elasticsearch index 之 engine
elasticsearch对于索引中的数据操作如读写get等接口都封装在engine中,同时engine还封装了索引的读写控制,如流量、错误处理等。engine是离lucene最近的一部分。
engine的实现结构如下所示:
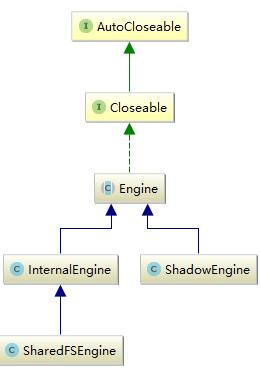
engine接口有三个实现类,主要逻辑都在InternalEngine中。ShadowEngine之实现了engine接口的部分读方法,主要用于对于索引的读操作。shardFSEngine在InternalEngine的基础上实现了recovery方法,它的功能跟InternalEngine基本相同只是它的recovery过程有区别,不会对Translog和index进行快照存储。
Engine类定义了一些index操作的主要方法和内部类,方法如create,index等。内部类如index,delete等。这些方法的实现是在子类中,这些方法的参数是这些内部类。首先看一下它的方法:
public abstract void create(Create create) throws EngineException;
public abstract void index(Index index) throws EngineException;
public abstract void delete(Delete delete) throws EngineException;
public abstract void delete(DeleteByQuery delete) throws EngineException;
这些抽象方法都在子类中实现,它们的参数都是一类,这些都是Engine的内部类,这些内部类类似于实体类,没有相关逻辑只是由很多filed及get方法构成。如Create和Index都继承自IndexOperation,它们所有信息都存储到IndexOperation的相关Field中,IndexOperation如下所示:
public static abstract class IndexingOperation implements Operation {
private final DocumentMapper docMapper;
private final Term uid;
private final ParsedDocument doc;
private long version;
private final VersionType versionType;
private final Origin origin;
private final boolean canHaveDuplicates;
private final long startTime;
private long endTime;
………………
}
无论是Index还是Create,相关数据和配置都在doc中,根据doc和docMapper就能够获取本次操作的所有信息,另外的一些字段如version,uid都是在类初始化时构建。这样传给实际方法的是一个class,在方法内部根据需求获取到相应的数据,如index方法的实现:
private void innerIndex(Index index) throws IOException {
synchronized (dirtyLock(index.uid())) {
final long currentVersion;
VersionValue versionValue = versionMap.getUnderLock(index.uid().bytes());
if (versionValue == null) {
currentVersion = loadCurrentVersionFromIndex(index.uid());
} else {
if (engineConfig.isEnableGcDeletes() && versionValue.delete() && (engineConfig.getThreadPool().estimatedTimeInMillis() - versionValue.time()) > engineConfig.getGcDeletesInMillis()) {
currentVersion = Versions.NOT_FOUND; // deleted, and GC
} else {
currentVersion = versionValue.version();
}
}
long updatedVersion;
long expectedVersion = index.version();
if (index.versionType().isVersionConflictForWrites(currentVersion, expectedVersion)) {
if (index.origin() == Operation.Origin.RECOVERY) {
return;
} else {
throw new VersionConflictEngineException(shardId, index.type(), index.id(), currentVersion, expectedVersion);
}
}
updatedVersion = index.versionType().updateVersion(currentVersion, expectedVersion);
index.updateVersion(updatedVersion);
if (currentVersion == Versions.NOT_FOUND) {
// document does not exists, we can optimize for create
index.created(true);
if (index.docs().size() > 1) {
indexWriter.addDocuments(index.docs(), index.analyzer());
} else {
indexWriter.addDocument(index.docs().get(0), index.analyzer());
}
} else {
if (versionValue != null) {
index.created(versionValue.delete()); // we have a delete which is not GC'ed...
}
if (index.docs().size() > 1) {
indexWriter.updateDocuments(index.uid(), index.docs(), index.analyzer());//获取IndexOperation中doc中字段更新索引
} else {
indexWriter.updateDocument(index.uid(), index.docs().get(0), index.analyzer());
}
}
Translog.Location translogLocation = translog.add(new Translog.Index(index));//写translog
versionMap.putUnderLock(index.uid().bytes(), new VersionValue(updatedVersion, translogLocation));
indexingService.postIndexUnderLock(index);
}
}
这就是Engine中create、index这些方法的实现方式。后面分析索引过程中会有更加详细说明。Engine中还有获取索引状态(元数据)及索引操作的方法如merge。这些方法也是在子类中调用lucene的相关接口,跟create,index,get很类似。因为没有深入Engine的方法实现,因此这里的分析比较简单,后面的分析会涉及这里面很多方法。
总结:这里只是从结构上对indexEngine进行了简单说明,它里面的方法是es对lucene索引操作方法的封装,只是增加了一下处理方面的逻辑如写translog,异常处理等。它的操作对象是shard,es所有对shard的写操作都是通过Engine来实现,后面的分析会有所体现。
elasticsearch index 之 engine的更多相关文章
- ElasticSearch Index操作源码分析
ElasticSearch Index操作源码分析 本文记录ElasticSearch创建索引执行源码流程.从执行流程角度看一下创建索引会涉及到哪些服务(比如AllocationService.Mas ...
