java通过url抓取网页数据-----正则表达式
原文地址https://www.cnblogs.com/xiaoMzjm/p/3894805.html
【本文介绍】
爬取别人网页上的内容,听上似乎很有趣的样子,只要几步,就可以获取到力所不能及的东西,例如呢?例如天气预报,总不能自己拿着仪器去测吧!当然,要获取天气预报还是用webService好。这里只是举个例子。话不多说了,上看看效果吧。
【效果】
我们随便找个天气预报的网站来试试:http://www.weather.com.cn/html/weather/101280101.shtml
从图中可用看出,今天(6日)的天气。我们就以这个为例,获取今天的天气吧!

最终后台打印出:
今天:6日
天气:雷阵雨
温度:26°~34°
风力:微风
【思路】
1、通过url获取输入流————2、获取网页html代码————3、用正则表达式抽取有用的信息————4、拼装成想要的格式
其实最难的一点事第3点,如果正则表示式不熟,基本上在这一步就会挂掉了——例如我T_T。下面为了抽取到正确的数据,我匹配了多次,如果能一次匹配的话,那代码量就少多了!
【代码】

1 package com.zjm.www.test;
2
3 import java.io.BufferedReader;
4 import java.io.IOException;
5 import java.io.InputStream;
6 import java.io.InputStreamReader;
7 import java.net.HttpURLConnection;
8 import java.net.URL;
9 import java.util.regex.Matcher;
10 import java.util.regex.Pattern;
11
12 /**
13 * 描述:趴取网页上的今天的天气
14 * @author zjm
15 * @time 2014/8/6
16 */
17 public class TodayTemperatureService {
18
19 /**
20 * 发起http get请求获取网页源代码
21 * @param requestUrl String 请求地址
22 * @return String 该地址返回的html字符串
23 */
24 private static String httpRequest(String requestUrl) {
25
26 StringBuffer buffer = null;
27 BufferedReader bufferedReader = null;
28 InputStreamReader inputStreamReader = null;
29 InputStream inputStream = null;
30 HttpURLConnection httpUrlConn = null;
31
32 try {
33 // 建立get请求
34 URL url = new URL(requestUrl);
35 httpUrlConn = (HttpURLConnection) url.openConnection();
36 httpUrlConn.setDoInput(true);
37 httpUrlConn.setRequestMethod("GET");
38
39 // 获取输入流
40 inputStream = httpUrlConn.getInputStream();
41 inputStreamReader = new InputStreamReader(inputStream, "utf-8");
42 bufferedReader = new BufferedReader(inputStreamReader);
43
44 // 从输入流读取结果
45 buffer = new StringBuffer();
46 String str = null;
47 while ((str = bufferedReader.readLine()) != null) {
48 buffer.append(str);
49 }
50
51 } catch (Exception e) {
52 e.printStackTrace();
53 } finally {
54 // 释放资源
55 if(bufferedReader != null) {
56 try {
57 bufferedReader.close();
58 } catch (IOException e) {
59 e.printStackTrace();
60 }
61 }
62 if(inputStreamReader != null){
63 try {
64 inputStreamReader.close();
65 } catch (IOException e) {
66 e.printStackTrace();
67 }
68 }
69 if(inputStream != null){
70 try {
71 inputStream.close();
72 } catch (IOException e) {
73 e.printStackTrace();
74 }
75 }
76 if(httpUrlConn != null){
77 httpUrlConn.disconnect();
78 }
79 }
80 return buffer.toString();
81 }
82
83 /**
84 * 过滤掉html字符串中无用的信息
85 * @param html String html字符串
86 * @return String 有用的数据
87 */
88 private static String htmlFiter(String html) {
89
90 StringBuffer buffer = new StringBuffer();
91 String str1 = "";
92 String str2 = "";
