx42dZBJZFZqCa5y3WzQ,提取码:qgtm。
用excel打开,繁体字会出现乱码:

用notepad++可以正常打开:

二、思路分析及代码实现
前注:下文中提到的“数据帧”并非指pandas库中的数据结构DataFrame,而是指一个二维的数据包。
2.1 数据预处理
训练集中数据排列形式符合人类观察数据的习惯,但并不能直接拿来喂给模型进行训练,因此需要对数据进行预处理。
浏览数据可知,数据中存在一定量的空数据NR,且多存在于RAINFALL一项。对于空数据,常规的处理方法无非就是删除法和补全法两种。查阅资料后发现,RAINFALL表示当天对应时间点是否降雨,有降雨值为1,无降雨值为NR,类似于布尔变量。因此可以采用补全法处理空数据:将空数据NR全部补为0即可。
根据作业要求可知,需要用到连续9个时间点的气象观测数据,来预测第10个时间点的PM2.5含量。针对每一天来说,其包含的信息维度为(18,24)(18项指标,24个时间节点)。可以将0到8时的数据截取出来,形成一个维度为(18,9)的数据帧,作为训练数据,将9时的PM2.5含量取出来,作为该训练数据对应的label;同理可取1到9时的数据作为训练用的数据帧,10时的PM2.5含量作为label......以此分割,可将每天的信息分割为15个shape为(18,9)的数据帧和与之对应的15个label。
训练集中共包含240天的数据,因此共可获得240X15=3600个数据帧和与之对应的3600个label。
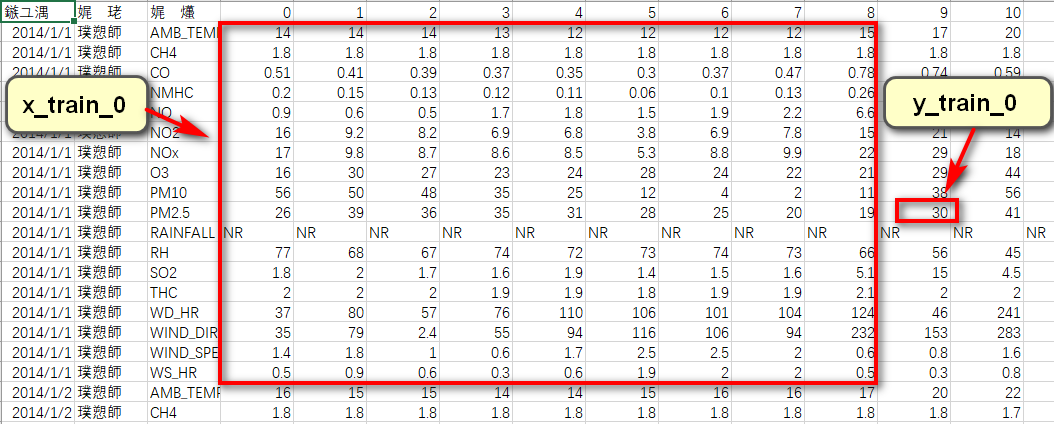
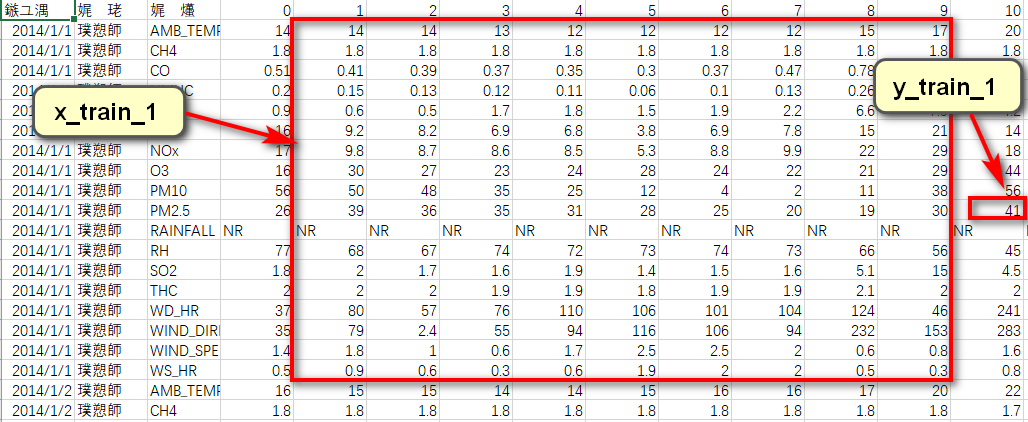
# 数据预处理
def dataProcess(df):
x_list, y_list = [], []
# df替换指定元素,将空数据填充为0
df = df.replace(['NR'], [0.0])
# astype() 转换array中元素数据类型
array = np.array(df).astype(float)
# 将数据集拆分为多个数据帧
for i in range(0, 4320, 18):
for j in range(24-9):
mat = array[i:i+18, j:j+9]
label = array[i+9, j+9] # 第10行是PM2.5
x_list.append(mat)
y_list.append(label)
x = np.array(x_list)
y = np.array(y_list) return x, y, array

2.2 模型建立
如果对相关领域比较熟悉的话,可以根据PM2.5与PM10、SO、NO的浓度关系选择合适的模型。
如果对数据比较敏感的话,可以从数据中发现规律并以此为依据建立模型。
不过笔者对气象领域并不熟悉,对数据也不够敏感,只能采用最简单、最low的线性回归模型。不过既然是作业嘛,就应该允许学生随意发挥,不见得就存在标准答案。
2.2.1 回归模型
采用最普通的线性回归模型,并没有用上训练集中所有的数据,只用到了每个数据帧样本中的9个PM2.5含量值:
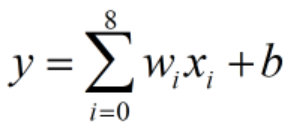
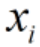 为对应数据帧中第i个PM2.5含量,
为对应数据帧中第i个PM2.5含量, 为其对应的权重值,
为其对应的权重值, 为偏置项,
为偏置项,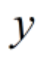 为该数据帧样本的预测结果。
为该数据帧样本的预测结果。
2.2.2 损失函数
