CRUSE: Convolutional Recurrent U-net for Speech Enhancement
CRUSE: Convolutional Recurrent U-net for Speech Enhancement
本文是关于TOWARDS EFFICIENT MODELS FOR REAL-TIME DEEP NOISE SUPPRESSION的介绍,作者是Microsoft Research的Sebastian Braun等。相关工作的上下文可以参看博文
概述
本文设计的是基于深度学习的语音增强模型,工作的贡献点有二:
- 基于深度学习语音增强模型在实录数据的性能
- 一套用于语音增强的数据增强方法
- 模型计算复杂度和语音质量(主要是MOS)的折衷的消融实验结果
动机
- 本文要解决的核心问题是:目前语音增强模型普遍为了获得更好的性能,不断增加模型的计算量。而更需要关心的问题是:如何在给定最大计算量要求下设计出最有效的模型(How to obtain the best speech quality given a maximum computational budget?),因为这在边缘设备(edge devices)和低功耗设备上是重要的
系统与模型
系统框图如下
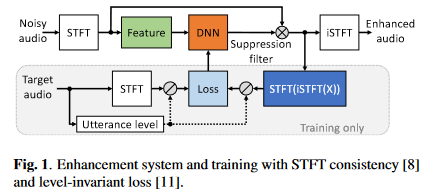
要说明如下几点:
- 选择频域模型的原因:时域模型在带混响数据和实录数据上的泛化性能没有被验证
- 特征采用的是对数功率谱,网络估计目标是IRM,损失则是利用SA方法
- IRM作用在带噪STFT谱后(这里为避免混淆,将其称为重构谱)进行STFT一致性约束,即先将谱iSTFT后再STFT(将STFT后的谱成为约束谱),之后对约束谱进行信号量级归一化后计算压缩复谱的MSE损失,这里直接给出合并了信号量级归一化和压缩复谱MSE损失的公式,所以比论文中的损失公式多了一个归一化因子项:\(\mathcal{L}=\frac{1}{\sigma_S^{c}}(\lambda\sum_{k,n}{|S^c-\widehat{S}^c|^2+(1-\lambda)(\sum_{k,n}{||S|^c-|\widehat{S}|^c|^2})})\),其中\(\sigma_S\)是纯净语音有声段的能量,压缩谱的操作定义为\(X_{cprs}=\frac{X(k,n)}{|X(k,n)|}|X(k,n)|^{c}\),\(c\)和\(\lambda\)作者推荐都为0.3。
- 验证阶段按\(Q=PESQ+0.2SI-SDR-CD\)选择最优的模型,其中PESQ,SI-SDR和倒谱距离分别是三个语音质量评估指标
- 训练的batch size=10,句子长度10 s,AdamW优化器,学习率(learning rate)为8e-5,权重衰减(weight decay)为0.1
模型CRUSE架构如下图,整体上沿用了谭可的GCRN:
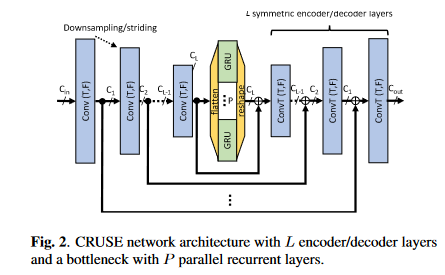
- 主要组成部分有三部分:编码器、解码器、时序建模。其中编解码器是一个U-Net结构,即\(L\)层卷积编码层和\(L\)层卷积解码层。卷积编码层就是卷积层+BN+leakyReLU,解码层就是转置卷积+BN+leakyReLU,不过最后一个解码层的激活函数为sigmoid以保证输出为IRM。卷积或转置卷积层的kernel size是\(2 \times 3\),stride是\(1 \times 2\) (均为时间帧维×频点维),即时间维上通过编码器补零和解码器截断完成因果卷积,频率维则每层尺度减半。时序建模采用的是分组GRU,因为GRU比LSTM计算复杂度更低,分组策略则与GCRN中的分组LSTM一致。编解码器对应层之间用跳转连接联系,这里的跳转连接使用\(1\times1\)卷积和加法连接实现的,从而降低GCRN中拼接连接带来解码层巨大的输入维度导致的过高的计算量,加法拼接如下图
