SqlServer 在查询结果中如何过滤掉重复数据
问题背景

SELECT *
FROM (
SELECT ROW_NUMBER() OVER ( ORDER BY T.USERID asc )AS Row
,T.USERID
,T.CreateTime
FROM UserInfo T
LEFT JOIN DiseaseInfo i ON i.UserID=T.UserID
) TT WHERE TT.Row between 0 AND 20 ORDER BY UserID DESC
SELECT DISTINCT ROW ,*
FROM (
SELECT ROW_NUMBER() OVER (PARTITION BY T.USERID ORDER BY T.USERID asc )AS Row
,T.USERID
,T.CreateTime
FROM UserInfo T
LEFT JOIN DiseaseInfo i ON i.UserID=T.UserID
) TT WHERE TT.Row between 0 AND 12 ORDER BY UserID DESC


SELECT *
FROM (
SELECT ROW_NUMBER() OVER ( order by T.USERID asc )AS Row
,T.USERID
,LEFT(T.Patient_Tel1,5)+'' AS Tel
,T.CreateTime
,h.HName
,h.HID
fromUserInfo T
LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1
LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1
AND t.UserID>=17867 AND T.UserID<=17875
--(T.Patient_Tel1 like '%13800000000%')
) TT WHERE
TT.Row between 0and20

SELECT DISTINCT row,*
FROM (
SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row
,T.USERID
,LEFT(T.Patient_Tel1,5)+'' AS Tel
,T.CreateTime
,h.HName
,h.HID
fromUserInfo T
LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1
LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1
AND t.UserID>=17867 AND T.UserID<=17875
--(T.Patient_Tel1 like '%13800000000%')
) TT WHERE
--row=1 AND
TT.Row between 0 and 20

SELECT *
FROM (
--partition by T.USERID 以UserID对结果集进行分区
SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row
,T.USERID
,LEFT(T.Patient_Tel1,5)+'' AS Tel
,T.CreateTime
,h.HName
,h.HID
fromUserInfo T
LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1
LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1
AND t.UserID>=17867 AND T.UserID<=17875
--(T.Patient_Tel1 like '%13800000000%')
) TT WHERE
--因为之前已经以UserID对结果集进行分区,所以如果存在重复的字段则row的值会不相同
--row=1 AND TT.Row between 0 and 20
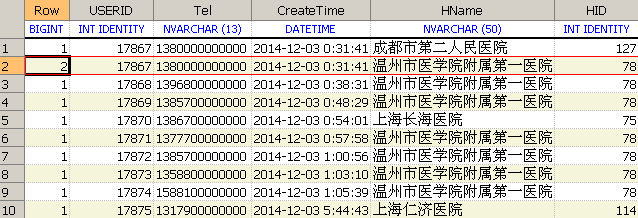

-- 新增一层查询解决过滤掉重复数据后无法分页的问题
SELECT * FROM (
SELECT ROW_NUMBER() OVER (ORDER BY userid) AS RowNum,*
FROM (
--partition by T.USERID 以UserID对结果集进行分区
SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row
,T.USERID
,LEFT(T.Patient_Tel1,5)+'' AS Tel
,T.CreateTime
,h.HName
,h.HID
fromUserInfo T
LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1
LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1
AND t.UserID>=17867 AND T.UserID<=20875
--(T.Patient_Tel1 like '%13800000000%')
) TT
)AS T
WHERE
--过滤重复数据
Row=1
--对结果进行分页
AND RowNum between 13 and 24

SqlServer 在查询结果中如何过滤掉重复数据的更多相关文章
- MySQL查询表中某个字段的重复数据
1. 查询SQL表中某个字段的重复数据 SELECT user_name,COUNT(*) AS count FROM db_user_info GROUP BY user_name HAVING c ...
- mysql去重, 把url重复且区为空的中去掉、统计重复数据、、结果集去重合并成一行
delete from 表名 where id not in (select d.id from (SELECT id FROM 表名 GROUP BY c1,c2,c3,c4)as d) #去重复, ...
- Mysql中查找并删除重复数据的方法
(一)单个字段 1.查找表中多余的重复记录,根据(question_title)字段来判断 代码如下 复制代码 select * from questions where question_title ...
- 查询Oracle中字段名带"."的数据
SDE中的TT_L线层会有SHAPE.LEN这样的字段,使用: SQL>select shape.len from tt_l; 或 SQL>select t.shape.len from ...
- SQL-游标-查询数据库中的所有表的数据个数
--sql语句-游标等使用 ) ) declare @i INT ) declare @cstucount INT --上方设置变量 --初始值 declare mCursor cursor --设置 ...
- 用java查询HBase中某表的一批数据
java代码如下: package db.query; import java.io.IOException; import org.apache.hadoop.conf.Configuration; ...
- 【SQL】查询数据库中某个字段有重复值出现的信息
select name,mobile from [GeneShop].[dbo].[xx_member] where mobile in ( SELECT mobile FROM [GeneShop] ...
- mysql查询sql中检索条件为大批量数据时处理
当userIdArr数组值为大批量时,应如此优化代码实现
- Java中List集合去除重复数据的方法
1. 循环list中的所有元素然后删除重复 public static List removeDuplicate(List list) { for ( int i = 0 ; i < list. ...
随机推荐
- C# CuttingEdge.Conditions 验证帮助类库 文档翻译
项目主页: https://archive.codeplex.com/?p=conditions 作者博客关于项目的文档(翻译原文): https://www.cuttingedge.it/blogs ...
- [Hdu4372] Count the Buildings
[Hdu4372] Count the Buildings Description There are N buildings standing in a straight line in the C ...
- [BZOJ2669] [cqoi2012]局部极小值
[BZOJ2669] [cqoi2012]局部极小值 Description 有一个n行m列的整数矩阵,其中1到nm之间的每个整数恰好出现一次.如果一个格子比所有相邻格子(相邻是指有公共边或公共顶点) ...
- Mysql 千万级快速查询|分页方案
1.简单的 直接查主键id SELECT id FROM tblist WHERE LIMIT 500000,10 2对于有where 条件,又想走索引用limit的,必须创建一个索引,将where ...
- 【10.17校内测试】【二进制数位DP】【博弈论/预处理】【玄学(?)DP】
Solution 几乎是秒想到的水题叻! 异或很容易想到每一位单独做贡献,所以我们需要统计的是区间内每一位上做的贡献,就是统计区间内每一位是1的数的数量. 所以就写数位dp辣!(昨天才做了数字统计不要 ...
- C# 7.0特性与vs2017
下面是关于在C#7.0语言中计划功能的说明.其中大部分功能在Visual Studio “15” Preview 4中能运行.现在是最好的试用时期,请记录下你们的想法. C#7.0语言增加了许多的新功 ...
- LAMP架构之NFS
需求分析: 前端需支持更大的访问量,单台Web服务器已无法满足需求了,则需扩容Web服务器: 虽然动态内容可交由后端的PHP服务器执行,但静态页面还需要Web服务器自己解析,那是否意味着多台Web服务 ...
- Git_自定义Git
在安装Git一节中,我们已经配置了user.name和user.email,实际上,Git还有很多可配置项. 比如,让Git显示颜色,会让命令输出看起来更醒目: $ git config --glob ...
- JS简单实现二级联动菜单
<form method="post" action=""> 省/市:<select id="province" onch ...
- [Android] 字体使用dp单位避免设置系统字体大小对排版的影响
[Android] 字体使用dp单位避免设置系统字体大小对排版的影响 以魄族mx3为例,在设置->显示->字体大小中能够选择字号大小例如以下图: 图1. 魄族mx3 会导致软件在有固定定高 ...