用预测值与label之间的平均欧式距离来衡量预测的准确程度,并充当损失函数(这里的损失指的是平均损失;乘1/2是为了在后续求梯度过程中保证梯度项系数为1,方便计算):
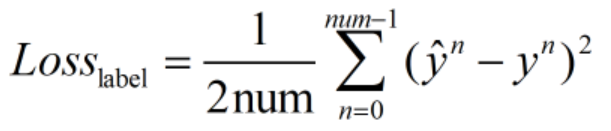
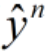 为第n个label,
为第n个label,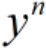 为第n个数据帧的预测结果,
为第n个数据帧的预测结果, 为参加训练的数据帧样本个数。
为参加训练的数据帧样本个数。
为了防止过拟合,加入正则项:
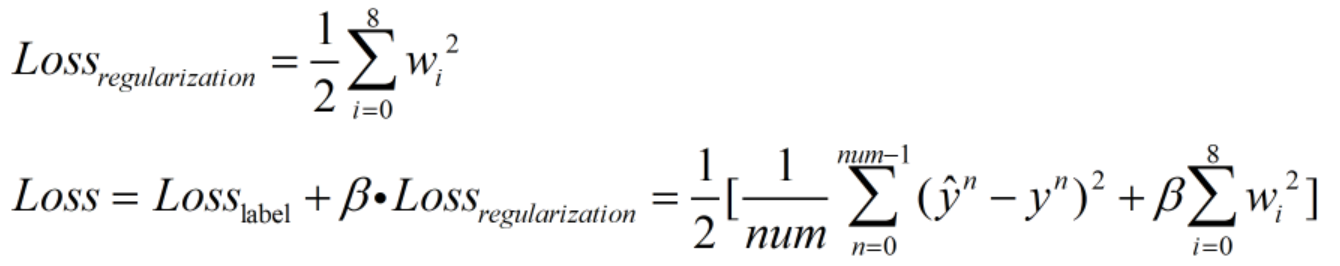
 为正则项,
为正则项,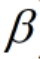 为正则项系数。
为正则项系数。
2.2.3 梯度更新
梯度计算:需明确此时的目标是使Loss最小,而可优化的参数为权重w和偏置值b,因此需要求Loss在w上的偏微分和Loss在b上的偏微分。
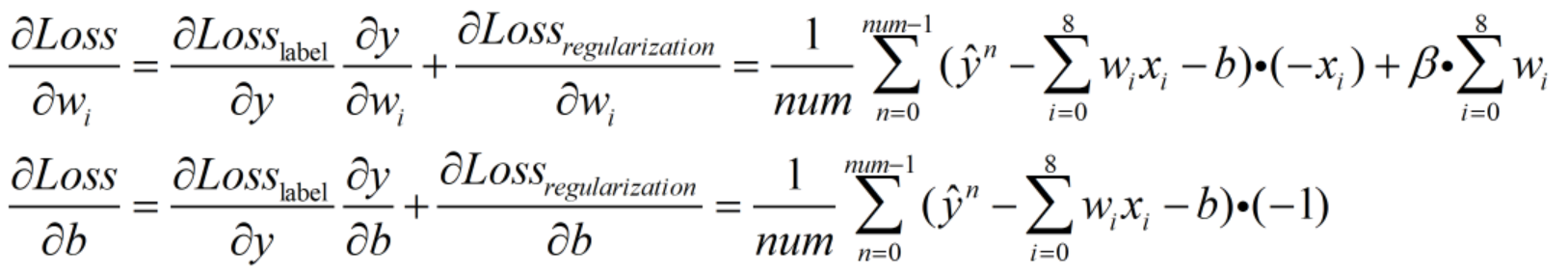
计算出梯度后,通过梯度下降法实现参数更新。
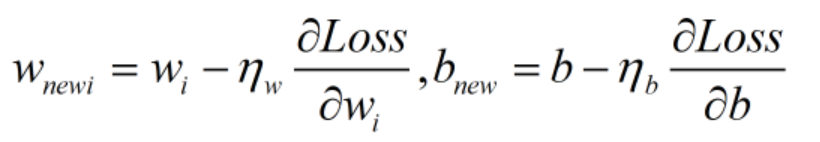
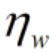 为权重w更新时的学习率,
为权重w更新时的学习率,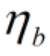 为偏置b更新时的学习率。
为偏置b更新时的学习率。
2.2.3 学习率更新
为了在不影响模型效果的前提下提高学习速度,可以对学习率进行实时更新:即让学习率的值在学习初期较大,之后逐渐减小。这里采用比较经典的adagrad算法来更新学习率。
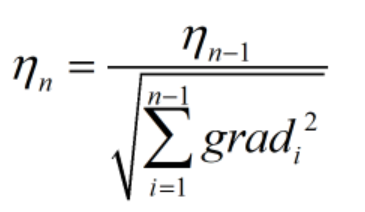
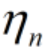 为更新后的学习率,
为更新后的学习率, 为更新前的学习率。
为更新前的学习率。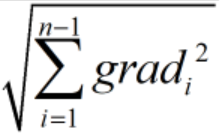 为在此之前所有梯度平方和的二次根。
为在此之前所有梯度平方和的二次根。
# 更新参数,训练模型
def train(x_train, y_train, epoch):
bias = 0 # 偏置值初始化
weights = np.ones(9) # 权重初始化
learning_rate = 1 # 初始学习率
reg_rate = 0.001 # 正则项系数
bg2_sum = 0 # 用于存放偏置值的梯度平方和
wg2_sum = np.zeros(9) # 用于存放权重的梯度平方和 for i in range(epoch):
b_g = 0
w_g = np.zeros(9)
# 在所有数据上计算Loss_label的梯度
for j in range(3200):
b_g += (y_train[j] - weights.dot(x_train[j, 9, :]) - bias) * (-1)
for k in range(9):
w_g[k] += (y_train[j] - weights.dot(x_train[j, 9, :]) - bias) * (-x_train[j, 9, k])
# 求平均
b_g /= 3200
w_g /= 3200
# 加上Loss_regularization在w上的梯度
for m in range(9):
w_g[m] += reg_rate * weights[m] # adagrad
bg2_sum += b_g**2
wg2_sum += w_g**2
