论文解读(GLA)《Label-invariant Augmentation for Semi-Supervised Graph Classification》
论文信息
论文标题:Label-invariant Augmentation for Semi-Supervised Graph Classification
论文作者:Han Yue, Chunhui Zhang, Chuxu Zhang, Hongfu Liu
论文来源:2022,NeurIPS
论文地址:download
论文代码:download
1 Introduction
我们提出了一种图对比学习的标签不变增强策略,该策略涉及到下游任务中的标签来指导对比增强。值得注意的是,我们不生成任何图形数据。相反,我们在训练阶段直接生成标签一致的表示作为增广图。
2 Methodology
2.1 Motivation
数据增强在神经网络训练中起着重要的作用。它不仅提高了学习表示的鲁棒性,而且为训练提供了丰富的数据。
例子:(使用 $50%$ 的标签做监督信息。数据增强:node dropping, edge perturbation, attribute masking, subgraph sampling)
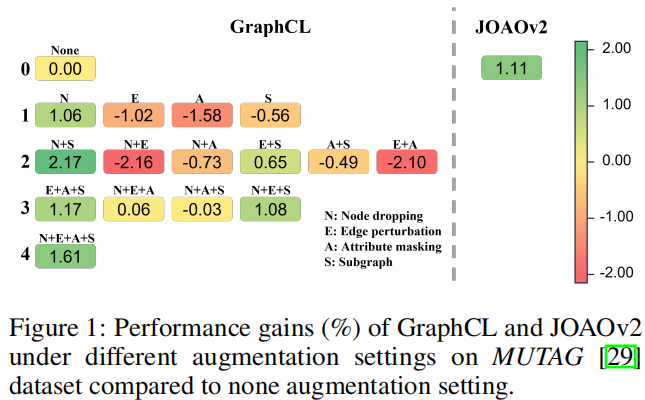
显然有些数据增强策略(或组合)对于模型训练又负面影响。本文进一步使用 MUTAG 中的 $100%$ 标签训练模型,然后以每种数据增强抽样概率 $0.2$ 选择数据增强图,发现 80% 的数据增强图和原始图标签一致,约 $20%$ 的数据增强图和原始图标签不一致。
2.2 Label-invariant Augmentation
整体框架:
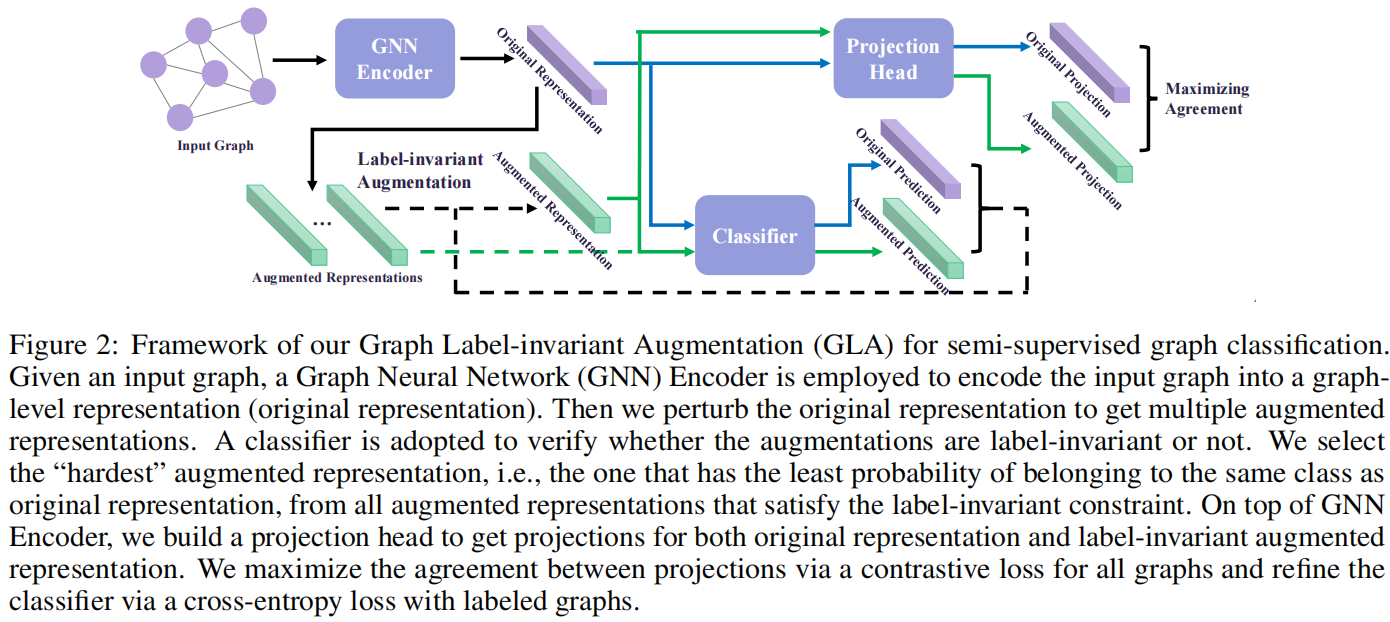
四个组成部分:
- Graph Neural Network Encoder
- Classifier
- Label-invariant Augmentation
- Projection Head
出发点:对于一个有标记的图,我们期望由增强表示预测的标签与地面真实标签相同。
2.2.1 Graph Neural Network Encoder
GCN layer :
其中:
- $G^{(l)}$ denotes the matrix in the l -th layer, and $G^{(0)}=X$
- $\sigma(\cdot)=\operatorname{ReLU}(\cdot)$
