第三章 LinkedList源码解析
一、对于LinkedList需要掌握的八点内容
- LinkedList的创建:即构造器
- 往LinkedList中添加对象:即add(E)方法
- 获取LinkedList中的单个对象:即get(int index)方法
- 修改LinkedList中的指定索引的节点的数据set(int index, E element)
- 删除LinkedList中的对象:即remove(E),remove(int index)方法
- 遍历LinkedList中的对象:即iterator,在实际中更常用的是增强型的for循环去做遍历
- 判断对象是否存在于LinkedList中:contain(E)
- LinkedList中对象的排序:主要取决于所采取的排序算法(以后讲)
二、源码分析
2.1、LinkedList的创建
实现方式:
List<String> strList0 = new LinkedList<String>();
源代码:在读源代码之前,首先要知道什么是环形双向链表,参考《算法导论(第二版)》P207
private transient Entry<E> header = new Entry<E>(null, null, null);//底层是双向链表,这时先初始化一个空的header节点
private transient int size = 0;//链表中的所存储的元素个数 /**
* 构造环形双向链表
*/
public LinkedList() {
header.next = header.previous = header;//形成环形双向链表
}
Entry是LinkedList的一个内部类:
/**
* 链表节点
*/
private static class Entry<E> {
E element; //链表节点所存储的数据
Entry<E> next; //当前链表节点的下一节点
Entry<E> previous; //当前链表节点的前一个节点 Entry(E element, Entry<E> next, Entry<E> previous) {
this.element = element;
this.next = next;
this.previous = previous;
}
}
执行完上述的无参构造器后:形成的空环形双向链表如下:
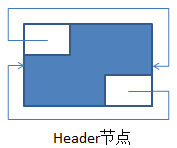
其中,左上角为previous,右下角为next
2.2、往LinkedList中添加对象(add(E e))
实现方式:
strList0.add("hello");
源代码:
/**
* 在链表尾部增加新节点,新节点封装的数据为e
*/
public boolean add(E e) {
addBefore(e, header);//在链表尾部增加新节点,新节点封装的数据为e
return true;
}
/*
* 在链表指定节点entry后增加新节点,新节点封装的数据为e
*/
private Entry<E> addBefore(E e, Entry<E> entry) {
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
newEntry.previous.next = newEntry;//新节点的前一个节点的下一节点为该新节点
newEntry.next.previous = newEntry;//新节点的下一个节点的前一节点为该新节点
size++; //链表中元素个数+1
modCount++; //与ArrayList相同,用于在遍历时查看是否发生了add和remove操作
return newEntry;
}
在添加一个元素后的新环形双向链表如下:
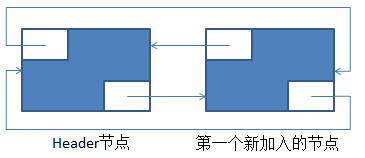
在上述的基础上,再调用一次add(E)后,新的环形双向链表如下:
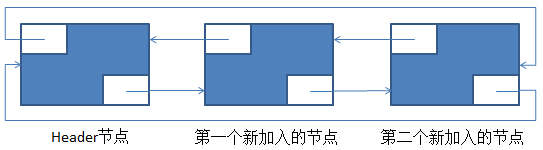
这里,结合着代码注释与图片去看add(E)的源代码就好。
注意:在添加元素方面LinkedList不需要考虑数组扩容和数组复制,只需要新建一个对象,但是需要修改前后两个对象的属性。
2.3、获取LinkedList中的单个对象(get(int index))
实现方式:
strList.get(0);//注意:下标从0开始
源代码:
/**
* 返回索引值为index节点的数据,index从0开始计算
*/
public E get(int index) {
return entry(index).element;
}
/**
* 获取指定index索引位置的节点(需要遍历链表)
*/
private Entry<E> entry(int index) {
//index:0~size-1
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index:"+index+", Size:"+size);
Entry<E> e = header;//头节点:既作为头节点也作为尾节点
if (index < (size >> 1)) {//index<size/2,则说明index在前半个链表中,从前往后找
for (int i = 0; i <= index; i++)
e = e.next;
} else {//index>=size/2,则说明index在后半个链表中,从后往前找
for (int i = size; i > index; i--)
e = e.previous;
}
return e;
}
注意:
- 链表节点的按索引查找,需要遍历链表;而数组不需要。
- header节点既是头节点也是尾节点
- 双向链表的查找,先去判断索引值index是否小于size/2,若小于,从header节点开始,从前往后找;若大于等于,从header节点开始,从后往前找
- size>>1,右移一位等于除以2;左移一位等于乘以2
2.4、修改LinkedList中指定索引的节点的数据:set(int index, E element)
使用方式:
strList.set(0, "world");
源代码:
/**
* 修改指定索引位置index上的节点的数据为element
*/
public E set(int index, E element) {
Entry<E> e = entry(index);//查找index位置的节点
E oldVal = e.element;//获取该节点的旧值
e.element = element;//将新值赋给该节点的element属性
return oldVal;//返回旧值
}
注意:entry(int index)查看上边
2.5、删除LinkedList中的对象
2.5.1、remove(Object o)
使用方式:
strList.remove("world")
源代码:
/**
* 删除第一个出现的指定元数据为o的节点
*/
public boolean remove(Object o) {
if (o == null) {//从前往后删除第一个null
//遍历链表
for (Entry<E> e = header.next; e != header; e = e.next) {
if (e.element == null) {
remove(e);
return true;
