TF-IDF算法--关键词句和文本集中每篇文章相关度计算
关键词句和文本集每篇文章相关度计算:假设语料库中有几万篇文章,每篇文章的长度不一,你任意输入关键词或句子,通过代码以tf-idf值为准检索出来相似度高的文章。
- 1、TF-IDF概述
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TFIDF实际上是:TF * IDF。TF-IDF值与该词的出现频率成正比,与在整个语料库中的出现次数成反比。
- 2、词频(TF)和逆文档频率IDF
TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。
词频 (TF)= 某个词在文章中出现的总次数/文章的总词数,TF表示词条在文档d中出现的频率。
逆文档频率(IDF) = log(词料库的文档总数/包含该词的文档数+1),为了避免分母为0,所以在分母上加1.。IDF的主要思想是:如果包含该词的文档数越少,也就是log里面分母越小,IDF越大,则说明该词具有很好的类别区分能力。
- 3、停用词和语料库(已分好词)
停用词大致分为两类。一类是人类语言中包含的功能词,这些功能词极其普遍,与其他词相比,功能词没有什么实际含义,比如'the'、'is'、'at'、'which'、'on'等。但是对于搜索引擎来说,当所要搜索的短语包含功能词,特别是像'The Who'、'The The'或'Take The'等复合名词时,停用词的使用就会导致问题。另一类词包括词汇词,比如'want'等,这些词应用十分广泛,但是对这样的词搜索引擎无法保证能够给出真正相关的搜索结果,难以帮助缩小搜索范围,同时还会降低搜索的效率,所以通常会把这些词从问题中移去,从而提高搜索性能。
该语料库每行是一篇文章,每篇文章前面是题目,后面是摘要。包含两万多篇文章,仅做测试用。
停用词表和语料库见百度云链接:链接:https://pan.baidu.com/s/1wNNUd0Pe20HFLAyuNcwDrg 密码:367d
- 4、python代码实现
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 31 10:57:03 2018 @author: Lenovo
"""
import jieba
import math
import numpy as np filename = '句子相似度/title.txt'#语料库
filename2 = '句子相似度/stopwords.txt'#停用词表,使用的哈工大停用词表 def stopwordslist():#获取停用词表
stopwords = [line.strip() for line in open(filename2, encoding='UTF-8').readlines()]
return stopwords stop_list = stopwordslist()
def get_dic_input(str):
dic = {} cut = jieba.cut(str)
list_word = (','.join(cut)).split(',') for key in list_word:#去除输入停用词
if key in stop_list:
list_word.remove(key) length_input = len(list_word) for key in list_word:
dic[key] = 0 return dic, length_input def get_tf_idf(filename):
s = input("请输入要检索的关键词句:") dic_input_idf, length_input = get_dic_input(s)
f = open(filename, 'r', encoding='utf-8')
list_tf = []
list_idf = []
word_vector1 = np.zeros(length_input)
word_vector2 = np.zeros(length_input) lines = f.readlines()
length_essay = len(lines)
f.close() for key in dic_input_idf:#计算出每个词的idf值依次存储在list_idf中
for line in lines:
if key in line.split():
dic_input_idf[key] += 1
list_idf.append(math.log(length_essay / (dic_input_idf[key]+1))) for i in range(length_input):#将idf值存储在矩阵向量中