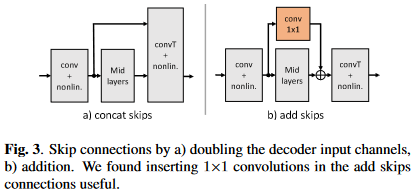
算法参数
16 kHz的采样率,20 ms帧长,10 ms帧移以及320点FFT。输入特征是\(Batch_size \times 1 \times num_frames \times num_bins\),卷积层通道数从16开始,依次加倍,直到倒数第二层,最后一层输出通道数则为\(C_L\),比如\(L=4\)层且\(C_L=120\),则卷积层的输出通道数依次为\(16-32-64-120\),转置卷积层的输出通道数依次为\(64-32-16-1\),最后一层始终为1以保证输出是幅度掩蔽。分组GRU的层数为\(N\)分组数为\(P\)。网络命名规则为\(CRUSEL-C_L-N \times RNNP\)
数据集的增广
数据集的增广方法可以参考博文
评估指标是用于评价语音质量的DNSMOS(P.808)和用于评估计算量的MACs,需要注意的是这里的DNSMOS(P.808)应该是与目前(2022/04/24)可用的DNSMOS(P.808&P.835)中的P.808的分数有差异了
实验结果
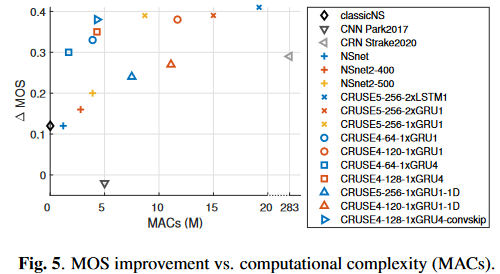
(图中横轴是MACs,纵轴是\(\Delta\)MOS,因此在图中偏左上的方法更优)
分析结论:
- CRUSE5中的2层LSTM换成2层GRU甚至1层GRU会在性能下降极小的情况下大幅度降低计算复杂度
- GRU分组后性能少量下降但是会带来计算复杂度下降
- 编解码器卷积层中的kernel时间维从2降到1(图中的\(*-1D\)模型),性能下降严重,推测是混响的原因,因为GCRN在降噪任务上评估时没有明显的性能下降
- 编解码器尤其是时间维度进行卷积对性能提升帮助很大
- MOS和MACs大体呈线性相关的趋势
- 使用分组为4的GRU并结合add conv\(1 \times 1\) skip的CRUSE4是本文的最佳折衷方案
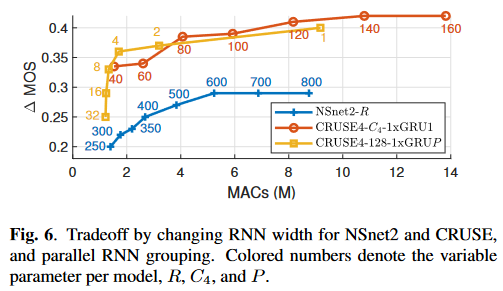
RNN的宽度引起的MOS和MACs的关系可以指导我们在给定的计算资源下设计最优的模型
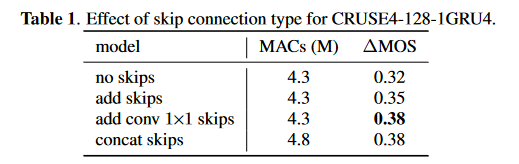
最后是一个消融实验证明设计的跳转连接的有效性
CRUSE: Convolutional Recurrent U-net for Speech Enhancement的更多相关文章
- 论文翻译:2020_DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement
论文地址:DCCRN:用于相位感知语音增强的深度复杂卷积循环网络 论文代码:https://paperswithcode.com/paper/dccrn-deep-complex-convolutio ...
- 论文翻译:2019_TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain
论文地址:TCNN:时域卷积神经网络用于实时语音增强 论文代码:https://github.com/LXP-Never/TCNN(非官方复现) 引用格式:Pandey A, Wang D L. TC ...
- 论文翻译:2020_WaveCRN: An efficient convolutional recurrent neural network for end-to-end speech enhancement
论文地址:用于端到端语音增强的卷积递归神经网络 论文代码:https://github.com/aleXiehta/WaveCRN 引用格式:Hsieh T A, Wang H M, Lu X, et ...
