Scrapy 框架流程详解
框架流程图
Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向):

简单叙述一下每层图的含义吧:
- Spiders(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
- Engine(引擎):框架核心,负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等
- Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理队列,当引擎需要时,交还给引擎
- Downloader(下载器):负责下载Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Engine(引擎),由引擎交给Spider来处理
- ItemPipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方
- Downloader Middlewares(下载中间件):介于Scrapy引擎和下载器之间的中间件,主要是处理Scrapy引擎与下载器之间的请求及响应
- Spider Middlewares(Spider中间件):介于Scrapy引擎和爬虫之间的中间件,主要工作是处理蜘蛛的响应输入和请求输出
- Scheduler Middlewares(调度中间件):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
执行过程描述
Scrapy执行流程图:
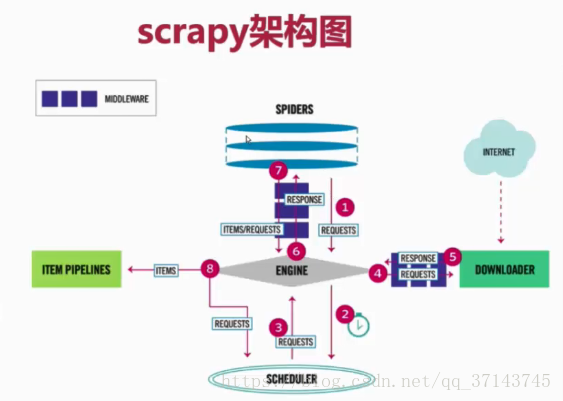
用scrapy框架的时候,一定要先明白执行的顺序,代码已写好,程序开始运行~
- SPIDERS的yeild将request发送给ENGIN
- ENGINE对request不做任何处理发送给SCHEDULER
- SCHEDULER( url调度器),生成request交给ENGIN
- ENGINE拿到request,通过MIDDLEWARE进行层层过滤发送给DOWNLOADER
- DOWNLOADER在网上获取到response数据之后,又经过MIDDLEWARE进行层层过滤发送给ENGIN
- ENGINE获取到response数据之后,返回给SPIDERS,SPIDERS的parse()方法对获取到的response数据进行处理,解析出items或者requests
- 将解析出来的items或者requests发送给ENGIN
- ENGIN获取到items或者requests,将items发送给ITEMPIPELINES,将requests发送给SCHEDULER
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
过程描述:
1.引擎:Hi!Spider, 你要处理哪一个网站?
2.Spider:老大要我处理xxxx.com(初始URL)。
3.引擎:你把第一个需要处理的URL给我吧。
4.Spider:给你,第一个URL是xxxxxxx.com。
5.引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6.调度器:好的,正在处理你等一下。
7.引擎:Hi!调度器,把你处理好的request请求给我。
8.调度器:给你,这是我处理好的request
9.引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求。
10.下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
11.引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
12.Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
13.引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
14.管道、调度器:好的,现在就做!
一些重要的命令
创建项目:scrapy startproject proname
进入项目:cd proname
创建爬虫:scrapy genspider spiname(爬虫名) xxx.com (爬取域)
创建规则爬虫:scrapy genspider -t crawl spiname(爬虫名) xxx.com (爬取域)
运行爬虫:scrapy crawl spiname -o file.json

开发Scrapy爬虫的步骤
- 创建项目:scrapy startproject proname(项目名字,不区分大小写)
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
- 添加启动程序文件(start.py):等同于此命令(scrapy crawl xxx -o xxx.json),from scrapy import cmdline cmdline.execute("scrapy crawl 项目名".split())
parse()方法的工作机制
- 因为使用的yield,而不是return。parse函数将会被当做一个生成器使用。scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型;
- 如果是request则加入爬取队列,如果是item类型则使用pipeline处理,其他类型则返回错误信息;
- scrapy取到第一部分的request不会立马就去发送这个request,只是把这个request放到队列里,然后接着从生成器里获取;
- 取尽第一部分的request,然后再获取第二部分的item,取到item了,就会放到对应的pipeline里处理;
- parse()方法作为回调函数(callback)赋值给了Request,指定parse()方法来处理这些请求 scrapy.Request(url, callback=self.parse);
- Request对象经过调度,执行生成 scrapy.http.response()的响应对象,并送回给parse()方法,直到调度器中没有Request(递归的思路);
- 取尽之后,parse()工作结束,引擎再根据队列和pipelines中的内容去执行相应的操作;
- 程序在取得各个页面的items前,会先处理完之前所有的request队列里的请求,然后再提取items;
- 这一切的一切,Scrapy引擎和调度器将负责到底。
至此。转载请注明出处。