池化 (sum):
$H=\operatorname{Pooling}(G)\quad\quad\quad\quad(2)$
2.2.2 Classifier
基于图级表示,我们使用带有参数 $\theta_{C}$ 的全连接层进行预测:
$C^{(l+1)}=\operatorname{Softmax}\left(\sigma\left(C^{(l)} \cdot \theta_{C}^{(l)}\right)\right)\quad\quad\quad\quad(3)$
其中,$C^{(l)}$ 表示第 $l$ 层的嵌入,输入层 $C^{(0)}=H^{O}$ 或 $C^{(0)}=H^{A}$ 分别表示原始表示和增强图表示。实验中,采用了一个 2 层多层感知器,得到了对原始表示 $H^{O}$ 和增强表示 $H^{A}$ 的预测 $C^{O}$ 和 $C^{A}$。
2.2.3 Label-invariant Augmentation
不对图级表示做数据增强,而是在原始图级表示$H^{O}$上做微小扰动得到增强图级表示。
在实验中,首先计算所有图的原始表示的质心,得到每个原始表示与质心之间的欧氏距离的平均值为 $d$,即:
$d=\frac{1}{N} \sum_{i=1}^{N}\left\|H_{i}^{O}-\frac{1}{N} \sum_{j=1}^{N} H_{j}^{O}\right\|\quad\quad\quad\quad(4)$
然后计算增强图表示 $H^{A}$:
$H^{A}=H^{O}+\eta d \Delta\quad\quad\quad\quad(5)$
其中 $\eta$ 缩放扰动的大小,$\Delta$ 是一个随机单位向量。
为实现标签不变增强,每次,随机生成多个扰动,并选择符合标签不变属性的合格候选增强。在这些合格的候选对象中,选择了最困难的一个,即最接近分类器的决策边界的一个,以提高模型的泛化能力。
2.2.4 Projection Head
使用带有参数 $\theta_{P}$ 的全连接层,从图级表示中得到对比学习的投影,如下所示:
$P^{(l+1)}=\sigma\left(P^{(l)} \cdot \theta_{P}^{(l)}\right) \quad\quad\quad\quad(6)$
采用一个 2 层多层感知器,从原始表示 $H^{O}$ 和增广表示 $H^{A}$ 中得到投影 $P^{O}$ 和 $P^{A}$。
2.2.5 Objective Function
目标函数包括对比损失和分类损失。对比损失采用 NT-Xent,但只保留正对部分如下:
