.Net HttpWebRequest 爬虫核心爬取
1 爬虫,爬虫攻防
2 下载html
3 xpath解析html,获取数据和深度抓取(和正则匹配)
4 多线程抓取
熟悉http协议
提供两个方法Post和Get
public static string HttpGet(string url, Encoding encoding = null, Dictionary<string,string> headDic=null)
{
string html = string.Empty;
try
{
HttpWebRequest request = HttpWebRequest.Create(url) as HttpWebRequest;//模拟请求
request.Timeout = * ;
request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36";
request.ContentType = "text/html; charset=utf-8";
if (headDic != null)
{
foreach (var item in headDic)
{
request.Headers.Add(item.Key, item.Value);
}
}
if(encoding==null)
encoding = Encoding.UTF8; // 如果是乱码就改成 utf-8 / GB2312
else
encoding=Encoding.GetEncoding("GB2312");
using (HttpWebResponse response = request.GetResponse() as HttpWebResponse)
{
if (response.StatusCode != HttpStatusCode.OK)
{
log.Warn(string.Format("抓取{0}地址返回失败,response.StatusCode为{1}", url, response.StatusCode));
}
else
{
try
{
StreamReader sr = new StreamReader(response.GetResponseStream(), encoding);
html = sr.ReadToEnd();//读取数据
sr.Close();
}
catch (Exception ex)
{
log.Error(string.Format("DownloadHtml抓取{0}保存失败", url), ex);
html = null;
}
}
} }
catch (WebException ex)
{
if (ex.Message.Equals("远程服务器返回错误: (306)。"))
{
log.Error("远程服务器返回错误: (306)。", ex);
return null;
}
}
catch (Exception ex)
{
log.Error(string.Format("DownloadHtml抓取{0}出现异常", url), ex);
html = null;
}
return html;
}
/// <summary>
/// Post 调用借口
/// </summary>
/// <param name="url">接口地址</param>
/// <param name="value">接口参数</param>
/// <returns></returns>
public static string HttpPost(string url, string value)
{
string param = value;
Stream stream = null;
byte[] postData = Encoding.UTF8.GetBytes(param);
try
{
HttpWebRequest myRequest = (HttpWebRequest)WebRequest.Create(url); myRequest.Method = "POST";
myRequest.ContentType = "application/x-www-form-urlencoded";
myRequest.ContentLength = postData.Length;
stream = myRequest.GetRequestStream();
stream.Write(postData, , postData.Length); HttpWebResponse myResponse = (HttpWebResponse)myRequest.GetResponse();
if (myResponse.StatusCode == HttpStatusCode.OK)
{
StreamReader sr = new StreamReader(myResponse.GetResponseStream(), Encoding.UTF8);
string rs = sr.ReadToEnd().Trim();
sr.Close();
return rs;
}
else
{
return "失败:Status:" + myResponse.StatusCode.ToString();
}
}
catch (Exception ex)
{
return "失败:ex:" + ex.ToString();
}
finally
{
if (stream != null)
{
stream.Close();
stream.Dispose();
}
}
}
下载Html
StreamWriter sw = new StreamWriter("路径.txt", true, Encoding.GetEncoding("utf-8"));
sw.Write("爬取的html字符串");
sw.Close();
xpath
http://www.cnblogs.com/zhaozhan/archive/2009/09/09/1563617.html
http://www.cnblogs.com/zhaozhan/archive/2009/09/09/1563679.html
http://www.cnblogs.com/zhaozhan/archive/2009/09/10/1563703.html
正则匹配
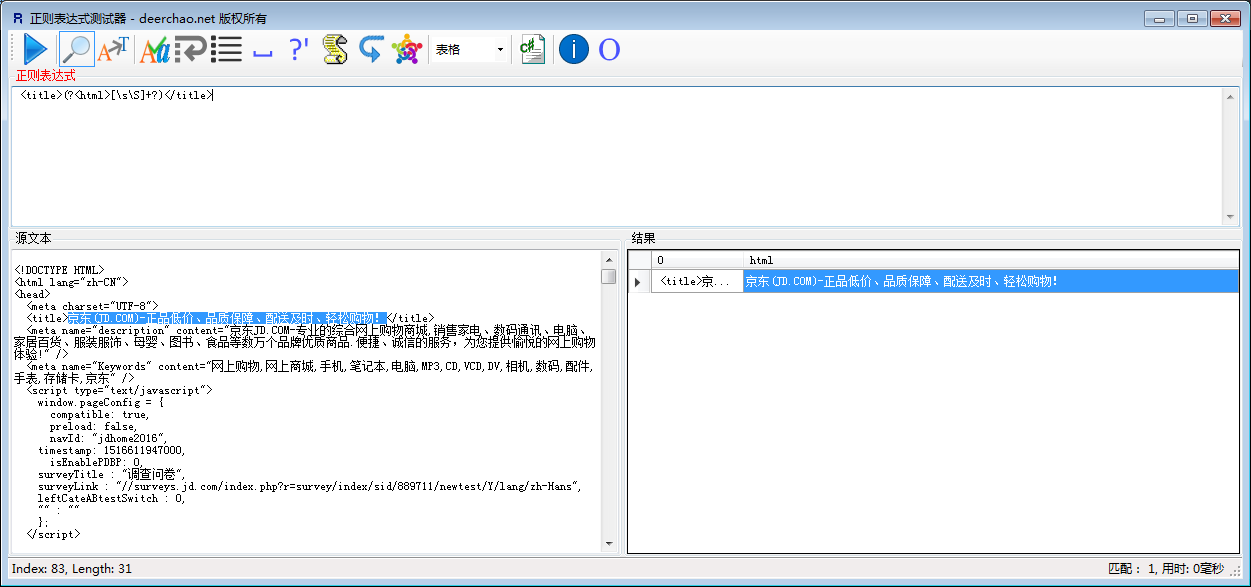
目前使用起来最好用的正则
<title>(?<html>[\s\S]+?)</title> 意思是匹配 <title> *********</title>标签里面的任意字符串
Regex reTitle = new Regex(@"<title>(?<html>[\s\S]+?)</title>"/>");
string title = reTitle.Match(html).Groups["html"].Value;
多个选择
