K-means聚类算法MATLAB
以K-means算法为例,实现了如下功能
- 自动生成符合高斯分布的数据,函数名为gaussianSample.m
- 实现多次随机初始化聚类中心,以找到指定聚类数目的最优聚类。函数名myKmeans.m
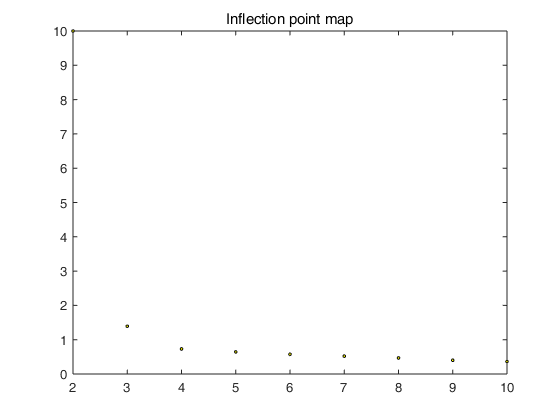
- 自动寻找最佳聚类数目,函数名称besKmeans.m,并绘制了拐点图(L图)
gaussianSample.m
function [data] = gaussianSample(n,m,mu,sigma,sigma1)
% 生成n个符合多元高斯分布的样本
% data = gaussianSample(n,m,mu,sigma,mu1,sigma1)
% 生成一个符合高斯分布的数据集data
% n表示生成的数量,m表示每个簇的点的数量
% 先通过mu与sigma生成簇中心的分布情况
% 在通过簇中心分布mu1与sigma1生成每个簇的的分布情况
% mu与mu1为均值,sigma与sigma1为协方差矩阵。 % % 默认值生成2维数据
% m = 100;
% mu = [5,5];
% sigma = [16 0;0 16];
% sigma1 = [0.5,0;0,0.5]; % 生成中心点分布
mu1 = mvnrnd(mu,sigma,n);
% 生成数据
data = [];
for i = 1:n
temp = mvnrnd(mu1(i,:),sigma1,m);
data = [data;temp];
end % % 可视化样本,以二维数据为例
% hold on;
% plot(data(:,1),data(:,2),'ko','MarkerFaceColor','y');
% plot(mu1(:,1),mu1(:,2),'r+','LineWidth',2,'MarkerSize',7);
% hold off;
myKmeans.m
function [cx,cost] = myKmeans(K,data,num)
% 生成将data聚成K类的最佳聚类
[cx,cost] = kmeans1(K,data);
for i = 2:num
[cx1,min] = kmeans1(K,data);
if min<cost
cost = min;
cx = cx1;
end
end
% plotMeans(data,cx,K);
end function [cx,cost] = kmeans1(K,data)
%KMEANS 把数据集data聚成K类
% [cx,cost] = kmeans(K,data)
% K为聚类数目,data为数据集
% cx为样本所属聚类,cost为此聚类的代价值
% 选择需要聚类的数目 % 随机选择聚类中心
centroids = data(randperm(size(data,1),K),:);
% 迭代聚类
centroids_temp = zeros(size(centroids));
num = 0;
while (~isequal(centroids_temp,centroids)&&num<20)
centroids_temp = centroids;
[cx,cost] = findClosest(data,centroids,K);
centroids = compueCentroids(data,cx,K);
num = num+1;
end
cost = cost/size(data,1); end function [cx,cost] = findClosest(data,centroids,K)
% 将样本划分到最近的聚类中心
cost = 0;
n = size(data,1);
cx = zeros(n,1);
for i = 1:n
[M,I] = min(sum((centroids-data(i,:))'.^2));
cx(i) = I;
cost = cost+M;
end end function centroids = compueCentroids(data,cx,K)
% 计算新的聚类中心
centroids = zeros(K,size(data,2));
for i = 1:K
centroids(i,:) = mean(data(cx==i,:));
end
end
bestKmeans.m
function [num,cx] = bestKmeans(data,m,n)
% 返回数据集的最佳聚类数目与聚类结果
% data为数据集,m为寻找的最大聚类数量,n为每次聚类寻找次数
% 返回num最佳聚类数量,cx聚类结果。
costs = zeros(m,1)';
for i = 1:m
[~,cost] = myKmeans(i,data,n);
costs(i) = cost;
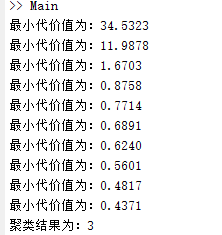
fprintf('最小代价值为:%.4f\n',cost);
end
costs = costs./costs(2)*m;
% 绘制拐点图
X = (1:m)';
X = [X,costs']; plot(X(2:m,1),X(2:m,2),'ko','MarkerFaceColor','y','MarkerSize',2);
title('Inflection point map');
% 寻找最佳聚类