# 更新权重和偏置
bias -= learning_rate/bg2_sum**0.5 * b_g
weights -= learning_rate/wg2_sum**0.5 * w_g return weights, bias
三、代码分享与结果分析
3.1 源代码
import pandas as pd
import numpy as np # 数据预处理
def dataProcess(df):
x_list, y_list = [], []
# df替换指定元素,将空数据填充为0
df = df.replace(['NR'], [0.0])
# astype() 转换array中元素数据类型
array = np.array(df).astype(float)
# 将数据集拆分为多个数据帧
for i in range(0, 4320, 18):
for j in range(24-9):
mat = array[i:i+18, j:j+9]
label = array[i+9, j+9] # 第10行是PM2.5
x_list.append(mat)
y_list.append(label)
x = np.array(x_list)
y = np.array(y_list) '''
# 将每行数据都scale到0到1的范围内,有利于梯度下降,但经尝试发现效果并不好
for i in range(18):
if(np.max(x[:, i, :]) != 0):
x[: , i, :] /= np.max(x[:, i, :])
'''
return x, y, array # 更新参数,训练模型
def train(x_train, y_train, epoch):
bias = 0 # 偏置值初始化
weights = np.ones(9) # 权重初始化
learning_rate = 1 # 初始学习率
reg_rate = 0.001 # 正则项系数
bg2_sum = 0 # 用于存放偏置值的梯度平方和
wg2_sum = np.zeros(9) # 用于存放权重的梯度平方和 for i in range(epoch):
b_g = 0
w_g = np.zeros(9)
# 在所有数据上计算Loss_label的梯度
for j in range(3200):
b_g += (y_train[j] - weights.dot(x_train[j, 9, :]) - bias) * (-1)
for k in range(9):
w_g[k] += (y_train[j] - weights.dot(x_train[j, 9, :]) - bias) * (-x_train[j, 9, k])
# 求平均
b_g /= 3200
w_g /= 3200
# 加上Loss_regularization在w上的梯度
for m in range(9):
w_g[m] += reg_rate * weights[m] # adagrad
bg2_sum += b_g**2
wg2_sum += w_g**2
# 更新权重和偏置
bias -= learning_rate/bg2_sum**0.5 * b_g
weights -= learning_rate/wg2_sum**0.5 * w_g # 每训练200轮,输出一次在训练集上的损失
if i%200 == 0:
loss = 0
for j in range(3200):
loss += (y_train[j] - weights.dot(x_train[j, 9, :]) - bias)**2
print('after {} epochs, the loss on train data is:'.format(i), loss/3200) return weights, bias # 验证模型效果