Regex rgInfo = new Regex(@"<td align=""left"">(?<company>[^<>]+)</td><td align=""center"">(?<id>[\dA-Z]+)</td><td align=""center"">(?<cat>[^<>]+)</td><td align=""center"">(?<grade>[A-Z]+)</td><td align=""center"">(?<date>[^\s&]*)");
MatchCollection mchInfos = rgInfo.Matches(strHtml);
foreach (Match m in mchInfos)
{
string strCompany = m.Groups["company"].Value;
string strId = m.Groups["id"].Value;
string strCat = m.Groups["cat"].Value.Replace(" ", "");
string grade = m.Groups["grade"].Value;
string date = m.Groups["date"].Value;
}
多线程
List<Task> taskList = new List<Task>();
TaskFactory taskFactory = new TaskFactory();
for(int i=;i<;i++)
{
taskList.Add(taskFactory.StartNew(Crawler));//将一个执行Crawler方法的线程放到集合里面,创建并启动 任务
if (taskList.Count > ) //线程池启动15个线程
{
taskList = taskList.Where(t => !t.IsCompleted && !t.IsCanceled && !t.IsFaulted).ToList();
Task.WaitAny(taskList.ToArray());//有线程执行完毕
}
}
Task.WaitAll(taskList.ToArray());//100个线程全部执行完成
Console.WriteLine("抓取全部完成 - -", DateTime.Now);
该文档只是自己记录,纯属记事本
.Net HttpWebRequest 爬虫核心爬取的更多相关文章
- 使用htmlparse爬虫技术爬取电影网页的全部下载链接
昨天,我们利用webcollector爬虫技术爬取了网易云音乐17万多首歌曲,而且还包括付费的在内,如果时间允许的话,可以获取更多的音乐下来,当然,也有小伙伴留言说这样会降低国人的知识产权保护意识,诚 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- 使用htmlparser爬虫技术爬取电影网页的全部下载链接
昨天,我们利用webcollector爬虫技术爬取了网易云音乐17万多首歌曲,而且还包括付费的在内,如果时间允许的话,可以获取更多的音乐下来,当然,也有小伙伴留言说这样会降低国人的知识产权保护意识,诚 ...
- scrapy-redis实现爬虫分布式爬取分析与实现
本文链接:http://blog.csdn.net/u012150179/article/details/38091411 一 scrapy-redis实现分布式爬取分析 所谓的scrapy-redi ...
- 网络爬虫之定向爬虫:爬取当当网2015年图书销售排行榜信息(Crawler)
做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500 爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后 ...
- python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取.这里我将记录一下,本人爬取大街网的思路. 附:爬取得数据仅供自己分析所用,并未用作其它用途. 附:本篇适合有一定 爬虫基础 crawl ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- python爬虫项目-爬取雪球网金融数据(关注、持续更新)
(一)python金融数据爬虫项目 爬取目标:雪球网(起始url:https://xueqiu.com/hq#exchange=CN&firstName=1&secondName=1_ ...
随机推荐
- Wix Burn运行64位dism.exe的问题
主要的问题是Burn是一个32位程序,在64位机器上它启动的进程都会被重定向到wow64目录下,也就是说它运行的dism.exe最终会是32位的.解决的方法就是用wix提供的QtExec64CmdLi ...
- API的理解和使用——列表类型的命令
列表类型的命令及对应的时间复杂度 操作 命令 功能 时间复杂度 添加 rpush key value [value ...] 向右插入 O(k),k是元素个数 lpush key value [val ...
- IOS 关于 NSUserDefault
转载 并不是所有的东西都能往里放的.NSUserDefaults只支持: NSString, NSNumber, NSDate, NSArray, NSDictionary. NSUserDefa ...
- Machine Learning No.10: Anomaly detection
1. Algorithm 2. evaluating an anomaly detection system 3. anomaly detection vs supervised learning 4 ...
- 吴恩达机器学习笔记(二) —— Logistic回归
主要内容: 一.回归与分类 二.Logistic模型即sigmoid function 三.decision boundary 决策边界 四.cost function 代价函数 五.梯度下降 六.自 ...
- Centos虚拟机克隆后的ip配置
1. rm -rf /etc/udev/rules.d/-persistent-net.rules 2. 重启,然后: vi /etc/udev/rules.d/70-persistent-net.r ...
- 使用C语言解析URL
1. [代码]容易写成自己输入URL,这里测试一个例子 #include <stdio.h>#include <stdlib.h>#include <string ...
- RQNOJ 328 炮兵阵地:状压dp
题目链接:https://www.rqnoj.cn/problem/328 题意: 司令部的将军们打算在N*M的网格地图上部署他们的炮兵部队. 一个N*M的地图由N行M列组成(N≤100,M≤10), ...
- html5--1.10绝对路径和相对路径
html5--1.10绝对路径和相对路径 学习要点: 绝对路径和相对路径 1.绝对路径 需要指出链接资源的绝对位置,与你的HTML文档的位置无关: 1. 服务器中的位置:href="http ...
- 集训Day3
被疯狂造谣+请家长 但生活还得继续 ...今天的题口胡一下吧明天码 PKUSC2018 D1T1 对于x:若x不翻,则x的一半到x的数都不能翻 若x翻,则x到2x都得翻 剩下随便安排 排列组合一下 P ...