Azkaban(三)Azkaban的使用
界面介绍
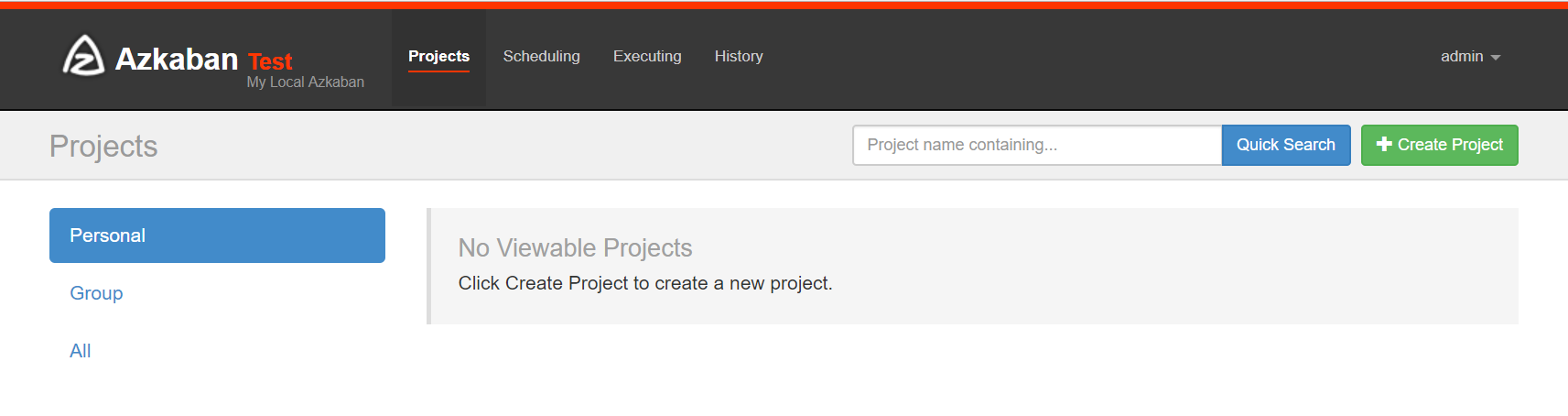
首页有四个菜单
- projects:最重要的部分,创建一个工程,所有flows将在工程中运行。
- scheduling:显示定时任务
- executing:显示当前运行的任务
- history:显示历史运行任务
介绍projects部分
概念介绍
创建工程:创建之前我们先了解下之间的关系,一个工程包含一个或多个flows,一个flow包含多个job。job是你想在azkaban中运行的一个进程,可以是简单的linux命令,可是java程序,也可以是复杂的shell脚本,当然,如果你安装相关插件,也可以运行插件。一个job可以依赖于另一个job,这种多个job和它们的依赖组成的图表叫做flow。
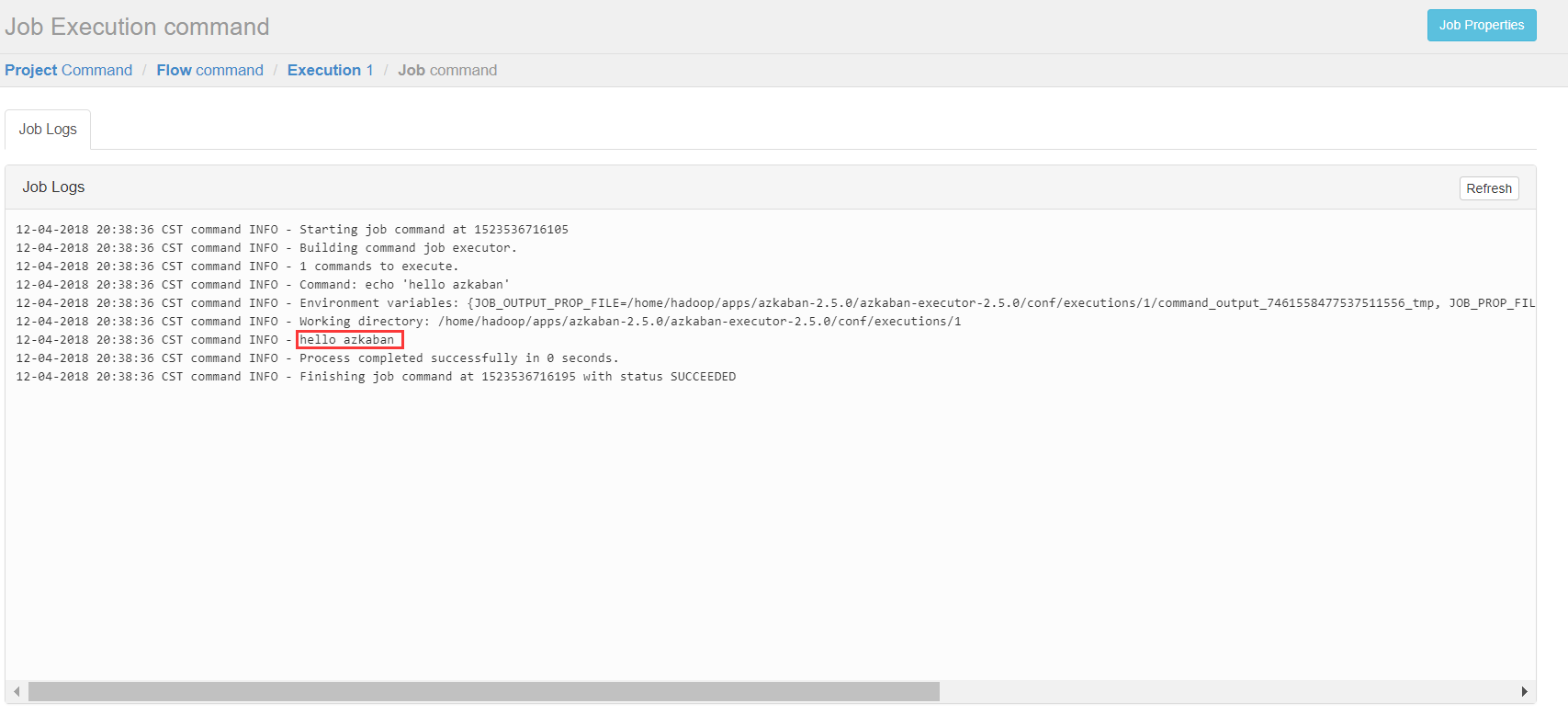
1、Command 类型单一 job 示例
(1)首先创建一个工程,填写名称和描述
(2)点击创建之后
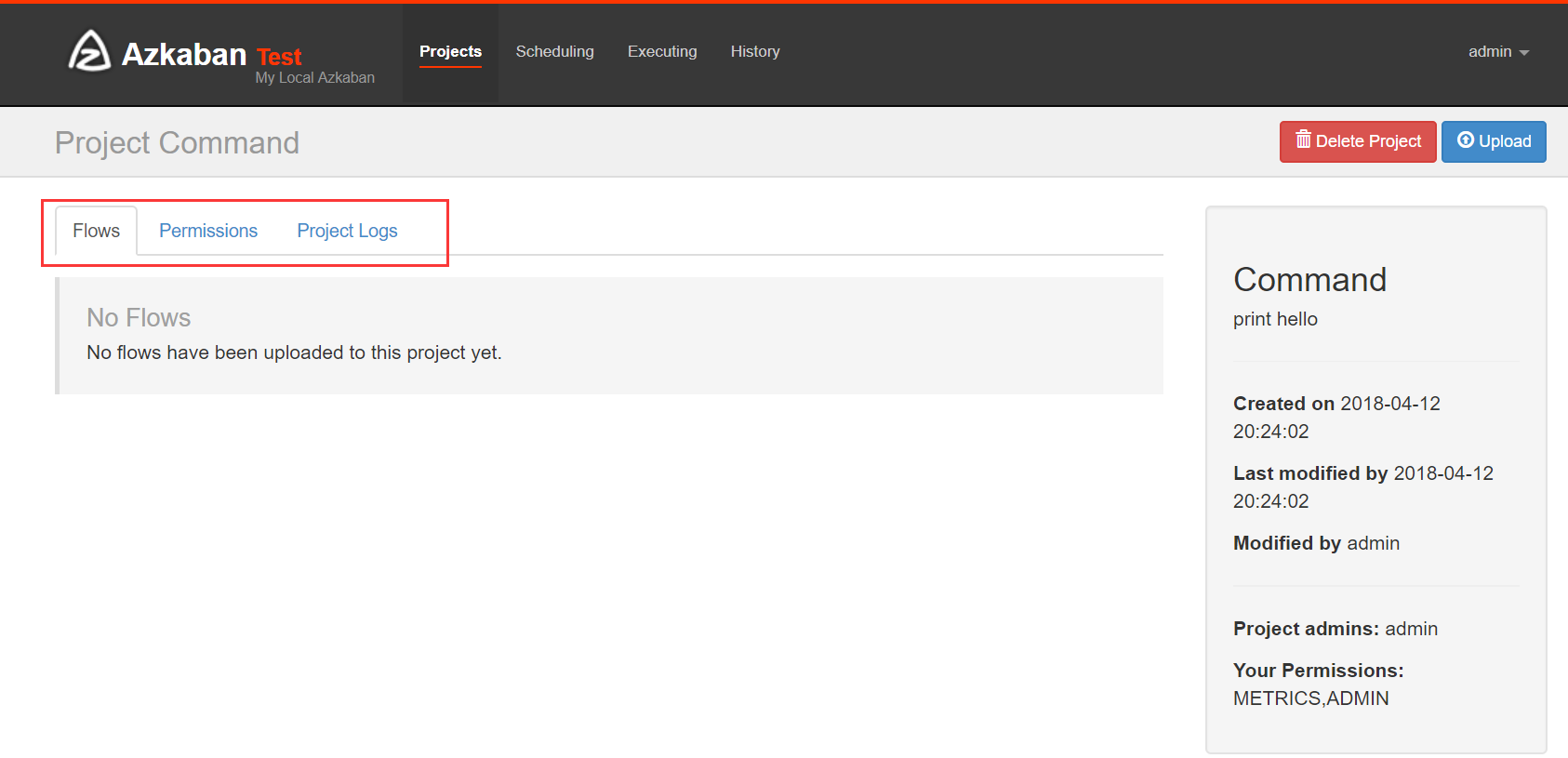
Flows:工作流程,有多个job组成
Permissions:权限管理
Project Logs:工程日志
(3)job的创建