- 论文翻译:2020_Densely connected neural network with dilated convolutions for real-time speech enhancement in the time domain
提出了模型和损失函数 论文名称:扩展卷积密集连接神经网络用于时域实时语音增强 论文代码:https://github.com/ashutosh620/DDAEC 引用:Pandey A, Wang D ...
- 论文翻译:2021_DeepFilterNet: A Low Complexity Speech Enhancement Framework for Full-Band Audio based on Deep Filtering
论文地址:DeepFilterNet:基于深度滤波的全频带音频低复杂度语音增强框架 论文代码:https://github.com/ Rikorose/DeepFilterNet 引用:Schröte ...
- 论文翻译:2022_PACDNN: A phase-aware composite deep neural network for speech enhancement
论文地址:PACDNN:一种用于语音增强的相位感知复合深度神经网络 引用格式:Hasannezhad M,Yu H,Zhu W P,et al. PACDNN: A phase-aware compo ...
- 论文翻译:2021_Towards model compression for deep learning based speech enhancement
论文地址:面向基于深度学习的语音增强模型压缩 论文代码:没开源,鼓励大家去向作者要呀,作者是中国人,在语音增强领域 深耕多年 引用格式:Tan K, Wang D L. Towards model c ...
- 论文翻译:2020_FLGCNN: A novel fully convolutional neural network for end-to-end monaural speech enhancement with utterance-based objective functions
论文地址:FLGCNN:一种新颖的全卷积神经网络,用于基于话语的目标函数的端到端单耳语音增强 论文代码:https://github.com/LXP-Never/FLGCCRN(非官方复现) 引用格式 ...
- 论文翻译:Fullsubnet: A Full-Band And Sub-Band Fusion Model For Real-Time Single-Channel Speech Enhancement
论文作者:Xiang Hao, Xiangdong Su, Radu Horaud, and Xiaofei Li 翻译作者:凌逆战 论文地址:Fullsubnet:实时单通道语音增强的全频带和子频带 ...
随机推荐
- JVM中的常量池
在Java的内存分配中,总共3种常量池: ref:https://blog.csdn.net/zm13007310400/article/details/77534349 1.字符串常量池(Strin ...
- Oracle入门基础(十)一一数据库其他对象-视图/序列/索引/同义词
SQL> --视图 SQL> create view empinfoview as select e.empno,e.ename,e.sal,e.sal*12 annsal,d.dname ...
- Java中如何强制类型转换
例如,当程序中需要将 double 型变量的值赋给一个 int 型变量,该如何实现呢? 显然,这种转换是不会自动进行的!因为 int 型的存储范围比 double 型的小.此时就需要通过强制类型转换来 ...
- MySQL 中 InnoDB 支持的四种事务隔离级别名称,以及逐 级之间的区别?
SQL 标准定义的四个隔离级别为: 1.read uncommited :读到未提交数据 2.read committed:脏读,不可重复读 3.repeatable read:可重读 4.seria ...
- 学习 MongoDB(一)
1.介绍 MongoDB是C++语言编写,是一个基于分布式文件存储的开源数据库系统,MongoDB将数据存储为一个文档, 数据结构由键值对(key=>value)组成,MongoDB文档类似于 ...
- 学习DNS(二)
DNS出现及演化 网络出现的早期 是使用IP地址通讯的,那时就几台主机通讯.但是随着接入网络主机的增多,这种数字标识的地址非常不便于记忆,UNIX上就出现了建立一个叫做hosts的文件(Linux和w ...
- 学习zabbix(八)
一,Zabbix架构 zabbix 是一个基于 WEB 界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案.zabbix 能监视各种网络参数,保证服务器系统的安全运营:并提供灵活的通知机制 ...
- mybatis-01-基本流程
mybatis执行流程 1. 加载配置文件并初始化(SqlSession) 配置文件来源于两个地方,一个是配置文件(主配置文件conf.xml,mapper文件*.xml), 一个是java代码中 ...
- IE中的编码位置
进入设置 找到Editor 找到File Encodings
- Lambda8 表达式
Lambda 表达式 Lambda 表达式是 JDK8 的一个新特性,可以取代大部分的匿名内部类,写出更优雅的 Java 代码,尤其在集合的遍历和其他集合操作中,可以极大地优化代码结构. JDK 也提 ...