def validate(x_val, y_val, weights, bias):
loss = 0
for i in range(400):
loss += (y_val[i] - weights.dot(x_val[i, 9, :]) - bias)**2
return loss / 400 def main():
# 从csv中读取有用的信息
# 由于大家获取数据集的渠道不同,所以数据集的编码格式可能不同
# 若读取失败,可在参数栏中加入encoding = 'gb18030'
df = pd.read_csv('train.csv', usecols=range(3,27))
x, y, _ = dataProcess(df)
#划分训练集与验证集
x_train, y_train = x[0:3200], y[0:3200]
x_val, y_val = x[3200:3600], y[3200:3600]
epoch = 2000 # 训练轮数
# 开始训练
w, b = train(x_train, y_train, epoch)
# 在验证集上看效果
loss = validate(x_val, y_val, w, b)
print('The loss on val data is:', loss) if __name__ == '__main__':
main()
3.1 结果展示
可以看出,模型在验证集上的损失为40左右,即预测值与label之间的平均差异在6到7之间,由此可见,模型的整体效果还是比较差的。

3.3 模型改进的方向
(1)在从csv文件中提取数据帧和label时,本文以天为单位,每天分割出15个数据帧和15个label。事实上,时间是连续的,可以将每月的20天首尾连接,再从其中分割数据帧和label,可使数据帧样本数量大大提升,可能会使模型效果更优。
(2)在构建模型时,应充分考虑PM2.5与其他大气成分之间的关系,构建更合理的模型。
(3)分割训练集和验证集时,应该按照比例随机抽取数据帧作为训练集和验证集,而不是像本文那样简单地把前3200个数据样本作为训练集,后400个作为验证集。
参考资料:
李宏毅老师机器学习课程视频:https://www.bilibili.com/video/av10590361
李宏毅老师机器学习课程讲义资料:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
邱锡鹏老师《神经网络与深度学习》: https://nndl.github.io/
线性回归预测PM2.5----台大李宏毅机器学习作业1(HW1)的更多相关文章
- 基于卷积神经网络的面部表情识别(Pytorch实现)----台大李宏毅机器学习作业3(HW3)
一.项目说明 给定数据集train.csv,要求使用卷积神经网络CNN,根据每个样本的面部图片判断出其表情.在本项目中,表情共分7类,分别为:(0)生气,(1)厌恶,(2)恐惧,(3)高兴,(4)难过 ...
- Logistic回归二分类Winner or Losser----台大李宏毅机器学习作业二(HW2)
一.作业说明 给定训练集spam_train.csv,要求根据每个ID各种属性值来判断该ID对应角色是Winner还是Losser(0.1分类). 训练集介绍: (1)CSV文件,大小为4000行X5 ...
- 台大《机器学习基石》课程感受和总结---Part 1(转)
期末终于过去了,看看别人的总结:http://blog.sina.com.cn/s/blog_641289eb0101dynu.html 接触机器学习也有几年了,不过仍然只是个菜鸟,当初接触的时候英文 ...
