elasticsearch bucket 之rare terms聚合
1、背景
我们知道当我们使用 terms聚合时,当修改默认顺序为_count asc时,统计的结果是不准备的,而且官方也不推荐我们这样做,而是推荐使用rare terms聚合。rare terms是一个稀少的term聚合,可以一定程度的解决升序问题。
2、需求
统计province字段中包含上和湖的term数据,并且最多只能出现2次。获取到聚合后的结果。
3、前置准备
3.1 准备mapping
PUT /index_person
{
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "keyword"
},
"province": {
"type": "keyword"
},
"sex": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"pipeline_province_sex":{
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
3.2 准备数据
PUT /_bulk
{"create":{"_index":"index_person","_id":1}}
{"id":1,"name":"张三","sex":"男","age":20,"province":"湖北","address":"湖北省黄冈市罗田县匡河镇"}
{"create":{"_index":"index_person","_id":2}}
{"id":2,"name":"李四","sex":"男","age":19,"province":"江苏","address":"江苏省南京市"}
{"create":{"_index":"index_person","_id":3}}
{"id":3,"name":"王武","sex":"女","age":25,"province":"湖北","address":"湖北省武汉市江汉区"}
{"create":{"_index":"index_person","_id":4}}
{"id":4,"name":"赵六","sex":"女","age":30,"province":"北京","address":"北京市东城区"}
{"create":{"_index":"index_person","_id":5}}
{"id":5,"name":"钱七","sex":"女","age":16,"province":"北京","address":"北京市西城区"}
{"create":{"_index":"index_person","_id":6}}
{"id":6,"name":"王八","sex":"女","age":45,"province":"北京","address":"北京市朝阳区"}
{"create":{"_index":"index_person","_id":7}}
{"id":7,"name":"九哥","sex":"男","age":25,"province":"上海市","address":"上海市嘉定区"}
4、实现需求
4.1 dsl
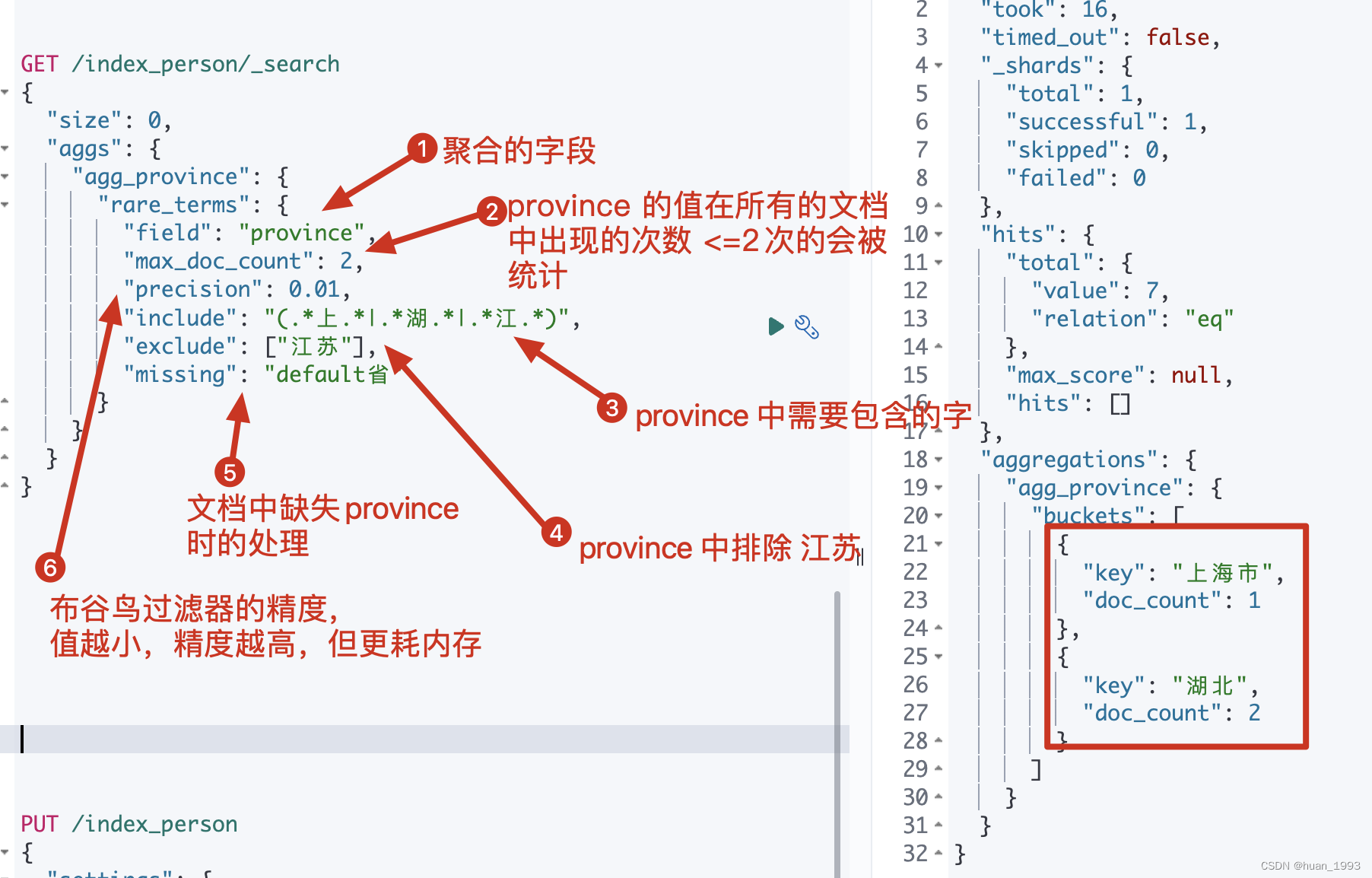
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_province": {
"rare_terms": {
"field": "province",
"max_doc_count": 2,
"precision": 0.01,
"include": "(.*上.*|.*湖.*|.*江.*)",
"exclude": ["江苏"],
"missing": "default省"
}
}
}
}
