SqlServer 在查询结果中如何过滤掉重复数据
问题背景

SELECT *
FROM (
SELECT ROW_NUMBER() OVER ( ORDER BY T.USERID asc )AS Row
,T.USERID
,T.CreateTime
FROM UserInfo T
LEFT JOIN DiseaseInfo i ON i.UserID=T.UserID
) TT WHERE TT.Row between 0 AND 20 ORDER BY UserID DESC
SELECT DISTINCT ROW ,*
FROM (
SELECT ROW_NUMBER() OVER (PARTITION BY T.USERID ORDER BY T.USERID asc )AS Row
,T.USERID
,T.CreateTime
FROM UserInfo T
LEFT JOIN DiseaseInfo i ON i.UserID=T.UserID
) TT WHERE TT.Row between 0 AND 12 ORDER BY UserID DESC


SELECT *
FROM (
SELECT ROW_NUMBER() OVER ( order by T.USERID asc )AS Row
,T.USERID
,LEFT(T.Patient_Tel1,5)+'' AS Tel
,T.CreateTime
,h.HName
,h.HID
fromUserInfo T
LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1
LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1
AND t.UserID>=17867 AND T.UserID<=17875
--(T.Patient_Tel1 like '%13800000000%')
) TT WHERE
TT.Row between 0and20

SELECT DISTINCT row,*
FROM (
SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row
,T.USERID
,LEFT(T.Patient_Tel1,5)+'' AS Tel
,T.CreateTime
,h.HName
,h.HID
fromUserInfo T
LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1
LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1
AND t.UserID>=17867 AND T.UserID<=17875
--(T.Patient_Tel1 like '%13800000000%')
) TT WHERE
--row=1 AND
TT.Row between 0 and 20

SELECT *
FROM (
--partition by T.USERID 以UserID对结果集进行分区
SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row
,T.USERID
,LEFT(T.Patient_Tel1,5)+'' AS Tel
,T.CreateTime
,h.HName
,h.HID
fromUserInfo T
LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1
LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1
AND t.UserID>=17867 AND T.UserID<=17875
--(T.Patient_Tel1 like '%13800000000%')
) TT WHERE
--因为之前已经以UserID对结果集进行分区,所以如果存在重复的字段则row的值会不相同
--row=1 AND TT.Row between 0 and 20
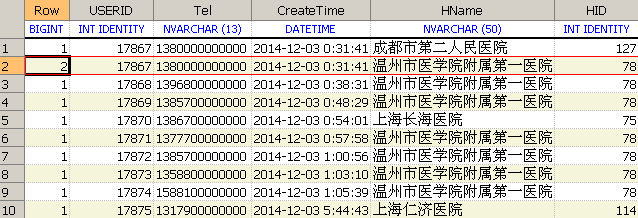

-- 新增一层查询解决过滤掉重复数据后无法分页的问题
SELECT * FROM (
SELECT ROW_NUMBER() OVER (ORDER BY userid) AS RowNum,*
FROM (
--partition by T.USERID 以UserID对结果集进行分区
SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row
,T.USERID
,LEFT(T.Patient_Tel1,5)+'' AS Tel
,T.CreateTime
,h.HName
,h.HID
fromUserInfo T
LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1
LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1
AND t.UserID>=17867 AND T.UserID<=20875
--(T.Patient_Tel1 like '%13800000000%')
) TT
)AS T
WHERE
--过滤重复数据
Row=1
--对结果进行分页
AND RowNum between 13 and 24

SqlServer 在查询结果中如何过滤掉重复数据的更多相关文章
- MySQL查询表中某个字段的重复数据
1. 查询SQL表中某个字段的重复数据 SELECT user_name,COUNT(*) AS count FROM db_user_info GROUP BY user_name HAVING c ...
- mysql去重, 把url重复且区为空的中去掉、统计重复数据、、结果集去重合并成一行
delete from 表名 where id not in (select d.id from (SELECT id FROM 表名 GROUP BY c1,c2,c3,c4)as d) #去重复, ...
- Mysql中查找并删除重复数据的方法
(一)单个字段 1.查找表中多余的重复记录,根据(question_title)字段来判断 代码如下 复制代码 select * from questions where question_title ...
- 查询Oracle中字段名带"."的数据
SDE中的TT_L线层会有SHAPE.LEN这样的字段,使用: SQL>select shape.len from tt_l; 或 SQL>select t.shape.len from ...
- SQL-游标-查询数据库中的所有表的数据个数
--sql语句-游标等使用 ) ) declare @i INT ) declare @cstucount INT --上方设置变量 --初始值 declare mCursor cursor --设置 ...
- 用java查询HBase中某表的一批数据
java代码如下: package db.query; import java.io.IOException; import org.apache.hadoop.conf.Configuration; ...
- 【SQL】查询数据库中某个字段有重复值出现的信息
select name,mobile from [GeneShop].[dbo].[xx_member] where mobile in ( SELECT mobile FROM [GeneShop] ...
- mysql查询sql中检索条件为大批量数据时处理
当userIdArr数组值为大批量时,应如此优化代码实现
- Java中List集合去除重复数据的方法
1. 循环list中的所有元素然后删除重复 public static List removeDuplicate(List list) { for ( int i = 0 ; i < list. ...
随机推荐
- 1015 Reversible Primes (20)(20 point(s))
problem A reversible prime in any number system is a prime whose "reverse" in that number ...
- ARM 常用汇编指令
ARM 汇编程序的框架结构 .section .data <初始化的数据> .section.bss <未初始化的数据> .section .text .global _sta ...
- 2017-2018-1 JAVA实验站 第八周作业
2017-2018-1 JAVA实验站 第八周作业 详情请见团队博客
- hdu 3864 素数分解
题意:求n是否只有4个因子,如果是就输出除1外的所有因子. 模板题,就不排版了 #include<cstdio> #include<iostream> #include< ...
- java 中常用的类
java 中常用的类 Math Math 类,包含用于执行基本数学运算的方法 常用API 取整 l static double abs(double a) 获取double 的绝对值 l sta ...
- MAC下安装多版本JDK和切换几种方式
环境: MAC AIR,OS X 10.10,64位 历史: 过去 Mac 上的 Java 都是由 Apple 自己提供,只支持到 Java 6,并且OS X 10.7 开始系统并不自带(而是可选 ...
- wikioi 3130 CYD刷题(背包)
题目描述 Description 下午,CYD要刷题了,已知CYD有N题可刷,但他只有M分钟的时间,而且他的智慧值为Q,也就是说他只能做出难度小于等于Q的题目.已知每题可得积分Ai,需花费时间Bi,难 ...
- 埃及分解:将2/n分解成为1/x+1/y的格式
算法 古埃及以前创造出灿烂的人类文明,他们的分数表示却非常令人不解.古埃及喜欢把一个分数分解为类似: 1/a + 1/b 的格式. 这里,a 和 b 必须是不同的两个整数,分子必须为 1 比方,2/1 ...
- DU 4609 3-idiots FFT
题意还是比较好懂. 给出若干个木棍的长度,问这些木棍构成三角形的可能性. 那么公式很容易知道 就是这些木棍组成三角形的所有情况个数 除以 从n个木棍中取3个木棍的情况数量C(n, 3) 即可 但是很显 ...
- C#程序集系列07,篡改程序集
以下几个方面用来区分不同的程序集:○ 程序集名称:Name○ 程序集版本:Version○ 程序集公匙: Public Token○ 程序集文化:Culture 如果没有很严格地按照上面的几个方面来创 ...