高并发第十二弹:并发容器J.U.C -- Executor组件FutureTask、ForkJoin
从本章开始就要说 Executor 的东西了.本次讲的是一个很常用的FutureTask,和一个不是那么常用的ForkJoin,我们现在就来介绍吧
引言
大部分时候创建线程的2种方式,一种是直接继承Thread,另外一种就是实现Runnable接口。但是这两种方式都有一个缺陷就是:在执行完任务之后无法获取执行结果。
所以后期就提供了Callable和Future,通过它们可以在任务执行完毕之后得到任务执行结果。FutureTask又是集大成者.
一个一个来介绍
Callable:只有一个带返回值的call方法
@FunctionalInterface
public interface Callable<V> { V call() throws Exception;
}
那么怎么使用Callable呢?一般情况下是配合ExecutorService来使用的,在ExecutorService接口中声明了若干个submit方法的重载版本:
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task)
第一个submit方法里面的参数类型就是Callable。
暂时只需要知道Callable一般是和ExecutorService配合来使用的,具体的使用方法讲在后面讲述。
一般情况下我们使用第一个submit方法和第三个submit方法,第二个submit方法很少使用。
Future接口
public interface Future<V> {
// 取消任务
boolean cancel(boolean mayInterruptIfRunning);
//取消状态
boolean isCancelled();
//是否完成
boolean isDone();
//方法用来获取执行结果,这个方法会产生阻塞,会一直等到任务执行完毕才返回
V get() throws InterruptedException, ExecutionException;
// 用来获取执行结果,如果在指定时间内,还没获取到结果,就直接返回null。
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
也就是说Future提供了三种功能:
1)判断任务是否完成;
2)能够中断任务;
3)能够获取任务执行结果。
因为Future只是一个接口,所以是无法直接用来创建对象使用的,因此就有了下面的FutureTask。
FutureTask
FutureTask这个才是真实使用者.FutureTask实现了RunnableFuture接口,而RunnableFuture接口继承了Runnable与Future接口,所以它既可以作为Runnable被线程中执行,又可以作为callable获得返回值
public class FutureTask<V> implements RunnableFuture<V> {
...
}
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
FutureTask的两个构造类
public FutureTask(Callable<V> callable) {
}
public FutureTask(Runnable runnable, V result) {
}
使用实例
方法一:使用Callable
ExecutorService executor = Executors.newCachedThreadPool();
Callable<String> task = new Callable<String>() { @Override
public String call() throws Exception {
return "task 返回结果";
}
};
Future<String> result = executor.submit(task);
executor.shutdown();
if(result.isDone()) {
System.out.println(result.get());
}
方式二:使用FutureTask
FutureTask<String> task = new FutureTask<>(new Callable<String>() {
@Override
public String call() throws Exception {
return "aaaa";
}
});
task.run();
System.out.println(task.get());
fork/join:
Fork/Join框架:在必要的情况下,将一个大任务,进行拆分(fork) 成若干个子任务(拆到不能再拆,这里就是指我们制定的拆分的临界值),再将一个个小任务的结果进行join汇总。
Fork/Join与传统线程池的区别!
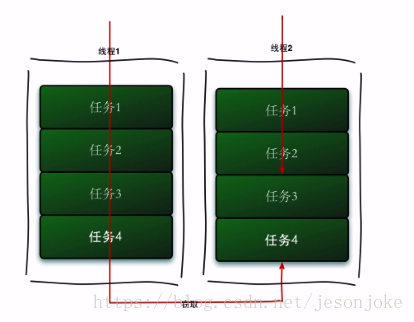
Fork/Join采用“工作窃取模式”,当执行新的任务时他可以将其拆分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随即线程中偷一个并把它加入自己的队列中。
就比如两个CPU上有不同的任务,这时候A已经执行完,B还有任务等待执行,这时候A就会将B队尾的任务偷过来,加入自己的队列中,对于传统的线程,ForkJoin更有效的利用的CPU资源!