- elasticsearch index 之 put mapping
elasticsearch index 之 put mapping mapping机制使得elasticsearch索引数据变的更加灵活,近乎于no schema.mapping可以在建立索引时设 ...
- elasticsearch index 功能源码概述
从本篇开始,对elasticsearch的介绍将进入数据功能部分(index),这一部分包括索引的创建,管理,数据索引及搜索等相关功能.对于这一部分的介绍,首先对各个功能模块的分析,然后详细分析数据索 ...
- Add mappings to an Elasticsearch index in realtime
Changing mapping on existing index is not an easy task. You may find the reason and possible solutio ...
- ElasticSearch Index API && Mapping
ElasticSearch NEST Client 操作Index var indexName="twitter"; var deleteIndexResponse = clie ...
- Elasticsearch Index模块
1. Index Setting(索引设置) 每个索引都可以设置索引级别.可选值有: static :只能在索引创建的时候,或者在一个关闭的索引上设置 dynamic:可以动态设置 1.1. S ...
- Elasticsearch index fields 重命名
reindex数据复制,重索引 POST _reindex { "source": { "index": "twitter" }, &quo ...
- elasticsearch index tuning
一.扩容 tag_server当前使用ElasticSearch版本为5.6,此版本单个index的分片是固定的,一旦创建后不能更改. 1.扩容方法1,不适 ES6.1支持split index功能, ...
- elasticsearch index 之 create index(-)
从本篇开始,就进入了Index的核心代码部分.这里首先分析一下索引的创建过程.elasticsearch中的索引是多个分片的集合,它只是逻辑上的索引,并不具备实际的索引功能,所有对数据的操作最终还是由 ...
随机推荐
- Java类和对象8
按要求编写Java应用程序. (1)创建一个叫做People的类: 属性:姓名.年龄.性别.身高 行为:说话.计算加法.改名 编写能为所有属性赋值的构造方法: (2)创建主类: 创建一 ...
- PostgreSQL Replication之第八章 与pgbouncer一起工作(2)
8.2 安装pgbouncer 在我们深入细节之前,我们将看看如何安装pgbouncer.正如PostgreSQL一样,您可以采取两种途径.您可以安装二进制包或者直接从源代码编译.在我们的例子中,我们 ...
- UVa 12661 Funny Car Racing【 dijkstra 】
题意:给出n个点,m条路,每条路用5个整数表示u,v,a,b,t u表示这条路的起点,v表示终点,a表示打开时间,b表示关闭时间,t表示通过这条道路需要的时间 看的紫书,因为边权不再仅仅是路上的时间, ...
- 初学者指南:ZFS 是什么,为什么要使用 ZFS?
作者: John Paul 译者: LCTT Lv Feng 今天,我们来谈论一下 ZFS,一个先进的文件系统.我们将讨论 ZFS 从何而来,它是什么,以及为什么它在科技界和企业界如此受欢迎. 虽然我 ...
- 洛谷 P1368 工艺 后缀自动机 求最小表示
后缀自动机沙茶题 将字符串复制一次,建立后缀自动机. 在后缀自动机上贪心走 $n$ 次即可. Code: #include <cstdio> #include <algorithm& ...
- Test-我喜欢LInux
测试发帖流程 哈哈 习惯一下先.
- 简单的 centos7&rhel7 系统初始化脚本
#!/bin/bash #描述: 基于RHEL7¢os7的初始化配置 #读取用户输入的ip read -p "输入你当前Linux的IP地址:" LAST #截取网 ...
- Eclipse快捷键 10个最实用的快捷键
Eclipse中10个最实用的快捷键组合 一个Eclipse骨灰级开发人员总结了他觉得最实用但又不太为人所知的快捷键组合.通过这些组合能够更加easy的浏览源代码.使得总体的开发效率和质量得到提升. ...
- vue.2.0-自定义全局组件
App.vue <template> <div id="app"> <h3>welcome vue-loading</h3> < ...
- POJ 1191 记忆化搜索
(我是不会告诉你我是抄的http://www.cnblogs.com/scau20110726/archive/2013/02/27/2936050.html这个人的) 一开始没有想到要化一下方差的式 ...