js万亿级数字转汉字的封装方法
要求如图:
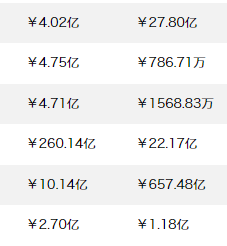
实现方法:
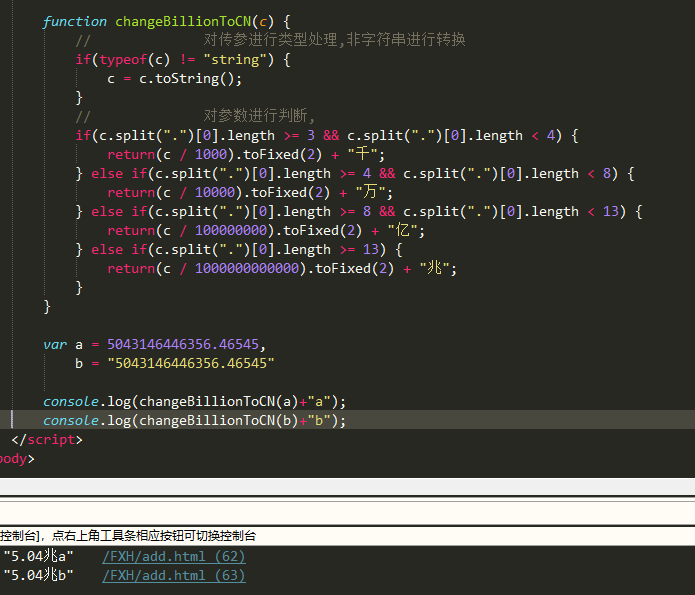
function changeBillionToCN(c) {
// 对传参进行类型处理,非字符串进行转换
if(typeof(c) != "string") {
c = c.toString();
}
// 对参数进行判断,
if(c.split(".")[0].length >= 3 && c.split(".")[0].length < 4) {
return(c / 1000).toFixed(2) + "千";
} else if(c.split(".")[0].length >= 4 && c.split(".")[0].length < 8) {
return(c / 10000).toFixed(2) + "万";
} else if(c.split(".")[0].length >= 8 && c.split(".")[0].length < 13) {
return(c / 100000000).toFixed(2) + "亿";
} else if(c.split(".")[0].length >= 13) {
return(c / 1000000000000).toFixed(2) + "兆";
}
}
实测结果:
知识点:
1.数字对字符串的转换:number.toString();
2.字符串长度的判断:string.length;
3.字符串的切割与拼接:string.split(" ")【引号标住需要切开的点】
4.与非或:&& || !
5.小数取位:string.toFixed(2)【括号2代表取2位有效小数】
js万亿级数字转汉字的封装方法的更多相关文章
- 杂文笔记《Redis在万亿级日访问量下的中断优化》
杂文笔记<Redis在万亿级日访问量下的中断优化> Redis在万亿级日访问量下的中断优化 https://mp.weixin.qq.com/s?__biz=MjM5ODI5Njc2MA= ...
- 腾讯自研万亿级消息中间件TubeMQ为什么要捐赠给Apache?
导语 | 近日,云+社区技术沙龙“腾讯开源技术”圆满落幕.本次沙龙邀请了多位腾讯技术专家围绕腾讯开源与各位开发者进行探讨,深度揭秘了腾讯开源项目TencentOS tiny.TubeMQ.Kona J ...
- Kafka万亿级消息实战
一.Kafka应用 本文主要总结当Kafka集群流量达到 万亿级记录/天或者十万亿级记录/天 甚至更高后,我们需要具备哪些能力才能保障集群高可用.高可靠.高性能.高吞吐.安全的运行. 这里总结内容主 ...
- 如何基于MindSpore实现万亿级参数模型算法?
摘要:近来,增大模型规模成为了提升模型性能的主要手段.特别是NLP领域的自监督预训练语言模型,规模越来越大,从GPT3的1750亿参数,到Switch Transformer的16000亿参数,又是一 ...
