hive--数据仓库
1.1.1 hive是什么?
Hive是基于 Hadoop 的一个数据仓库工具:
- 1. hive本身不提供数据存储功能,使用HDFS做数据存储;
- 2. hive也不分布式计算框架,hive的核心工作就是把sql语句翻译成MR程序;
- 3. hive也不提供资源调度系统,也是默认由Hadoop当中YARN集群来调度;
- 4. 可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能。
1.1.2 hive和Hadoop关系
Hive利用HDFS存储数据,利用MapReduce查询数据,聚合函数需要经过MapReduce,非聚合函数直接读取hdfs块信息,不通过MapReduce。
1.1.3 hive特点
- 可以将结构化的数据文件映射为一张数据库表(二维表),并提供类SQL查询功能
- 可以将sql语句转换为MapReduce任务进行运行。Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。
- Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。
- Hive的适应场景:只适合做海量离线数据的统计分析。
- Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
- 只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
- Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
1.1.4 hive数据的存储
db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在hdfs中表现所属db目录下一个文件夹
external table:与table类似,不过其数据存放位置可以在任意指定路径
partition:在hdfs中表现为table目录下的子目录
bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件
1.1.5 Hive 体系结构
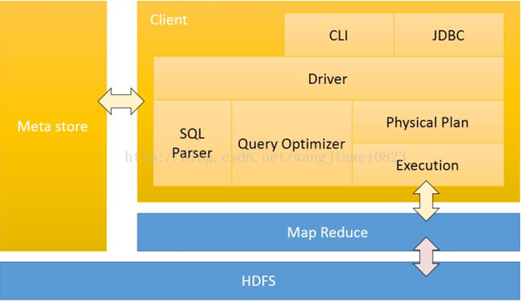

1.1.6 hive的架构原理
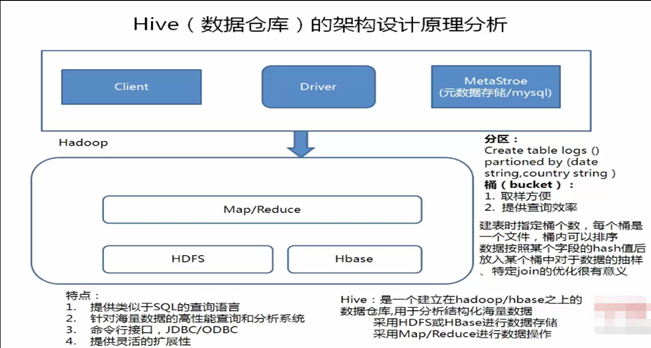
Driver是核心,Driver可以解析语法,最难的就是解析sql的语法,只要把SQL的语法解析知道怎么做了,它内部用MapReduce模板程序,它很容易把它组装起来,比如做一个join操作,最重要的是识别语法,认识你的语法,知道你语法有什么东西,解析出来会得到一个语法树,根据一些语法树,去找一些MapReduce模板程序,把它组装起来。
例如:有二个表去join,内部有一个优化机制,有一个默认值,如果小表小于默认值,就采用map—join ,如果小表大于默认值,就采用reduce——join(其中map——join是先把小表加载到内存中),组装时候就是输入一些参数:比如:你的输入数据在哪里,你的表数据的分隔符是什么,你的文件格式是什么:然而这些东西是我们建表的时候就指定了,所以这些都知道了,程序就可以正常的跑起来。
Hive有了Driver之后,还需要借助Metastore,Metastore里边记录了hive中所建的:库,表,分区,分桶的信息,描述信息都在Metastore,如果用了MySQL作为hive的Metastore:需要注意的是:你建的表不是直接建在MySQL里,而是把这个表的描述信息放在了MySQL里,而tables表,字段表是存在HDFS上的hive表上,hive会自动把他的目录规划/usr/hive/warehouse/库文件/库目录/表目录,你的数据就在目录下
1.1.7 内外表
内部表在删除表的时候,会删除元数据和数据;外部表在删除表的时候,只删除元数据,不删除数据
内部表和外部表使用场景:
- 一般情况来说,如果数据只交给hive处理,那么一般直接使用内部表;
- 如果数据需要多个不同的组件进行处理,那么最好用外部表,一个目录的数据需要被spark、hbase等其他组件使用,并且hive也要使用,那么该份数据通过创建一张临时表为外部表,然后通过写HQL语句转换该份数据到hive内部表中
1.1.8 分桶
分桶操作:按照用户创建表时指定的分桶字段进行hash散列,跟MapReduce中的HashPartitioner的原理一模一样。
MapReduce中:按照key的hash值去模除以reductTask的个数;Hive中:按照分桶字段的hash值去模除以分桶的个数
hive分桶操作的效果:把一个文件按照某个特定的字段和桶数散列成多个文件好处:
1、方便抽样;
2、提高join查询效率
1.1.9 Hive分区
做统计的时候少统计,把我们的数据放在多个文件夹里边,我们统计时候,可以指定分区,这样范围就会小一些,这样就减少了运行的时间。
1.1.10 Hive 的所有跟数据相关的概念