Scrapy 框架流程详解的更多相关文章
- Scrapy框架-scrapy框架架构详解
1.Scrapy框架介绍 写一个爬虫,需要做很多的事情.比如:发送网络请求.数据解析.数据存储.反反爬虫机制(更换ip代理.设置请求头等).异步请求等.这些工作如果每次都要自己从零开始写的话,比较浪费 ...
- SSH框架流程详解
解图: 由图可见,有三个框架{ ①. Struts_2 ②. Spring ③. Hibernate } 框架 作用 本质 同等于 Struts_2 实现MVC / 控制.跳转 过滤器(Filter) ...
- Django Rest框架 流程详解
什么是Restful REST与技术无关,代表的是一种软件架构风格,REST是Representational State Transfer的简称,中文翻译为“表征状态转移” REST从资源的角度类审 ...
- Scrapy笔记03- Spider详解
Scrapy笔记03- Spider详解 Spider是爬虫框架的核心,爬取流程如下: 先初始化请求URL列表,并指定下载后处理response的回调函数.初次请求URL通过start_urls指定, ...
- 测试框架mochajs详解
测试框架mochajs详解 章节目录 关于单元测试的想法 mocha单元测试框架简介 安装mocha 一个简单的例子 mocha支持的断言模块 同步代码测试 异步代码测试 promise代码测试 不建 ...
- 【python3+request】python3+requests接口自动化测试框架实例详解教程
转自:https://my.oschina.net/u/3041656/blog/820023 [python3+request]python3+requests接口自动化测试框架实例详解教程 前段时 ...
- Lucene系列六:Lucene搜索详解(Lucene搜索流程详解、搜索核心API详解、基本查询详解、QueryParser详解)
一.搜索流程详解 1. 先看一下Lucene的架构图 由图可知搜索的过程如下: 用户输入搜索的关键字.对关键字进行分词.根据分词结果去索引库里面找到对应的文章id.根据文章id找到对应的文章 2. L ...
- python+requests接口自动化测试框架实例详解
python+requests接口自动化测试框架实例详解 转自https://my.oschina.net/u/3041656/blog/820023 摘要: python + requests实 ...
- Scrapy笔记05- Item详解
Scrapy笔记05- Item详解 Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便. Item提供了类字典的API, ...
随机推荐
- IdentityModel 中文文档(v1.0.0) 目录
欢迎使用IdentityModel文档! 第一部分 协议客户端库 第1章 发现端点(Discovery Endpoint) 第2章 授权端点(Authorize Endpoint) 第3章 结束会话端 ...
- Hibernate学习——持久化类的学习
A.概念 持久化:将内存中的对象持久化(存储)到数据库的过程.Hibernate就是持久化的框架. 持久化类:一个普通java对象与数据库的表建立了映射关系,那么这个类在Hiberna中被称为持久化类 ...
- Mybaits-plus实战(二)
1. Mybaits-plus实战(二) 1.1. mybatis-plus插件 1.1.1. 用法 先举个例子介绍用法,如下:直接作为Bean注入,一般来讲插件太多印象性能,所以大部分插件都只在测试 ...
- 设计模式之过滤器模式——Java语言描述
过滤器模式允许开发人员使用不同的标准来过滤一组对象,通过逻辑运算以解耦的方式把它们连接起来 实现 创建一个Person对象.Criteria 接口和实现了该接口的实体类,来过滤 Person 对象的列 ...
- Yii2设计模式——静态工厂模式
应用举例 yii\db\ActiveRecord //获取 Connection 实例 public static function getDb() { return Yii::$app->ge ...
- Git:四、连接GitHub远程仓库
1.拥有一个GitHub网站的账号 2.创建SSH Key 打开终端(Windows打开Git Bash),输入: ssh-keygen -t rsa -C "youremail@??.co ...
- windows设置照片查看器为默认的照片查看软件
复制一下内容到记事本中: 文件名:PotoView.bat 文件内容: @echo off set reg_dir=hklm\SOFTWARE\Microsoft\Windows Photo View ...
- Linux系统的启动过程
Linux 系统启动过程 Linux系统的启动过程可以分为5个阶段: BIOS自检 内核的引导. 运行init. 系统初始化. 用户登录系统. BIOS自检: BIOS是英文"Basic I ...
- ASP.NET Aries 高级开发教程:Excel导入之代码编写(番外篇)
前言: 以许框架提供的导入配置功能,已经能解决95%以上的导入情况,但有些情况总归还是得代码来解决. 本篇介绍与导入相关的代码. 1.前端追加导入时Post的参数: var grid = new AR ...
- 前端项目中常用es6知识总结 -- 箭头函数及this指向、尾调用优化
项目开发中一些常用的es6知识,主要是为以后分享小程序开发.node+koa项目开发以及vueSSR(vue服务端渲染)做个前置铺垫. 项目开发常用es6介绍 1.块级作用域 let const 2. ...