4.2 java代码
@Test
@DisplayName("稀少的term聚合,类似按照 _count asc 排序的terms聚合,但是terms聚合中按照_count asc的结果是不准的,需要使用 rare terms 聚合")
public void agg01() throws IOException {
SearchRequest searchRequest = new SearchRequest.Builder()
.size(0)
.index("index_person")
.aggregations("agg_province", agg ->
agg.rareTerms(rare ->
// 稀有词 的字段
rare.field("province")
// 该稀有词最多可以出现在几个文档中,最大值为100,如果要调整,需要修改search.max_buckets参数的值(尝试修改这个值,不生效)
// 在该例子中,只要是出现的次数<=2的聚合都会返回
.maxDocCount(2L)
// 内部布谷鸟过滤器的精度,精度越小越准,但是相应的消耗内存也越多,最小值为 0.00001,默认值为 0.01
.precision(0.01)
// 应该包含在聚合的term, 当是单个字段是,可以写正则表达式
.include(include -> include.regexp("(.*上.*|.*湖.*|.*江.*)"))
// 排出在聚合中的term,当是集合时,需要写准确的值
.exclude(exclude -> exclude.terms(Collections.singletonList("江苏")))
// 当文档中缺失province字段时,给默认值
.missing("default省")
)
)
.build();
System.out.println(searchRequest);
SearchResponse<Object> response = client.search(searchRequest, Object.class);
System.out.println(response);
}
一些注意事项都在注释中。
4.3 运行结果
5、max_doc_count 和 search.max_buckets

6、注意事项
rare terms统计返回的数据没有大小限制,而且受max_doc_count参数的限制,比如:如果复合 max_doc_count 的分组有60个,那么这60个分组会直接返回。max_doc_count的值最大为100,貌似不能修改。- 如果一台节点聚合收集的结果过多,那么很容易超过
search.max_buckets的值,此时就需要修改这个值。
# 临时修改
PUT /_cluster/settings
{"transient": {"search.max_buckets": 65536}}
# 永久修改
PUT /_cluster/settings
{"persistent": {"search.max_buckets": 65536}}
7、完整代码
8、参考文档
elasticsearch bucket 之rare terms聚合的更多相关文章
- elasticsearch聚合之bucket terms聚合
目录 1. 背景 2. 前置条件 2.1 创建索引 2.2 准备数据 3. 各种聚合 3.1 统计人数最多的2个省 3.1.1 dsl 3.1.2 运行结果 3.2 统计人数最少的2个省 3.2.1 ...
- ES Terms 聚合数据不确定性
Elasticsearch是一个分布式的搜索引擎,每个索引都可以有多个分片,用来将一份大索引的数据切分成多个小的物理索引,解决单个索引数据量过大导致的性能问题,另外每个shard还可以配置多个副本,来 ...