db: myhive, table: student 元数据:hivedb
Hive的元数据指的是 myhive 和 student等等的库和表的相关的各种定义信息,该元数据都是存储在mysql中的:
- myhive是hive中的一个数据库的概念,其实就是HDFS上的一个文件夹,跟mysql没有多大的关系;
- myhive是hive中的一个数据库,那么就会在元数据库hivedb当中的DBS表中存储一个记录,这一条记录就是myhive这个hive中数据的相关描述信息。
- hive中创建一个库,就相当于是在hivedb中DBS(数据库)中插入一张表, 并且在HDFS上建立相应的目录—主目录;
- hive中创建一个表,就相当于在hivedb中TBLS(数据库中的表)表中插入一条记录,并且在HDFS上项目的库目录下创建一个子目录;
- 一个hive数据仓库就依赖于一个RDBMS(关系数据库管理系统)中的一个数据库,一个数据库实例对应于一个Hive数据仓库;
- 存储于该hive数据仓库中的所有数据的描述信息,都统统存储在元数据库hivedb中。
- Hive元数据 :描述和管理这些block信息的数据,由namenode管理,一定指跟 hivedb相关,跟mysql相关;
- Hive源数据-- block块: HDFS上的对应表的目录下的文件HDFS上的数据和元数据。
1.1.11 源数据与元数据
myhive 和 hivedb的区别:
- myhive是hive中的数据库: 用来存储真实数据—源数据;
- hivedb是mysql中的数据库: 用来多个类似myhive库的真实数据的描述数据—元数据;
1.1.12 Hive基本命令整理
创建表:CREATE TABLE pokes (foo INT, bar STRING);
Creates a table called pokes with
two columns, the first being an integer and the other a string
创建一个新表,结构与其他一样
hive> create table new_table like records;
创建分区表:
hive> create table logs(ts bigint,line string) partitioned by (dt
String,country String);
加载分区表数据:
hive> load data local inpath '/home/hadoop/input/hive/partitions/file1' into
table logs partition (dt='2001-01-01',country='GB');
展示表中有多少分区:
hive> show partitions logs;
展示所有表:
hive> SHOW TABLES;
lists all the tables
hive> SHOW TABLES '.*s';
lists all the table that end with 's'.
The pattern matching follows Java regular
expressions. Check out this link for documentation
显示表的结构信息
hive> DESCRIBE invites;
shows the list of columns
更新表的名称:
hive> ALTER TABLE source RENAME TO target;
添加新一列
hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');
删除表:
hive> DROP TABLE records;
删除表中数据,但要保持表的结构定义
hive> dfs -rmr /user/hive/warehouse/records;
从本地文件加载数据:
hive> LOAD DATA LOCAL INPATH '/home/hadoop/input/ncdc/micro-tab/sample.txt'
OVERWRITE INTO TABLE records;
显示所有函数:
hive> show functions;
查看函数用法:
hive> describe function substr;
查看数组、map、结构
hive> select col1[0],col2['b'],col3.c from complex;
其他同oracle相同
1.1.13 hive环境搭建
hive的元数据是存放在mysql中的,首先需要安装mysql数据库;然后修改hive配置文件,主要是数据库用户、密码、hadoop文件存放的路径等等。--请看mysql的环境搭建
hive--数据仓库的更多相关文章
- Hive数据仓库工具安装
一.Hive介绍 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单SQL查询功能,SQL语句转换为MapReduce任务进行运行. 优点是可以通过类S ...