创建job很简单,只要创建一个以.job结尾的文本文件就行了,例如我们创建一个工作,用来打印hello,名字叫做command.job
#command.job
type=command
command=echo 'hello'
一个工程不可能只有一个job,我们现在创建多个依赖job,这也是采用azkaban的首要目的。
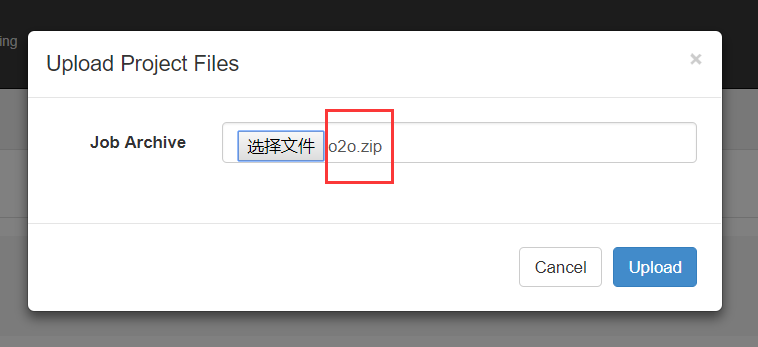
(4)将 job 资源文件打包
注意:只能是zip格式
(5)通过 azkaban web 管理平台创建 project 并上传压缩包
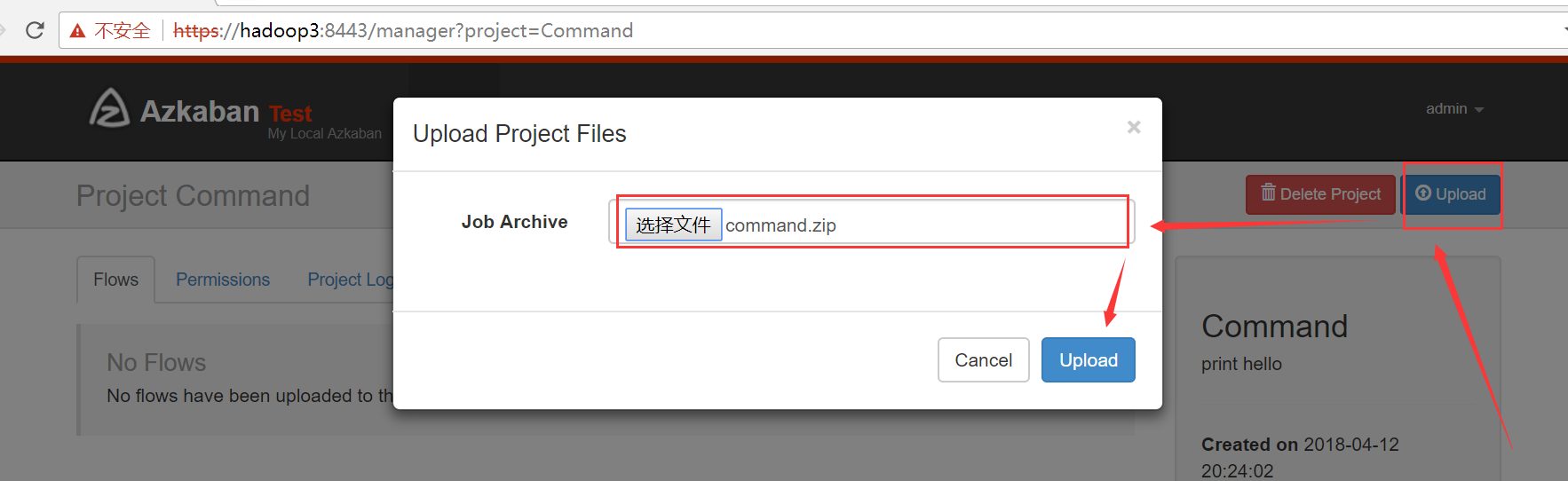
2、Command 类型多 job 工作流 flow
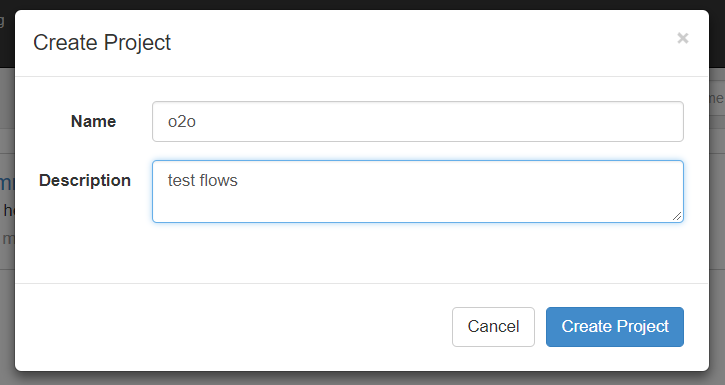
(1)创建项目
我们说过多个jobs和它们的依赖组成flow。怎么创建依赖,只要指定dependencies参数就行了。比如导入hive前,需要进行数据清洗,数据清洗前需要上传,上传之前需要从ftp获取日志。
定义5个job:
1、o2o_2_hive.job:将清洗完的数据入hive库
2、o2o_clean_data.job:调用mr清洗hdfs数据
3、o2o_up_2_hdfs.job:将文件上传至hdfs