}
}
} else {
for (Entry<E> e = header.next; e != header; e = e.next) {
if (o.equals(e.element)) {
remove(e);
return true;
}
}
}
return false;
}
/*
* 删除节点e
*/
private E remove(Entry<E> e) {
//header节点不可删除
if (e == header)
throw new NoSuchElementException(); E result = e.element;
//调整要删除节点的前后节点的指针指向
e.previous.next = e.next;
e.next.previous = e.previous;
//将要删除元素的三个属性置空
e.next = e.previous = null;
e.element = null; size--;//size-1
modCount++;
return result;
}
注意:
- header节点不可删除
2.5.2、remove(int index)
使用方式:
strList.remove(0);
源代码:
/**
* 删除指定索引的节点
*/
public E remove(int index) {
return remove(entry(index));
}
注意:
- remove(entry(index))见上边
- remove(Object o)需要遍历链表,remove(int index)也需要
2.6、判断对象是否存在于LinkedList中(contains(E))
源代码:
/**
* 链表中是否包含指定数据o的节点
*/
public boolean contains(Object o) {
return indexOf(o) != -1;
}
/**
* 从header开始,查找第一个出现o的索引
*/
public int indexOf(Object o) {
int index = 0;
if (o == null) {//从header开始,查找第一个出现null的索引
for (Entry e = header.next; e != header; e = e.next) {
if (e.element == null)
return index;
index++;
}
} else {
for (Entry e = header.next; e != header; e = e.next) {
if (o.equals(e.element))
return index;
index++;
}
}
return -1;
}
注意:
- indexOf(Object o)返回第一个出现的元素o的索引
2.7、遍历LinkedList中的对象(iterator())
使用方式:
List<String> strList = new LinkedList<String>();
strList.add("jigang");
strList.add("nana");
strList.add("nana2"); Iterator<String> it = strList.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
源代码:iterator()方法是在父类AbstractSequentialList中实现的,
public Iterator<E> iterator() {
return listIterator();
}
listIterator()方法是在父类AbstractList中实现的,
public ListIterator<E> listIterator() {
return listIterator(0);
}
listIterator(int index)方法是在父类AbstractList中实现的,
public ListIterator<E> listIterator(final int index) {
if (index < 0 || index > size())
throw new IndexOutOfBoundsException("Index: " + index);
return new ListItr(index);
}
该方法返回AbstractList的一个内部类ListItr对象
ListItr:
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
cursor = index;
}
上边这个类并不完整,它继承了内部类Itr,还扩展了一些其他方法(eg.向前查找方法hasPrevious()等),至于hasNext()/next()等方法还是来自于Itr的。
Itr:
private class Itr implements Iterator<E> {
int cursor = 0;//标记位:标记遍历到哪一个元素
int expectedModCount = modCount;//标记位:用于判断是否在遍历的过程中,是否发生了add、remove操作
//检测对象数组是否还有元素
public boolean hasNext() {
return cursor != size();//如果cursor==size,说明已经遍历完了,上一次遍历的是最后一个元素
}
//获取元素
public E next() {
checkForComodification();//检测在遍历的过程中,是否发生了add、remove操作
try {
E next = get(cursor++);
return next;
} catch (IndexOutOfBoundsException e) {//捕获get(cursor++)方法的IndexOutOfBoundsException
checkForComodification();
throw new NoSuchElementException();
}
}
//检测在遍历的过程中,是否发生了add、remove等操作
final void checkForComodification() {
if (modCount != expectedModCount)//发生了add、remove操作,这个我们可以查看add等的源代码,发现会出现modCount++
throw new ConcurrentModificationException();
}
}
注:
- 上述的Itr我去掉了一个此时用不到的方法和属性。
- 这里的get(int index)方法参照2.3所示。
三、总结
- LinkedList基于环形双向链表方式实现,无容量的限制
- 添加元素时不用扩容(直接创建新节点,调整插入节点的前后节点的指针属性的指向即可)
- 线程不安全
- get(int index):需要遍历链表
- remove(Object o)需要遍历链表
- remove(int index)需要遍历链表
- contains(E)需要遍历链表
第三章 LinkedList源码解析的更多相关文章
- 第三章 CopyOnWriteArrayList源码解析
注:在看这篇文章之前,如果对ArrayList底层不清楚的话,建议先去看看ArrayList源码解析. http://www.cnblogs.com/java-zhao/p/5102342.html ...