- HIVE—数据仓库
1. hive是什么? Hive是基于 Hadoop 的一个数据仓库工具: 1. hive本身不提供数据存储功能,使用HDFS做数据存储: 2. hive也不分布式计算框架,h ...
- hive数据仓库建设
hive数据仓库建设 1.设计原生日志表 原生日志表用来存放上报的原始日志,数据经过清洗加工后会进入到各个日志表中. 1.1 创建数据库 #创建数据库 $hive>create database ...
- 高速查询hive数据仓库表中的总条数
Author: kwu 高速查询hive数据仓库中的条数.在查询hive表的条数,通常使用count(*).可是数据量大的时候,mr跑count(*)往往须要几分钟的时间. 1.传统方式获得总条数例如 ...
- Hive数据仓库你了解了吗
在工作中我们经常使用的数据库,数据库一般存放的我们系统中常用的数据,一般为百万级别.如果数据量庞大,达到千万级.亿级又需要对他们进行关联运算,该怎么办呢? 前面我们已经介绍了HDFS和MapReduc ...
- hive数据仓库入门到实战及面试
第一章.hive入门 一.hive入门手册 1.什么是数据仓库 1.1数据仓库概念 对历史数据变化的统计,从而支撑企业的决策.比如:某个商品最近一个月的销量,预判下个月应该销售多少,从而补充多少货源. ...
- 将CSV格式或者EXCEL格式的文件导入到HIVE数据仓库中
学习内容:数据导入,要求将CSV格式或者EXCEL格式的文件导入到HIVE数据仓库中: ①hive建表:test1 create table test1 (InvoiceNo String, Stoc ...
- Hive数据仓库工具基本架构和入门部署详解
@ 目录 概述 定义 本质 特点 Hive与Hadoop关系 Hive与关系型数据库区别 优缺点 其他说明 架构 组成部分 数据模型(Hive数据组织形式) Metastore(元数据) Compil ...
- Hive数据仓库
Hive 是一个基于Hadoop分布式文件系统(HDFS)之上的数据仓库架构,同时依赖于MapReduce.适用于大数据集的批处理,而不适用于低延迟快速查询. Hive将用户的HiveQL语句转换为M ...
- Hive数据仓库笔记(一)
Hive建表: CREATE TABLE records (year STRING,temperature INT, quality INT) ROW FORMAT DELIMITED FIELDS ...
随机推荐
- ADB指令大全
Android Debug Bridge version 1.0.26.26 -a - directs adb to listen on all interfaces for a connection ...
- 6.Spring MVC SSM整合问题总结
1.Cannot find class [org.springframework.http.converter.json.MappingJacksonHttpMessageConverter] for ...
- Oracle EBS 报错 您不具有分配给您的清除MDS的权限
- [翻译] SIAlertView
SIAlertView https://github.com/Sumi-Interactive/SIAlertView An UIAlertView replacement with block sy ...
- Celery学习---Celery 与django结合实现计划任务功能
项目的目录结构: 项目前提: 安装并启动Redis 安装Django和Celery的定时任务插件 安装方法一: pip直接安装[安装了pip的前提下] omc@omc-virtual-machine: ...
- Linux 系统的用户和组详解_【all】
1.Linux 用户和用户组详解 2.Linux 文件特殊权限详解 3.Linux 文件的读写执行权限的说明 4.Linux 架构之简述企业网站 5.Linux 环境变量设置详解 6.企业生产环境用户 ...
- 如何避免HBase写入过快引起的各种问题
首先我们简单回顾下整个写入流程 client api ==> RPC ==> server IPC ==> RPC queue ==> RPC handler ==> w ...
- ms17-010漏洞利用教程
ms17-010 漏洞利用并拿下服务器教程 攻击环境: 攻击机win2003 ip:192.168.150.129 Window2003 Python环境及工具 攻击机kali: ip:192.168 ...
- python 控制台单行刷新,多行刷新
先贴出单行刷新实现的进度条: 对于控制台的单行刷新,比较简单,先直接贴出代码: strarrs = ['/','|','\\'] for i in range(15): sys.stdout.writ ...
- SVN那些事
非原创,引用于青松世界博客,最近在使用svn,因为方便复制内容在这查看.原地址 https://www.cnblogs.com/Rambo635755402/p/5549447.html Totois ...