- 把 Elasticsearch 当数据库使:聚合后排序
使用 https://github.com/taowen/es-monitor 可以用 SQL 进行 elasticsearch 的查询.有的时候分桶聚合之后会产生很多的桶,我们只对其中部分的桶关心. ...
- Elasticsearch 第六篇:聚合统计查询
h2.post_title { background-color: rgba(43, 102, 149, 1); color: rgba(255, 255, 255, 1); font-size: 1 ...
- ElasticSearch搜索term和terms的区别
今天同事使用ES查询印地语的文章.发现查询报错,查询语句和错误信息如下: 查询语句:{ "query":{ "bool":{ ...
- Elasticsearch学习系列四(聚合搜索)
聚合分析 聚合分析是数据库中重要的功能特性,完成对一个查询的集中数据的聚合计算.如:最大值.最小值.求和.平均值等等.对一个数据集求和,算最大最小值等等,在ES中称为指标聚合,而对数据做类似关系型数据 ...
- Elasticsearch(9) --- 聚合查询(Bucket聚合)
Elasticsearch(9) --- 聚合查询(Bucket聚合) 上一篇讲了Elasticsearch聚合查询中的Metric聚合:Elasticsearch(8) --- 聚合查询(Metri ...
- Elasticsearch聚合 之 Terms
之前总结过metric聚合的内容,本篇来说一下bucket聚合的知识.Bucket可以理解为一个桶,他会遍历文档中的内容,凡是符合要求的就放入按照要求创建的桶中. 本篇着重讲解的terms聚合,它是按 ...
- elasticsearch聚合操作——本质就是针对搜索后的结果使用桶bucket(允许嵌套)进行group by,统计下分组结果,包括min/max/avg
分析 Elasticsearch有一个功能叫做聚合(aggregations),它允许你在数据上生成复杂的分析统计.它很像SQL中的GROUP BY但是功能更强大. 举个例子,让我们找到所有职员中最大 ...
- ElasticSearch 的 聚合(Aggregations)
Elasticsearch有一个功能叫做 聚合(aggregations) ,它允许你在数据上生成复杂的分析统计.它很像SQL中的 GROUP BY 但是功能更强大. Aggregations种类分为 ...
随机推荐
- 利用C库函数time()打印当前系统动态时间
引入日期和时间头文件 #include<time.h> 用time_t定义一个存储时间的变量获取时间(以秒为单位) time_t t; time (&t); //获取1970年以来 ...
- 【设计模式】Java设计模式 - 外观模式
Java设计模式 - 外观模式 不断学习才是王道 继续踏上学习之路,学之分享笔记 总有一天我也能像各位大佬一样 原创作品,更多关注我CSDN: 一个有梦有戏的人 准备将博客园.CSDN一起记录分享自己 ...
- Django 之视图层
JsonResponse 1 json格式的数据有什么用 前后端数据交互需要使用json作为过渡,实现跨语言传输数据 2 前后端方法对应 JSON.stringify() - json.dumps( ...
- CPU密集型和IO密集型(判断最大核心线程的最大线程数)
CPU密集型和IO密集型(判断最大核心线程的最大线程数) CPU密集型 1.CPU密集型获取电脑CPU的最大核数,几核,最大线程数就是几Runtime.getRuntime().availablePr ...
- 不要舔 Switch 游戏卡,单性生殖,永久夏令时
文章转载自:https://mp.weixin.qq.com/s/8EikwCvZgKt2TFsld-nKSA
- 分布式文件存储 CephFS的应用场景
块存储 (适合单客户端使用) 典型设备:磁盘阵列,硬盘. 使用场景: a. docker容器.虚拟机远程挂载磁盘存储分配. b. 日志存储. 文件存储 (适合多客户端有目录结构) 典型设备:FTP.N ...
- Elasticsearch实现类Google高级检索
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247483914&idx=1&sn=436f814 ...
- 报错 Invalid options in vue.config.js: "baseUrl" is not allowed 问题解决
报错 Invalid options in vue.config.js: "baseUrl" is not allowed vue3.0版本中 执行 npm run build会出 ...
- 20220929-ArrayList扩容机制源码分析
示例代码 public class ArrayListSource { public static void main(String[] args) { ArrayList arrayList = n ...
- webpack打包思路与流程解析
一:创建一个新的工程,项目初始化 npm init -y 二:搭建项目框架 三:编写main.js文件内容,在index.js中引入,在把index.js引入到index.html中 例: expor ...