4、o2o_get_file_ftp1.job:从ftp1获取日志
5、o2o_get_file_fip2.job:从ftp2获取日志
依赖关系:
3依赖4和5,2依赖3,1依赖2,4和5没有依赖关系。
o2o_2_hive.job
type=command
# 执行sh脚本,建议这样做,后期只需维护脚本就行了,azkaban定义工作流程
command=sh /job/o2o_2_hive.sh
dependencies=o2o_clean_data
o2o_clean_data.job
type=command
# 执行sh脚本,建议这样做,后期只需维护脚本就行了,azkaban定义工作流程
command=sh /job/o2o_clean_data.sh
dependencies=o2o_up_2_hdfs
o2o_up_2_hdfs.job
type=command
#需要配置好hadoop命令,建议编写到shell中,可以后期维护
command=hadoop fs -put /data/*
#多个依赖用逗号隔开
dependencies=o2o_get_file_ftp1,o2o_get_file_ftp2
o2o_get_file_ftp1.job
type=command
command=wget "ftp://file1" -O /data/file1
o2o_get_file_ftp2.job
type=command
command=wget "ftp:file2" -O /data/file2
可以运行unix命令,也可以运行python脚本(强烈推荐)。将上述job打成zip包。
ps:为了测试流程,我将上述command都改为echo +相应命令





(2)上传
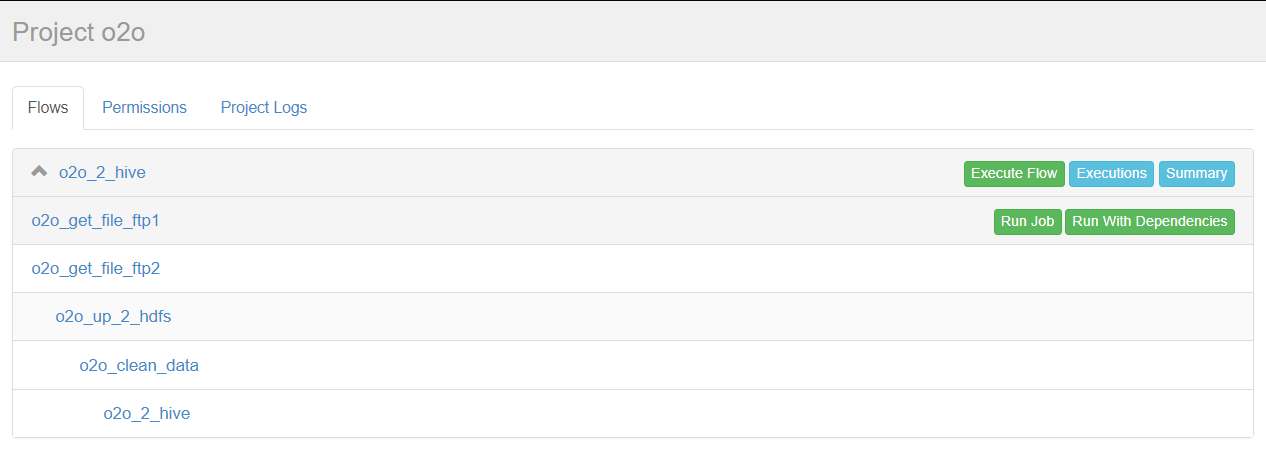
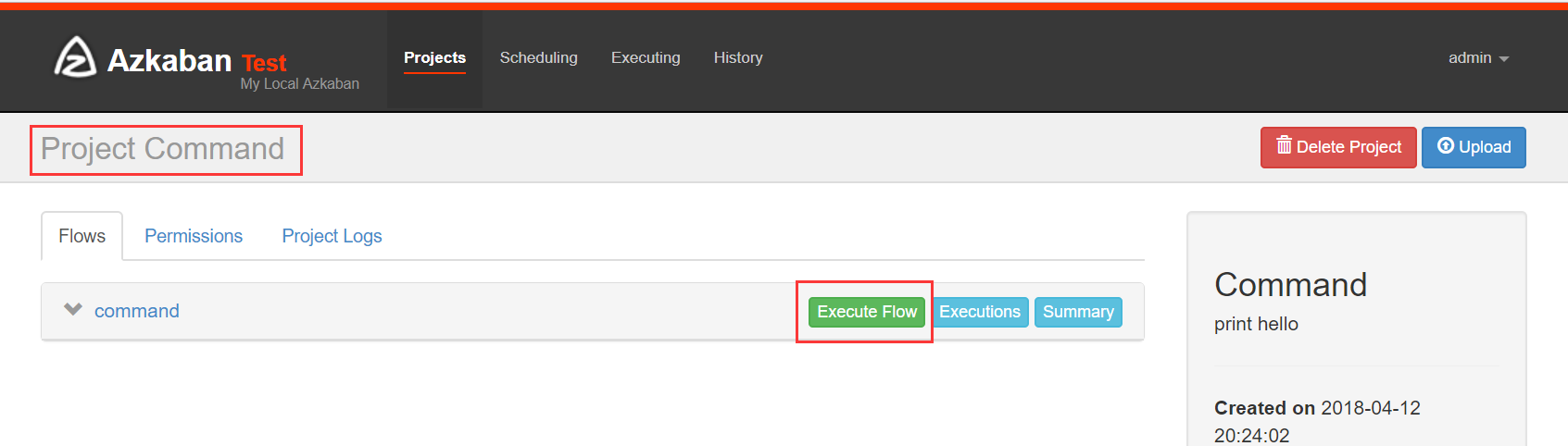
点击o2o_2_hive进入流程,azkaban流程名称以最后一个没有依赖的job定义的。

右上方是配置执行当前流程或者执行定时流程。
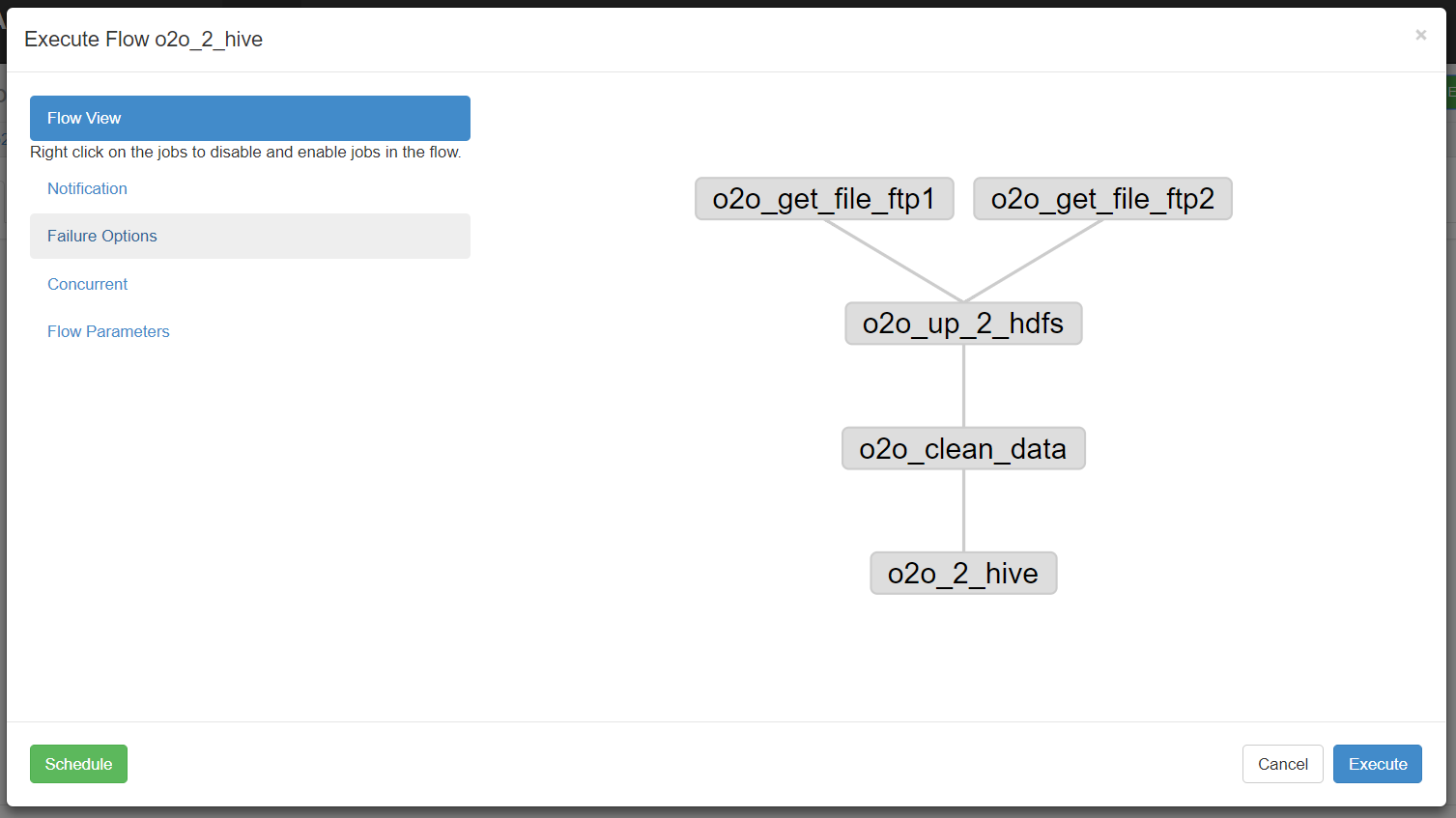
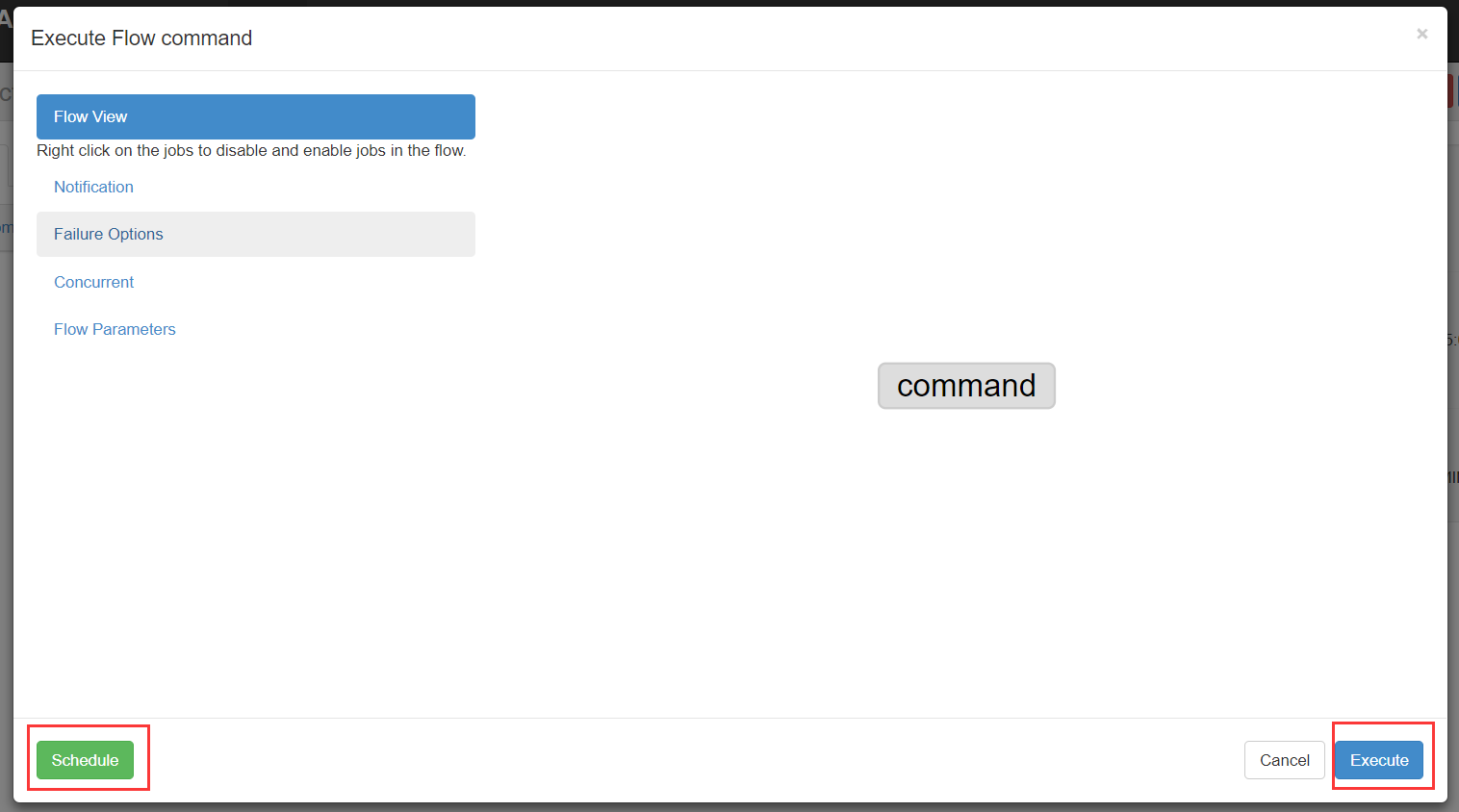
说明
Flow view:流程视图。可以禁用,启用某些job
Notification:定义任务成功或者失败是否发送邮件
Failure Options:定义一个job失败,剩下的job怎么执行
Concurrent:并行任务执行设置
Flow Parametters:参数设置。
(3)执行一次
设置好上述参数,点击execute。