93 buffer.append("今天:");
94
95 // 取出有用的范围
96 Pattern p = Pattern.compile("(.*)(<li class=\'dn on\' data-dn=\'7d1\'>)(.*?)(</li>)(.*)");
97 Matcher m = p.matcher(html);
98 if (m.matches()) {
99 str1 = m.group(3);
100 // 匹配日期,注:日期被包含在<h2> 和 </h2>中
101 p = Pattern.compile("(.*)(<h2>)(.*?)(</h2>)(.*)");
102 m = p.matcher(str1);
103 if(m.matches()){
104 str2 = m.group(3);
105 buffer.append(str2);
106 buffer.append("\n天气:");
107 }
108 // 匹配天气,注:天气被包含在<p class="wea" title="..."> 和 </p>中
109 p = Pattern.compile("(.*)(<p class=\"wea\" title=)(.*?)(>)(.*?)(</p>)(.*)");
110 m = p.matcher(str1);
111 if(m.matches()){
112 str2 = m.group(5);
113 buffer.append(str2);
114 buffer.append("\n温度:");
115 }
116 // 匹配温度,注:温度被包含在<p class=\"tem tem2\"> <span> 和 </span><i>中
117 p = Pattern.compile("(.*)(<p class=\"tem tem2\"> <span>)(.*?)(</span><i>)(.*)");
118 m = p.matcher(str1);
119 if(m.matches()){
120 str2 = m.group(3);
121 buffer.append(str2);
122 buffer.append("°~");
123 }
124 p = Pattern.compile("(.*)(<p class=\"tem tem1\"> <span>)(.*?)(</span><i>)(.*)");
125 m = p.matcher(str1);
126 if(m.matches()){
127 str2 = m.group(3);
128 buffer.append(str2);
129 buffer.append("°\n风力:");
130 }
131 // 匹配风,注:<i> 和 </i> 中
132 p = Pattern.compile("(.*)(<i>)(.*?)(</i>)(.*)");
133 m = p.matcher(str1);
134 if(m.matches()){
135 str2 = m.group(3);
136 buffer.append(str2);
137 }
138 }
139 return buffer.toString();
140 }
141
142 /**
143 * 对以上两个方法进行封装。
144 * @return
145 */
146 public static String getTodayTemperatureInfo() {
147 // 调用第一个方法,获取html字符串
148 String html = httpRequest("http://www.weather.com.cn/html/weather/101280101.shtml");
149 // 调用第二个方法,过滤掉无用的信息
150 String result = htmlFiter(html);
151
152 return result;
153 }
154
155 /**
156 * 测试
157 * @param args
158 */
159 public static void main(String[] args) {
160 String info = getTodayTemperatureInfo();
161 System.out.println(info);
162 }
163 }
【详解】
34-49行:通过url获取网页的源码,没什么好说的。
96行:在网页上按F12,查看"今天"的html代码,发现如下图,所以我们第一步就是要过滤掉除这一段html代码外的东西。
(.*)(<li class=\'dn on\' data-dn=\'7d1\'>)(.*?)(</li>)(.*) 这个正则表达式,很容易看出可以分为下面5组:
(.*) :匹配除换行符外任意东西0-N次
(<li class=\'dn on\' data-dn=\'7d1\'>) :匹配中间那段heml代码一次
(.*?) : .*?为匹配的懒惰模式,意思是匹配除换行符外任意东西尽可能少次
(</li>) :匹配中间那段html代码一次
(.*) :匹配除换行符外任意东西0-N次
这样,我们就可用m.group(3)拿到匹配中间(.*?)的那一串代码了。即我们需要的“今天”的天气的代码。
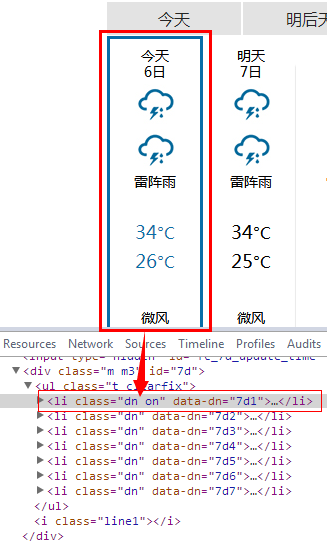
101行:中间那一段代码拿出来后如下图所示、还有很多无用的标签。我们要想办法继续除去。方法同上。

106行:手动拼接上我们需要的字符串。
经过以上的处理,就完成了一个简单的爬取啦。
中间正则表达式部分最不满意,各路网友如果有好的建议麻烦留下宝贵的评论,感激不尽~
java通过url抓取网页数据-----正则表达式的更多相关文章
- java通过url抓取网页数据
在很多行业中,要对行业数据进行分类汇总,及时分析行业数据,对于公司未来的发展,有很好的参照和横向对比.所以,在实际工作,我们可能要遇到数据采集这个概念,数据采集的最终目的就是要获得数据,提取有用的数据 ...