- 李宏毅 线性回归预测PM2.5
作业说明 给定训练集train.csv,要求根据前9个小时的空气监测情况预测第10个小时的PM2.5含量. 训练集介绍: (1):CSV文件,包含台湾丰原地区240天的气象观测资料(取每个月前20天的 ...
- 台大《机器学习基石》课程感受和总结---Part 2 (转)
转自:http://blog.sina.com.cn/s/blog_641289eb0101e2ld.html Part 2总结一下一个粗略的建模过程: 首先,弄清楚问题是什么,能不能用机器学习的思路 ...
- Coursera台大机器学习基础课程学习笔记1 -- 机器学习定义及PLA算法
最近在跟台大的这个课程,觉得不错,想把学习笔记发出来跟大家分享下,有错误希望大家指正. 一机器学习是什么? 感觉和 Tom M. Mitchell的定义几乎一致, A computer program ...
- Coursera台大机器学习基础课程1
Coursera台大机器学习基础课程学习笔记 -- 1 最近在跟台大的这个课程,觉得不错,想把学习笔记发出来跟大家分享下,有错误希望大家指正. 一 机器学习是什么? 感觉和 Tom M. Mitche ...
- Coursera台大机器学习基础课程学习笔记2 -- 机器学习的分类
总体思路: 各种类型的机器学习分类 按照输出空间类型分Y 按照数据标记类型分yn 按照不同目标函数类型分f 按照不同的输入空间类型分X 按照输出空间类型Y,可以分为二元分类,多元分类,回归分析以及结构 ...
- 机器学习01:使用scikit-learn的线性回归预测Google股票
这是机器学习系列的第一篇文章. 本文将使用Python及scikit-learn的线性回归预测Google的股票走势.请千万别期望这个示例能够让你成为股票高手.下面按逐步介绍如何进行实践. 准备数据 ...
随机推荐
- thinter中lable标签控件(二)
lable控件 对于tkinter来说,学起来很简单,只要设置好相应的参数即可出结果,所以不用刻意去记住这些参数.学习一遍后理解每个参数的作用是什么即可. 当下次用到的时候来笔记上看一下就行. 内容很 ...
- MYSQL的空间查询
http://blog.sina.com.cn/s/blog_a48af8c001018q1p.html 本文将向各位介绍如何使用MySql5.x中的空间数据库,并展示一下它高效的性能(前提是正确使用 ...
- .Net core Web API导出数据到Excel
前言 产品经理有一个需求,就是将cosmosDB里的数据,导出到Excel中. 1.新建一个.net core web api controller 添加引用:EPPlus.Core Install- ...
- key.go
package].Key) if err = waitDelete(ctx, client, lastKey, resp.Header.Revision); err != nil { ...
- js生成带logo的二维码
作为一名java程序员,一直以来都是使用服务端生成二维码,最近接触前端的设计,感觉二维码这块如果放到前端去生成,一方面可以减轻服务端的压力,访问带宽,另一方面,前端页面控制比较顺畅 闲话少叙,说下我的 ...
- 排序1,2......n的无序数组,时间复杂度为o(n),空间复杂度为o(1)
#include "stdafx.h" #include <iostream> using namespace std; int _tmain(int argc, _T ...
- 【强连通分量】Bzoj1654 [Usaco2006 Jan]The Cow Prom 奶牛舞会
Description 约翰的N(2≤N≤10000)只奶牛非常兴奋,因为这是舞会之夜!她们穿上礼服和新鞋子,别上鲜花,她们要表演圆舞. 只有奶牛才能表演这种圆舞.圆舞需要一些绳索和一个圆形的 ...
- spot 状压dp
题目大意:数轴上有n个泥点,共有m个木板,求最少用几个木板可以覆盖全部泥点,并求最优方案数(n,m<=15) 看范围,肯定是状压 f[i][j]表示前i个泥点都被覆盖,使用的木板集合为j 转移: ...
- 从壹开始前后端 [vue后台] 之一 || 权限后台系统 1.0 正式上线
缘起 哈喽各位小伙伴周三好,春节已经过去好多天了,群里小伙伴也各种催搞了,新年也接了新项目,比较忙,不过还是终于赶上这个二月的尾巴写了这篇文章,也把 vue 权限后台上线了(项目地址:http://1 ...
- python接口自动化(二十一)--unittest简介(详解)
简介 前边的随笔主要介绍的requests模块的有关知识个内容,接下来看一下python的单元测试框架unittest.熟悉 或者了解java 的小伙伴应该都清楚常见的单元测试框架 Junit 和 T ...