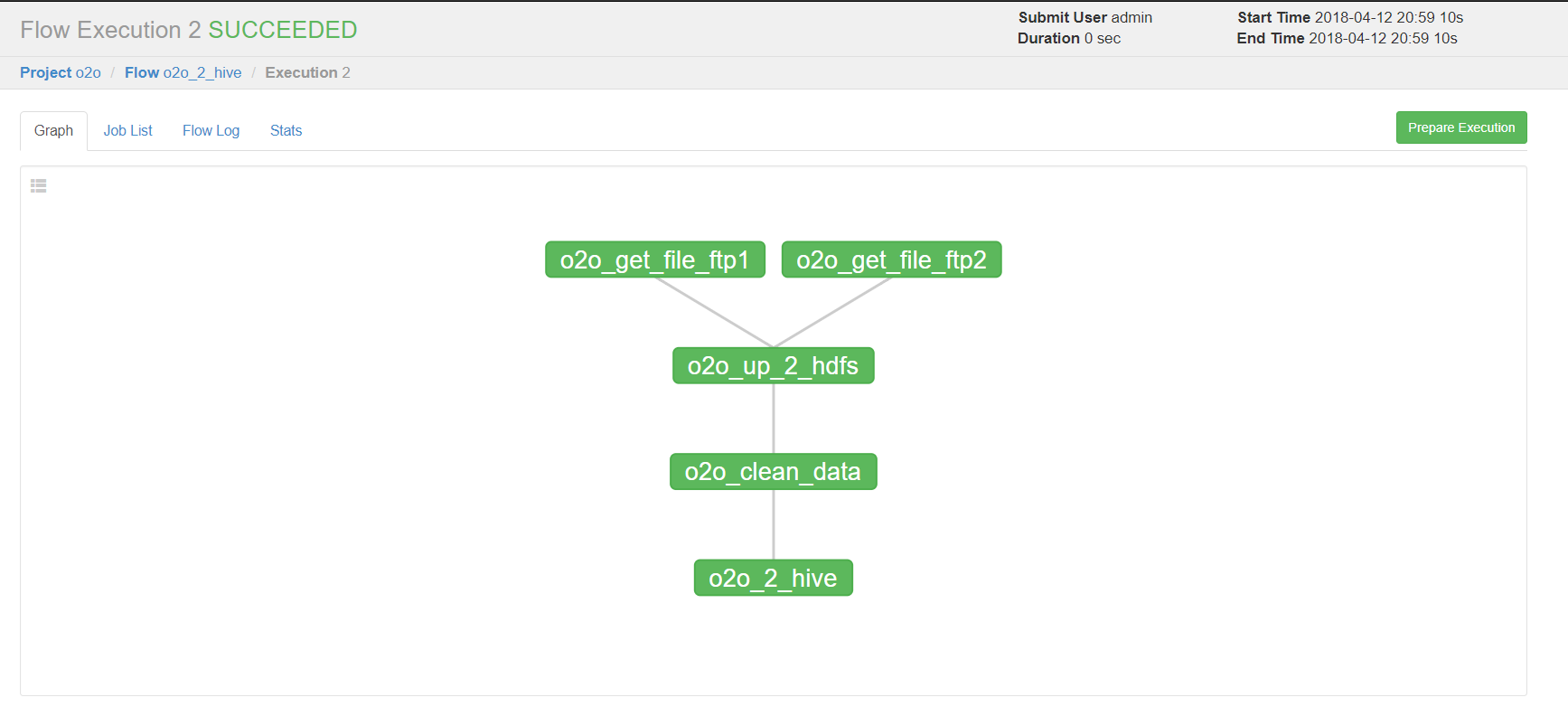
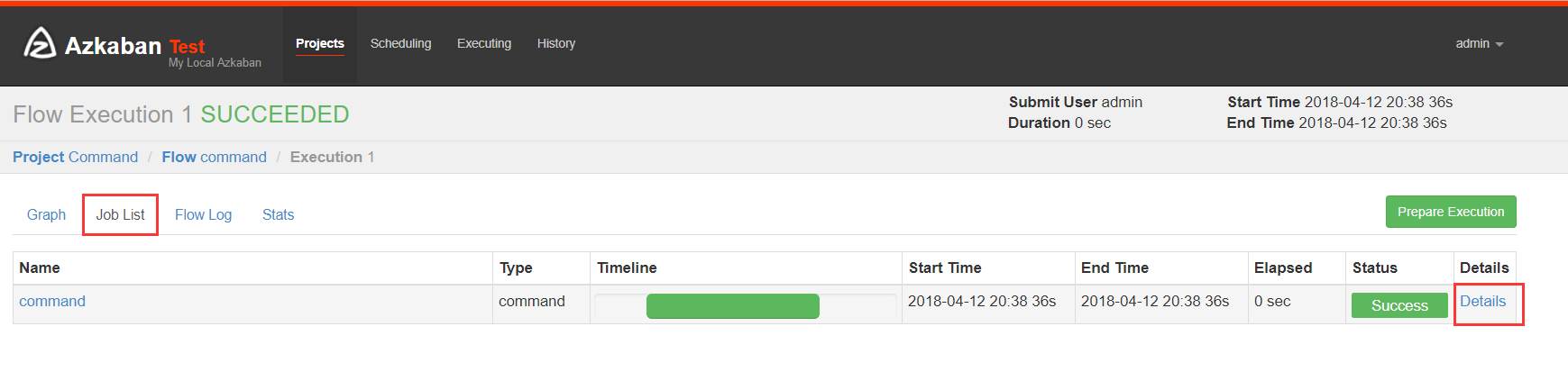
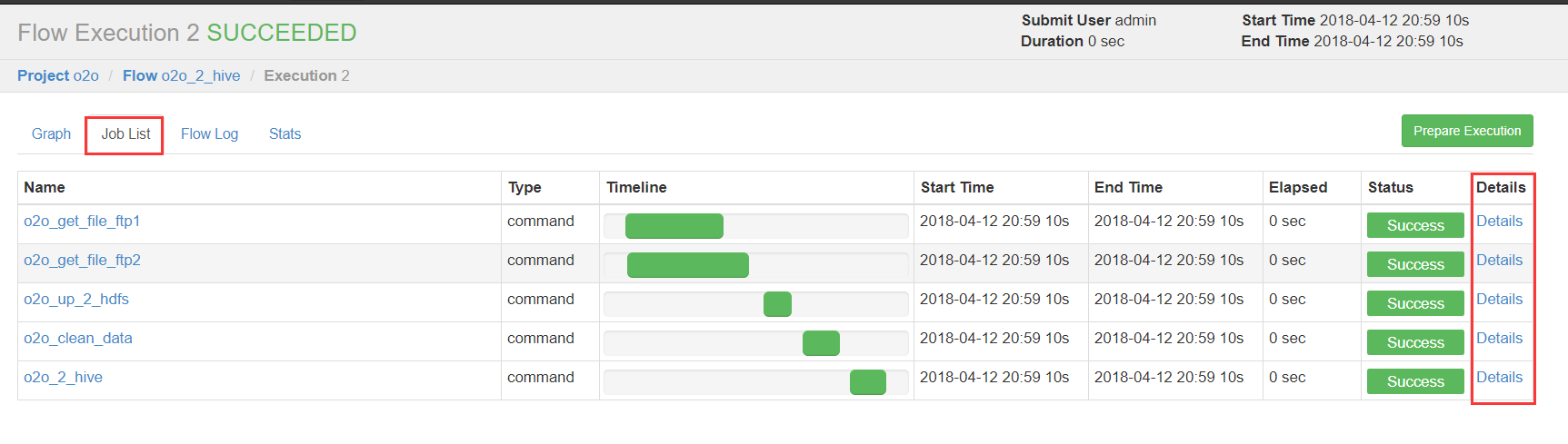
绿色代表成功,蓝色是运行,红色是失败。可以查看job运行时间,依赖和日志,点击details可以查看各个job运行情况。
(4)执行定时任务
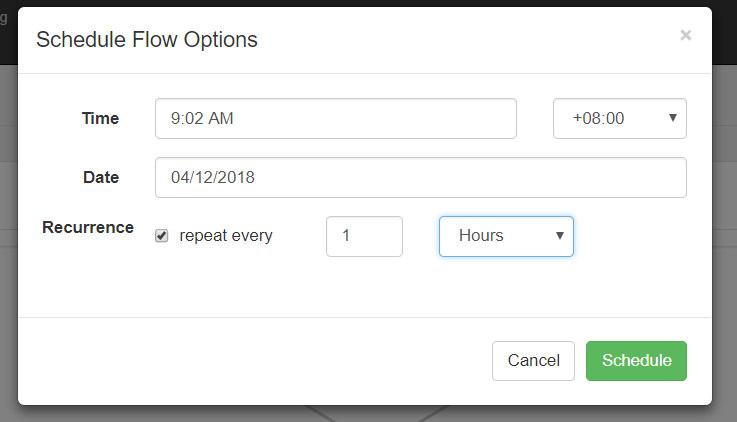
这时候注意到cst了吧,之前需要将配置中时区改为Asia/shanghai。
可以选择"天/时/分/月/周"等执行频率。

可以查看下次执行时间。
3、操作 MapReduce 任务
(1)创建 job 描述文件
mapreduce_wordcount.job
# mapreduce_wordcount.job
type=command
dependencies=mapreduce_pi
command=/home/hadoop/apps/hadoop-2.7.5/bin/hadoop
jar
/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar
wordcount /wordcount/input /wordcount/output_azkaban