- java抓取网页数据,登录之后抓取数据。
最近做了一个从网络上抓取数据的一个小程序.主要关于信贷方面,收集的一些黑名单网站,从该网站上抓取到自己系统中. 也找了一些资料,觉得没有一个很好的,全面的例子.因此在这里做个笔记提醒自己. 首先需要一 ...
- 使用JAVA抓取网页数据
一.使用 HttpClient 抓取网页数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ...
- 01 UIPath抓取网页数据并导出Excel(非Table表单)
上次转载了一篇<UIPath抓取网页数据并导出Excel>的文章,因为那个导出的是table标签中的数据,所以相对比较简单.现实的网页中,有许多不是通过table标签展示的,那又该如何处理 ...
- 使用HtmlAgilityPack批量抓取网页数据
原文:使用HtmlAgilityPack批量抓取网页数据 相关软件点击下载登录的处理.因为有些网页数据需要登陆后才能提取.这里要使用ieHTTPHeaders来提取登录时的提交信息.抓取网页 Htm ...
- c#抓取网页数据
写了一个简单的抓取网页数据的小例子,代码如下: //根据Url地址得到网页的html源码 private string GetWebContent(string Url) { string strRe ...
- 【iOS】正則表達式抓取网页数据制作小词典
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/xn4545945/article/details/37684127 应用程序不一定要自己去提供数据. ...
- Asp.net 使用正则和网络编程抓取网页数据(有用)
Asp.net 使用正则和网络编程抓取网页数据(有用) Asp.net 使用正则和网络编程抓取网页数据(有用) /// <summary> /// 抓取网页对应内容 /// </su ...
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
随机推荐
- JAVA会将所有的错误封装成为一个对象,其根本父类为Throwable
JAVA会将所有的错误封装成为一个对象,其根本父类为Throwable. Throwable有两个子类:Error和Exception. 一个Error对象表示一个程序错误,指的是底层的.低级的.不可 ...
- 断言(assert)和程序的安全保证
断言,用来DEBUG错误的,在DEBUG时发现然后跟踪错误! 通常 写一个程序给别人使用的,这个代码在安全性上的要求是什么呢?直觉上,我们都知道程序不应该崩.但是通常C/C++的程序如果把包含API的 ...
- python爬虫<urlopen error [Errno 10061] >
在网上看了十几篇文章,都是说的是IE的代理设置,具体是: Tools->Internet Options->Connections->Lan Settings 将代理服务器的小勾勾去 ...
- Tomcat高并发配置优化
用的JMeter在自己电脑上测试的.Ubuntu10.04(x64)内存2G,cpu E5400 主频2.7.jdk1.6.0_27(x64) , tomcat6.0.33(x64) , oracle ...
- python3----requests
import requests def get_html_text(url): try: r = requests.get(url, timeout=30) r.raise_for_status() ...
- Java Tomcat 注册为Windows系统服务
注册方法: 1. 在DOS命令行模式下,cd到tomcat的bin目录下 cd tomcatpath 根目录加:后回车 进入到tomcat安装目录,cd bin,进入tomcat启动目录 2.在tom ...
- leetcode difficulty and frequency distribution chart
Here is a difficulty and frequency distribution chart for each problem (which I got from the Interne ...
- 数据库为什么要用B+树结构--MySQL索引结构的实现(转)
B+树在数据库中的应用 { 为什么使用B+树?言简意赅,就是因为: 1.文件很大,不可能全部存储在内存中,故要存储到磁盘上 2.索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数(为什么使用B-/ ...
- phpstrom如何定义文件打开的方式
今天想vue结合PHP来小写一段代码,但是发现自己把vue的文件放进去,会显示text文本,在刚开始的时候,编辑器会提示我们以什么格式打开,我没在意的选择了text,结果悲催了,那么在设置里面的哪个选 ...
- 《C++ Primer Plus》学习笔记0
Hello,World! 本书版本:<C++ Primer Plus(第6版)中文版>C++是在C语言基础上开发的一种集面向对象编程.泛型编程和过程化编程于一体的编程语言,是C语言的超集. ...