- LinkedList源码解析
LinkedList是基于链表结构的一种List,在分析LinkedList源码前有必要对链表结构进行说明.1.链表的概念链表是由一系列非连续的节点组成的存储结构,简单分下类的话,链表又分为单向链表和 ...
- Java集合:LinkedList源码解析
Java集合---LinkedList源码解析 一.源码解析1. LinkedList类定义2.LinkedList数据结构原理3.私有属性4.构造方法5.元素添加add()及原理6.删除数据re ...
- 第十四章 Executors源码解析
前边两章介绍了基础线程池ThreadPoolExecutor的使用方式.工作机理.参数详细介绍以及核心源码解析. 具体的介绍请参照: 第十二章 ThreadPoolExecutor使用与工作机理 第十 ...
- 第九章 LinkedBlockingQueue源码解析
1.对于LinkedBlockingQueue需要掌握以下几点 创建 入队(添加元素) 出队(删除元素) 2.创建 Node节点内部类与LinkedBlockingQueue的一些属性 static ...
- 第六章 ReentrantLock源码解析2--释放锁unlock()
最常用的方式: int a = 12; //注意:通常情况下,这个会设置成一个类变量,比如说Segement中的段锁与copyOnWriteArrayList中的全局锁 final Reentrant ...
- Java集合---LinkedList源码解析
一.源码解析1. LinkedList类定义2.LinkedList数据结构原理3.私有属性4.构造方法5.元素添加add()及原理6.删除数据remove()7.数据获取get()8.数据复制clo ...
- ava集合---LinkedList源码解析
一.源码解析 public class LinkedList<E> extends AbstractSequentialList<E> implements List<E ...
- 【vuejs深入三】vue源码解析之二 htmlParse解析器的实现
写在前面 一个好的架构需要经过血与火的历练,一个好的工程师需要经过无数项目的摧残. 昨天博主分析了一下在vue中,最为基础核心的api,parse函数,它的作用是将vue的模板字符串转换成ast,从而 ...
随机推荐
- PHP模板引擎,Smarty定义
PHP模板引擎:PHP是一种HTML内嵌式的在服务器端执行的脚本语言.初始的开发模板就是混合 层的数据编程,虽然通过MVC的设计模式可以实现将程序的应用逻辑与网页的呈现逻辑强制 分离,但也只是将程序的 ...
- php中explode和implode函数
explode array explode ( string $delimiter, string $string, [ , $limit ] ) 函数返回由字符串组成的数组,每个元素都是string ...
- Python 学习经历分享
如果说 Java 是亲儿子的话,那么 Python 应该就是干儿子了.看了一下所有关于 Python 的笔记,我发现原来我在 4 月份的时候就已经涉足 Python 了,但是到目前为止才真正算做出了一 ...
- shell run 屏蔽一切log
&命令: xxx >/dev/null 2>&1 & 屏蔽一切logxxx >/tmp/xxx.log 2 ...
- Java与GIS的联系
Java与GIS的联系 地理信息系统是70年代初发展起来的一门新兴的边缘学科. 由于GIS在数据采集与输入.空间数据管理.地图提取.自动制图.数字地形分析.数据输出等方面具有强大而又独特的功能 ...
- [BZOJ4561][JLOI2016]圆的异或并(扫描线)
考虑任何一条垂直于x轴的直线,由于圆不交,所以这条直线上的圆弧构成形似括号序列的样子,且直线移动时圆之间的相对位置不变. 将每个圆拆成两边,左端加右端删.每次加圆时考虑它外面最内层的括号属于谁.用se ...
- 中国气象局某分院官网漏洞打包(弱口令+SQL注入+padding oracle)
漏洞一.后台弱口令 后台地址:http://www.hnmatc.org/admin/ 直接爆破得到账号admin 密码admin888 漏洞二.SQL注入(前台后台都有) 注入点:http://w ...
- 【2017多校训练08 1002】【HDOJ 6134】Battlestation Operational
典型的数列反演题. 运用莫比乌斯反演的一个结论 $[n = 1] = \sum_{d | n} \mu(d)$,将表达式做如下转化: $$ ans = \sum_{i=1}^n \sum_{j=1}^ ...
- bzoj 4017 子序列和的异或以及异或的和
位运算很好的一个性质是可以单独每一位考虑..... 题解请看:http://blog.csdn.net/skywalkert/article/details/45401245 对于异或的和,先枚举位, ...
- python开发_configparser_解析.ini配置文件工具_完整版_博主推荐
# # 最近出了一趟差,是从20号去的,今天回来... # 就把最近学习的python内容给大家分享一下... # ''' 在python中,configparser模块提供了操作*.ini配置文件的 ...