- javascript 使用数组+循环+条件实现数字转换为汉字的简单方法。
这几天,博主碰到了几道关于数字转汉字的javascript算法题,在网上找了很多的答案,发现都有点复杂,于是我决定自己写一篇关于这种算法题的简单解法,以下是博主自己的见解,有不足的地方请多指教. 接下 ...
- 腾讯万亿级分布式消息中间件TubeMQ正式开源
TubeMQ是腾讯在2013年自研的分布式消息中间件系统,专注服务大数据场景下海量数据的高性能存储和传输,经过近7年上万亿的海量数据沉淀,目前日均接入量超过25万亿条.较之于众多明星的开源MQ组件,T ...
- 万亿级KV存储架构与实践
一.KV 存储发展历程 我们第一代的分布式 KV 存储如下图左侧的架构所示,相信很多公司都经历过这个阶段.在客户端内做一致性哈希,在后端部署很多的 Memcached 实例,这样就实现了最基本的 KV ...
- Kafka 万亿级消息实践之资源组流量掉零故障排查分析
作者:vivo 互联网服务器团队-Luo Mingbo 一.Kafka 集群部署架构 为了让读者能与小编在后续的问题分析中有更好的共鸣,小编先与各位读者朋友对齐一下我们 Kafka 集群的部署架构及服 ...
- 万亿级日志与行为数据存储查询技术剖析(续)——Tindex是改造的lucene和druid
五.Tindex 数果智能根据开源的方案自研了一套数据存储的解决方案,该方案的索引层通过改造Lucene实现,数据查询和索引写入框架通过扩展Druid实现.既保证了数据的实时性和指标自由定义的问题,又 ...
随机推荐
- Maven工程搭建spring boot+spring mvc+JPA
添加Spring boot支持,引入相关包: 1.maven工程,少不了pom.xml,spring boot的引入可参考官网: <parent> <groupId>org.s ...
- deeplearning.ai 人工智能行业大师访谈 Ian Goodfellow 听课笔记
1. Ian Goodfellow之前是做神经科学研究,在斯坦福上了Andrew NG的课之后,Ian决定投身AI.在寒假他和小伙伴读了Hinton的论文,然后搭了一台用CUDA跑Boltzmann ...
- 学习笔记-echarts点击数据添加跳转链接
原链接:http://echarts.baidu.com/demo.html#pie-rich-text 这个一段官方提供的实例. var weatherIcons = { 'Sunny': './d ...
- 浅析ASCII、Unicode和UTF-8三种常见字符编码
什么是字符编码? 计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255( ...
- BZOJ:4209: 西瓜王
原题链接:http://www.lydsy.com/JudgeOnline/problem.php?id=4209 (虽然仅仅是看在名字的份上,我们还是得说这题是一道) 绝世好题!西瓜王!西瓜王!西瓜 ...
- BZOJ2004: [Hnoi2010]Bus 公交线路
题目:http://www.lydsy.com/JudgeOnline/problem.php?id=2004 状压dp+矩阵乘法. f[i][s]表示从第i位至前面的i-k位,第i位必须取的状态. ...
- DataURL与File,Blob,canvas对象之间的互相转换的Javascript
canvas转换为dataURL (从canvas获取dataURL) var dataurl = canvas.toDataURL('image/png'); var dataurl2 = canv ...
- 数值积分之Simpson公式与梯形公式
Simpson(辛普森)公式和梯形公式是求数值积分中很重要的两个公式,可以帮助我们使用计算机求解数值积分,而在使用过程中也有多种方式,比如复合公式和变步长公式.这里分别给出其简单实现(C++版): 1 ...
- Effective Java 第三版——24. 优先考虑静态成员类
Tips <Effective Java, Third Edition>一书英文版已经出版,这本书的第二版想必很多人都读过,号称Java四大名著之一,不过第二版2009年出版,到现在已经将 ...
- UEP-时间
时间戳转化为Date(or String) SimpleDateFormat format = new SimpleDateFormat( "yyyy-MM-dd HH:mm:ss" ...