word_vector1[i] = list_idf.pop() for line in lines:#依次计算每个词在每行的tf值依次存储在list_tf中
length = len(line.split())
dic_input_tf, length_input= get_dic_input(s) for key in line.split():
if key in stop_list:#去除文章中停用词
length -= 1
if key in dic_input_tf:
dic_input_tf[key] += 1
for key in dic_input_tf:
tf = dic_input_tf[key] / length
list_tf.append(tf) for i in range(length_input):#将每行tf值存储在矩阵向量中
word_vector2[i] = list_tf.pop() #print(word_vector2)
#print(word_vector1)
tf_idf = float(np.sum(word_vector2 * word_vector1))
if tf_idf > 0.3:#筛选出相似度高的文章
print("tf_idf值:", tf_idf)
print("文章:", line) get_tf_idf(filename)
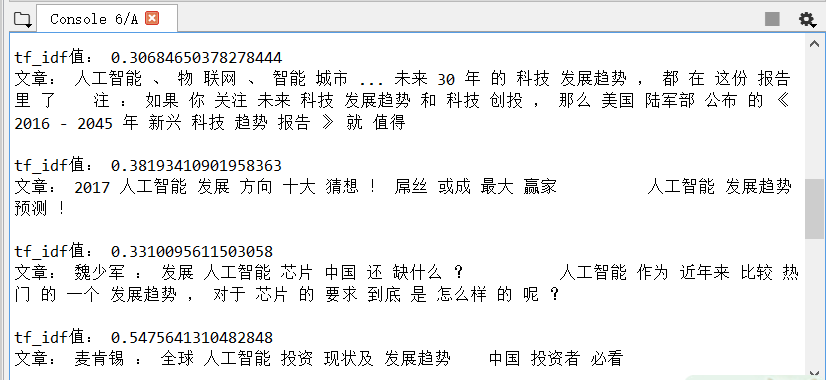
- 5、输出结果
输入:人工智能发展趋势
输出如下:输出tf-idf值大于0.3的,从两万多篇中检索出12篇
TF-IDF算法--关键词句和文本集中每篇文章相关度计算的更多相关文章
- 55.TF/IDF算法
主要知识点: TF/IDF算法介绍 查看es计算_source的过程及各词条的分数 查看一个document是如何被匹配到的 一.算法介绍 relevance score算法,简单来说 ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
随机推荐
- background使用
background-position 有两个参数,定义背景图片起始位置可选值有: center top left right bottom px % background-size 可以用 px % ...
- Android常见错误整理
1.当我new class的时候,提示以下错误: Unable to parse template "Class" Error message: This template did ...
- 常用SQL函数
—————常用SQL函数(实例简述)————— 数据库环境:DB2数据库: 执行工具:Toad for DB2 1.转字符串:to_char() 日期类型:to_char(birthday,'yyy ...
- c++ 枚举与字符串 比较
读取字符串,然后将这个字符转换为对应的枚举. 如:从屏幕上输入'a',则转换为set枚举中对应的a,源代码如下: //关键函数为char2enum(str,temp); #include using ...
- JSP状态管理_1_Cookie
http协议的无状态性:当浏览器发送请求飞服务器时,服务器相应客户端请求:但当同一个浏览器再次发送请求给浏览器时,服务器并不知道它就是刚才那个客户端. 保存用户状态的两大机制:Session,Cook ...
- Apex语言(九)类的方法
1.方法 方法是对象的行为.如下表: 看书,编程,打球就是方法. 2.创建方法 [格式] 访问修饰符 返回值类型 方法名(形式参数列表){ 方法体; } 访问修饰符:可以为类方法指定访问级别. 例如, ...
- 关于Arrays协助类中的排序方法
sort方法是优化的快速排序,不稳定. paralleSort是多线程排序,稳定,但是有长度限制.
- 【转】虚拟化(四):vsphere高可用功能前提-共享存储搭建
vsphere高级功能HA.DRS.FT等,都需要有共享存储环境,即多台esxi主机同时连接一个共享存储,这样在新建虚拟机时,可以指定把虚拟磁盘保存在共享存储上,便于虚拟机在各个主机之间“飘移”. 常 ...
- Java子类对于父类中static方法的继承
今天看到了Java中子类继承父类的一个相关讨论,在网上综合了各家的观点,写下了一篇简短的总结. 问题如下,在父类中含有staic修饰的静态方法,那么子类在继承父类以后可不可以重写父类中的静态方法呢? ...
- 【C#】【分享】 XXX分钟学会C#
原文地址 https://www.cnblogs.com/younShieh/p/10945264.html 前几天在刷即刻的时候发现了一个GitHub上的项目,该项目名为"lear ...