我们来看一下ForkJoin的实现:实现这个框架需要继承RecursiveTask 或者 RecursiveAction ,RecursiveTask是有返回值的,相反Action则没有
局限性:
1、任务只能使用fork和join作为同步机制,如果使用了其他同步机制,当他们在同步操作时,工作线程就不能执行其他任务了。比如在fork框架使任务进入了睡眠,那么在睡眠期间内在执行这个任务的线程将不会执行其他任务了。
2、我们所拆分的任务不应该去执行IO操作,如读和写数据文件。
3、任务不能抛出检查异常。必须通过必要的代码来处理他们。
框架核心:
核心有两个类:
ForkJoinPool | ForkJoinTask ForkJoinPool:负责来做实现,包括工作窃取算法、管理工作线程和提供关于任务的状态以及他们的执行信息。
ForkJoinTask:提供在任务中执行fork和join的机制。
测试一下:
public class ForkJoinWork extends RecursiveTask<Long>{
private Long start;//起始值
private Long end;//结束值
public static final Long critical = 5000L;//临界值 ,设定不大于这个值就不分裂
public ForkJoinWork(Long start, Long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
//判断是否是拆分完毕
Long lenth = end - start;
if(lenth<=critical){
//如果拆分完毕就相加
Long sum = 0L;
for (Long i = start;i<=end;i++){
sum += i;
}
return sum;
}else {
//没有拆分完毕就开始拆分
Long middle = (end + start)/2;//计算的两个值的中间值
ForkJoinWork right = new ForkJoinWork(start,middle);
right.fork();//拆分,并压入线程队列
ForkJoinWork left = new ForkJoinWork(middle+1,end);
left.fork();//拆分,并压入线程队列
//合并
return right.join() + left.join();
}
}
public static void main(String[] args) {
long l = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();//实现ForkJoin 就必须有ForkJoinPool的支持
ForkJoinTask<Long> task = new ForkJoinWork(0L,10000000000L);//参数为起始值与结束值
Long invoke = forkJoinPool.invoke(task);
long l1 = System.currentTimeMillis();
System.out.println("invoke = " + invoke+" time: " + (l1-l));
}
}
测试代码
public class ForkJoinWorkTest {
public static void main(String[] args) {
test();
// test2();
// test3();
}
public static void test() {
// ForkJoin实现
long l = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();// 实现ForkJoin 就必须有ForkJoinPool的支持
ForkJoinTask<Long> task = new ForkJoinWork(0L, 10000000000L);// 参数为起始值与结束值
Long invoke = forkJoinPool.invoke(task);
long l1 = System.currentTimeMillis();
System.out.println("ForkJoin实现 time: " + (l1 - l));
}
public static void test2() {
// 普通线程实现
Long x = 0L;
Long y = 10000000000L;
long l = System.currentTimeMillis();
for (Long i = 0L; i <= y; i++) {
x += i;
}
long l1 = System.currentTimeMillis();
System.out.println("普通线程实现 time: " + (l1 - l));
}
public static void test3() {
// Java 8 并行流的实现
long l = System.currentTimeMillis();
long reduce = LongStream.rangeClosed(0, 10000000000L).parallel().reduce(0, Long::sum);
long l1 = System.currentTimeMillis();
System.out.println("Java 8 并行流的实现 time: " + (l1 - l));
}
}
结果:
ForkJoin实现 time: 38798
普通线程实现 time: 58860
Java 8 并行流的实现 time: 2375
我们观察上面可以看出来执行10000000000L的相加操作各自执行完毕的时间不同。观察到当数据很大的时候ForkJoin比普通线程实现有效的多,但是相比之下ForkJoin的实现实在是有点麻烦,这时候Java 8 就为我们提供了一个并行流来实现ForkJoin实现的功能。可以看到并行流比自己实现ForkJoin还要快
Java 8 中将并行流进行了优化,我们可以很容易的对数据进行并行流的操作,Stream API可以声明性的通过parallel()与sequential()在并行流与穿行流中随意切换!
高并发第十二弹:并发容器J.U.C -- Executor组件FutureTask、ForkJoin的更多相关文章
- [CSAPP笔记][第十二章并发编程]
第十二章 并发编程 如果逻辑控制流在时间上是重叠,那么它们就是并发的(concurrent).这种常见的现象称为并发(concurrency). 硬件异常处理程序,进程和Unix信号处理程序都是大家熟 ...
- CSAPP:第十二章 并发编程
CSAPP:第十二章 并发编程 12.1 线程执行模型12.2 多线程之间并发通信12.3 其他并发问题 使用应用级并发的应用程序称为并发程序.现代操作系统提供三种基本的构造并发程序的方法: 进程 ...
- Java多线程和并发(十二),Java线程池
目录 1.利用Executors创建线程的五种不同方式 2.为什么要使用线程池 3.Executor的框架 4.J.U.C的三个Executor接口 5.ThreadPoolExecutor 6.线程 ...