min = -1;
for i = 3:m
x1 = X(2,:)-X(i,:);
x2 = X(m,:)-X(i,:);
k = x1*x2'/((x1*x1')*(x2*x2'));
if k>min&&k<0
num = i;
min = k;
end
end
% fprintf('聚类结果为:%d\n',num);
[cx,~] = myKmeans(num,data,n);
end
plotMeans.m
function [] = plotMeans(data,cx,K)
% 可视化数据聚类效果
figure;
color='cbygmkr';
hold on;
for i = 1:K
px = find(cx==i);
plot(data(px,1),data(px,2),'ko','MarkerFaceColor',color(i),'MarkerSize',5);
end
title('K-means')
hold off;
end
Main.m
% 主函数 % 生成符合高斯分布的数据
mu = [5,5];
sigma = [16,0;0,16];
sigma1 = [0.5,0;0,0.5];
data = gaussianSample(4,50,mu,sigma,sigma1); % 计算最佳聚类数量与结果
[num,cx] = bestKmeans(data,10,10);
fprintf('聚类结果为:%d\n',num);
plotMeans(data,cx,num);
执行Main.m代码,自动检测最佳聚类数目。结果如图

K-means聚类算法MATLAB的更多相关文章
- 密度峰值聚类算法MATLAB程序
密度峰值聚类算法MATLAB程序 凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 密度峰值聚类算法简介见:[转] 密度峰值聚类算法(DPC) 数据见:MATL ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K-medodis聚类算法MATLAB
国内博客,上介绍实现的K-medodis方法为: 与K-means算法类似.只是距离选择与聚类中心选择不同. 距离为曼哈顿距离 聚类中心选择为:依次把一个聚类中的每一个点当作当前类的聚类中心,求出代价 ...
- K-modes聚类算法MATLAB
K-modes算法主要用于分类数据,如 国籍,性别等特征. 距离使用汉明距离,即有多少对应特征不同则距离为几. 中心点计算为,选择众数作为中心点. 主要功能: 随机初始化聚类中心,计算聚类. 选择每次 ...
- 谱聚类算法—Matlab代码
% ========================================================================= % 算 法 名 称: Spectral Clus ...
随机推荐
- 获取页面的checkbox,并给参数赋值
需求: 需要发送的请求:
- hdu6143 Killer Names 容斥+排列组合
/** 题目:hdu6143 Killer Names 链接:http://acm.hdu.edu.cn/showproblem.php?pid=6143 题意:有m种字符(可以不用完),组成两个长度 ...
- jquery-alert对话框
IE的alert没有标题,如果是做企业系统的话,弹出来的的感觉不是很好,所以自己找了一下国外有没有做好的,经过1个小时的奋斗,找到一个不错的,自己重写整理了一下 下载地址如下:http://downl ...
- C++ const关键字修饰引用
//const修饰引用的两种用法 #include<iostream> using namespace std; struct Teacher{ ]; int age; }; void S ...
- 28Mybatis_查询缓存-二级缓存-二级缓存测试-
二级缓存原理:
- 【BZOJ】1653: [Usaco2006 Feb]Backward Digit Sums(暴力)
http://www.lydsy.com/JudgeOnline/problem.php?id=1653 看了题解才会的..T_T 我们直接枚举每一种情况(这里用next_permutation,全排 ...
- sublime text 2安装Emment插件
写个自己看的 1. 命令行模式 ctrl+` 可以调出命令行模式(view->show console),主要支持python语法等,没试用过只知 quit()可以退出 ..不过sublime的 ...
- 求出每个team粉丝数最多的3个国家
有这么个表 fans(team,nationality,fanCount) 'Barcelona','Germany',12000'Barcelona','Spain',18000'Barcelona ...
- Python背景知识——学习笔记
诞生于1989圣诞节,阿姆斯特丹.Guido van Rossum(吉多·范罗苏姆). Python Python:解释型.面向对象.动态数据类型 的 高级程序设计语言. 解释型语言:运行的时候将程序 ...
- spring配置文件头部配置解析
http://blog.csdn.net/f_639584391/article/details/50167321