mapreduce_pi.job
# mapreduce_pi.job
type=command
command=/home/hadoop/apps/hadoop-2.7.5/bin/hadoop
jar
/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar
pi 5 5
(2)创建 project 并上传 zip 包

(3)启动执行

4、Hive 脚本任务
(1) 创建 job 描述文件和 hive 脚本
Hive 脚本如下
test.sql
create database if not exists azkaban;
use azkaban;
drop table if exists student;
create table student(id int,name string,sex string,age int,deparment string) row format delimited fields terminated by ',';
load data local inpath '/home/hadoop/student.txt' into table student;
create table student_copy as select * from student;
insert overwrite directory '/aztest/hiveoutput' select count(1) from student_copy;
!hdfs dfs -cat /aztest/hiveoutput/000000_0;
drop database azkaban cascade;
Job 描述文件:
hivef.job
# hivef.job
type=command
command=/home/hadoop/apps/apache-hive-2.3.3-bin/bin/hive -f 'test.sql'
(2)将所有 job 资源文件打到一个 zip 包中
(3)在 azkaban 的 web 管理界面创建工程并上传 zip 包
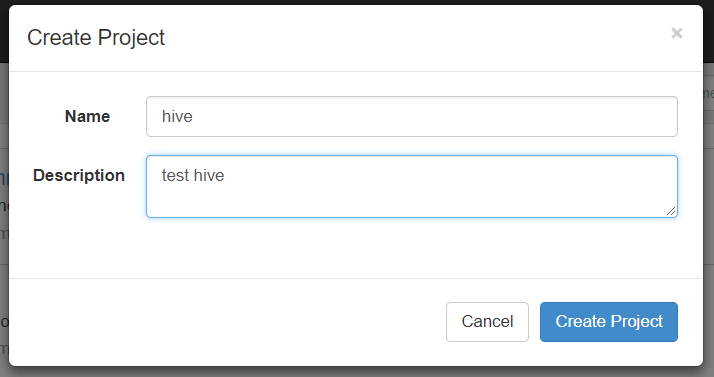
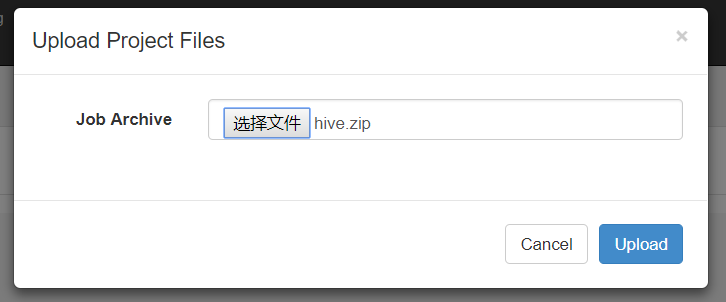
5、启动 job
Azkaban(三)Azkaban的使用的更多相关文章
- 分布式计算(三)Azkaban介绍
转载自:Azkaban学习之路 (一)Azkaban的基础介绍 目录 一.为什么需要工作流调度器 二.工作流调度实现方式 三.常见工作流调度系统 四.各种调度工具对比 五.Azkaban 与 Oozi ...