- 谈论高并发(十二)分析java.util.concurrent.atomic.AtomicStampedReference看看如何解决源代码CAS的ABA问题
于谈论高并发(十一)几个自旋锁的实现(五岁以下儿童)中使用了java.util.concurrent.atomic.AtomicStampedReference原子变量指向工作队列的队尾,为何使用At ...
- java并发编程实战:第十二章---并发程序的测试
并发程序中潜在错误的发生并不具有确定性,而是随机的. 安全性测试:通常会采用测试不变性条件的形式,即判断某个类的行为是否与其规范保持一致 活跃性测试:进展测试和无进展测试两方面,这些都是很难量化的(性 ...
- 并发编程(二)------并发类容器ConcurrentMap
并发类容器: jdk5.0以后提供了多种并发类容器来替代同步类容器从而改善性能. 同步类容器的状态都是串行化的. 他们虽然实现了线程安全,但是严重降低了并发性,在多线程环境时,严重降低了应用程序的吞吐 ...
- Java并发(十二):CAS Unsafe Atomic
一.Unsafe Java无法直接访问底层操作系统,而是通过本地(native)方法来访问.不过尽管如此,JVM还是开了一个后门,JDK中有一个类Unsafe,它提供了硬件级别的原子操作. 这个类尽管 ...
- 深入理解计算机系统 第十二章 并发编程 part1 第二遍
三种构造并发程序的方法及其优缺点 1.进程 用这种方法,每个逻辑控制流都是一个进程,由内核来调度和维护.因为进程有独立的虚拟地址空间,想要和其他流通信,控制流必须使用某种显式的进程间通信机制. 优点: ...
- 十二. Go并发编程--sync/errGroup
一.序 这一篇算是并发编程的一个补充,起因是当前有个项目,大概の 需求是,根据kafka的分区(partition)数,创建同等数量的 消费者( goroutine)从不同的分区中消费者消费数据,但是 ...
随机推荐
- 201621123018《Java程序设计》第3周学习报告
Week03-面向对象入门 1. 本周学习总结 初学面向对象,会学习到很多碎片化的概念与知识.尝试学会使用思维导图将这些碎片化的概念.知识点组织起来.请使用工具画出本周学习到的知识点及知识点之间的联系 ...
- django 视图中执行原生的 sql 查询语句
可以使用objects的raw()方法执行原生的sql语句,进行对数据库的查询操作,raw()方法只能执行查询语句 query_set = your_model.objects.raw("s ...
- WKWebView 里 JS 和 native 通信的例子
native 端 初始化 wkwebview,设置 message handler webView = WKWebView.init() let usecc = self.webView.config ...
- 可方便扩展的JIRA Rest Web API的封装调用
JIRA是一个缺陷跟踪管理系统,被广泛应用于缺陷跟踪.客户服务.需求收集.流程审批.任务跟踪.项目跟踪和敏捷管理等工作领域,当我们需要把第三方业务系统集成进来时,可以调用他的API. JIRA本身的A ...
- 【bzoj2789】 Letters 树状数组
又是一道树状数组求逆序对的题目. 这一题我们可以将第二个串中的每一个字母,与第一个串中的字母做两两匹配,令第二个串第i个字母的值id[i]为该字母与第一个串中的字母匹配到的位置. 然后考虑到所求答案为 ...
- commons-logging.jar 和 log4j.jar 的关系
在用springmvc开发项目的时候,在日志管理这一块,我们一般用的都是log4j进行日志管理,但是我们在导入spring相关的jar的时候,都会看到commons-logging.jar包,为什么我 ...
- J06-Java IO流总结六 《 BufferedReader和BufferedWriter 》
1. 概念简介 与字节缓冲流BufferedInputStream和BufferedOutputStream对应的,我们还有字符缓冲流BufferedReader和BufferedWriter,顾名思 ...
- log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.o
上面的报错是在本地java调试(windows) hadoop集群 出现的 解决方案: 在resources文件夹下面创建一个文件log4j.properties(这个其实hadoop安装目录下的 e ...
- C# 点击打开浏览器
System.Diagnostics.Process.Start("网址");//默认浏览器打开网页System.Diagnostics.Process.Start(@" ...
- Javac语法糖之其它
1.变长参数 class VarialbeArgumentsDemo { public static void doWork(int... a) {//可变参数 } public static voi ...