- Azkaban学习之路 (三)Azkaban的使用
界面介绍 首页有四个菜单 projects:最重要的部分,创建一个工程,所有flows将在工程中运行. scheduling:显示定时任务 executing:显示当前运行的任务 history:显示 ...
- 初识Azkaban
先说下hadoop 内置工作流的不足 (1)支持job单一 (2)硬编码 (3)无可视化 (4)无调度机制 (5)无容错机制 在这种情况下Azkaban就出现了 1)Azkaban是什么 Azkaba ...
- Azkaban 2.5.0 搭建
一.前言 最近试着参照官方文档搭建 Azkaban,发现文档很多地方有坑,所以在此记录一下. 二.环境及软件 安装环境: 系统环境: ubuntu-12.04.2-server-amd64 安装目录: ...
- hadoop工作流引擎之azkaban [转]
介绍 Azkaban是twitter出的一个任务调度系统,操作比Oozie要简单很多而且非常直观,提供的功能比较简单.Azkaban以Flow为执行单元进行定时调度,Flow就是预定义好的由一个或多个 ...
- Oozie和Azkaban的技术选型和对比
1 两种调度工具功能对比图 下面的表格对上述2种hadoop工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一致,但在设计理念,目标用户,应用场景等方面还是存在区别 特性 ...
- hadoop工作流引擎之azkaban
Azkaban是twitter出的一个任务调度系统,操作比Oozie要简单很多而且非常直观,提供的功能比较简单.Azkaban以Flow为执行单元进行定时调度,Flow就是预定义好的由一个或多个可存在 ...
- Azkaban 2.5.0 搭建和一些小问题
安装环境: 系统环境: ubuntu-12.04.2-server-amd64 安装目录: /usr/local/ae/ankaban JDK 安装目录: export JAVA_HOME=/usr/ ...
- 工作流调度器azkaban(以及各种工作流调度器比对)
1:工作流调度系统的作用: (1):一个完整的数据分析系统通常都是由大量任务单元组成:比如,shell脚本程序,java程序,mapreduce程序.hive脚本等:(2):各任务单元之间存在时间先后 ...
随机推荐
- SQL Server 2012安装图解
SQL Server 2012 Enterprise Edition安装图解... 第一部分:安装前的准备 1.疑问:一个PC上可以安装多个SQL Server数据库么 答案:可以的.每一个安装的时候 ...
- Integer两种转int方法比较
方法一: Integer.parseInt(); 返回的是一个 int 的值. 方法二: new Integer.valueof(); 返回的是 Integer 的对象. new Integer.va ...
- python---基础知识回顾(八)数据库基础操作(sqlite和mysql)
一:sqlite操作 SQLite是一种嵌入式数据库,它的数据库就是一个文件.由于SQLite本身是C写的,而且体积很小,所以,经常被集成到各种应用程序中,甚至在iOS和Android的App中都可以 ...
- 让页面无刷新的AJAX、ASP.NET核心知识(9)
AJAX简介 1.如果没有AJAX 普通的ASP.Net每次执行服务端方法的时候都要刷新当前页面,如果没有ajax,在youku看视频的过程中,就没法提交评论,页面会刷新,视频会被打断. 2.说说AJ ...
- 微服务深入浅出(11)-- SpringBoot整合Docker
添加Dockerfile 在目录src/main/resources目录下店家Dockerfile文件: From java MAINTAINER "Eric"<eric.l ...
- HDU 2097 Sky数 进制转换
解题报告:这题就用一个进制转换的函数就可以了,不需要转换成相应的进制数,只要求出相应进制的数的各位的和就可以了. #include<cstdio> #include<string&g ...
- Eclipse配置C++环境
由于实在不想用(界面太丑,超级强迫症),前段时间JAVA一直用eclipse,感觉这个IDE非常友好,看上去很舒服,下载的时候发现有C++版本,于是折腾了一会儿,谷歌上发现好多教程,但是大部分比较老, ...
- select标签的描述
1.标签html与js如下代码 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"&g ...
- Python练习-不知道弄个什么鬼
Alex大神,今天丢过来一个PDF,结果就成了这个样子! 1. 执行 Python 脚本的两种方式 交互方式: 命令行 文件方式: ...
- 【译】第八篇 Integration Services:高级工作流管理
本篇文章是Integration Services系列的第八篇,详细内容请参考原文. 简介在前面两篇文章,我们创建了一个新的SSIS包,学习了SSIS中的脚本任务和优先约束,并检查包的MaxConcu ...