$\mathcal{L}_{P}=\frac{-\left(P^{O}\right)^{\top} P^{A}}{\left\|P^{O}\right\|\left\|P^{A}\right\|} \quad\quad\quad\quad(7)$
对于分类损失,采用交叉熵,其定义为:
$\mathcal{L}_{C}=-\sum_{i=1}^{c}\left(Y_{i}^{O} \log P_{i}^{O}+Y_{i}^{O} \log P_{i}^{A}\right) \quad\quad\quad\quad(8)$
其中,$Y^{O}$ 是输入图的标签,$c$ 是图类别的数量。本文只计算带标签的图的 $\mathcal{L}_{C}$。$\text{Classifier}$ 的改进将有助于标签不变的增强,反过来有利于分类器的训练。
结合等式 $\text{Eq.7}$ 和 $\text{Eq.8}$ ,总体目标函数可以写成如下:
$\underset{\Theta}{\text{min}} \quad\mathcal{L}_{P}+\alpha \mathcal{L}_{C}\quad\quad\quad\quad(9)$
3 Experiments
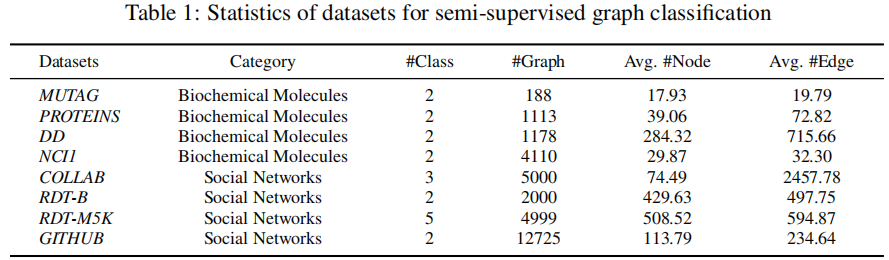
3.2 Semi-supervised graph classification results
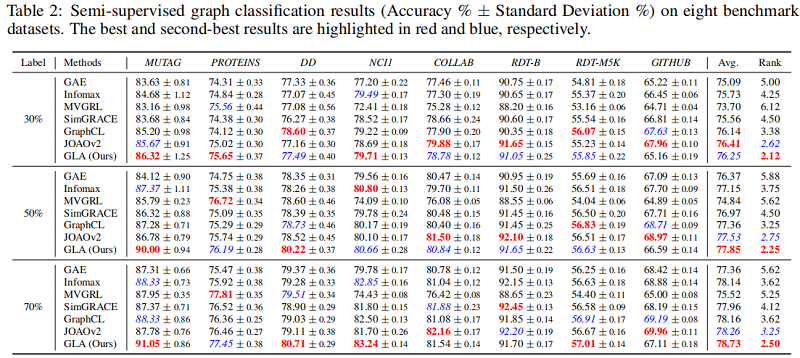
3.3 Algorithmic Performance
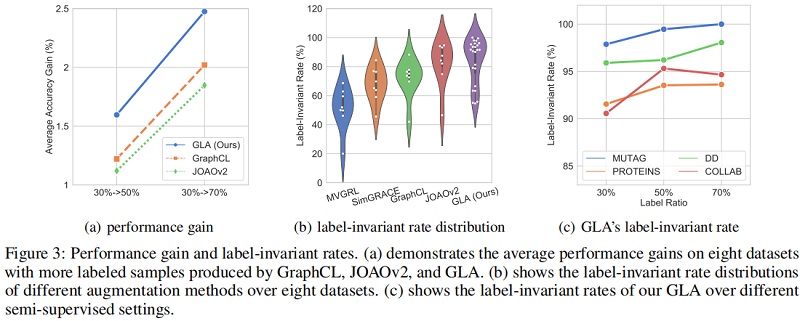
3.4 In-depth Exploration
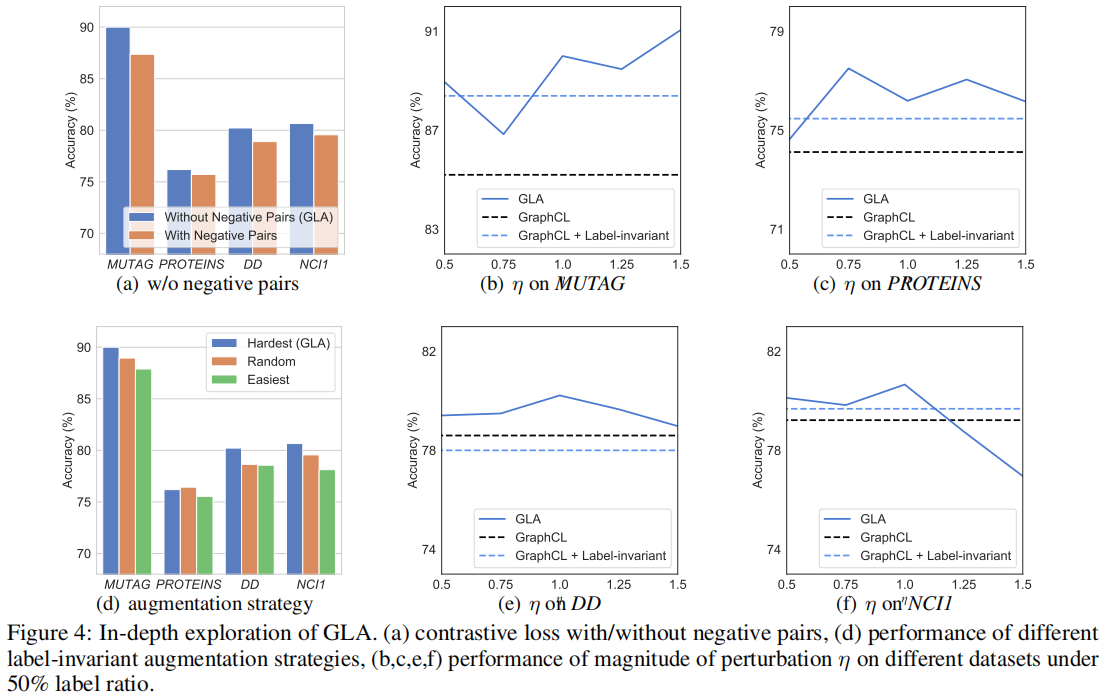
现有的图对比学习方法将来自不同源样本的增广图视为负对,并对这些负对采用实例级判别。由于这些方法分离了 pre-train 阶段和 fine-tuning 阶段,因此负对包含了来自不同源样本的增强样本,但在下游任务中具有相同的类别。
Figure 4(a) 显示了我们在四个数据集上有负对和没有负对的 GLA 的性能。可以看到,与没有负对的默认设置相比,有负对的性能显著下降,而负对在所有四个数据集上都表现一致。与现有的图对比方法不同,GLA 集成了预训练阶段和微调阶段,其中以自监督的方式设计的负对不利于下游任务。这一发现也与最近的[10,9]在视觉对比学习领域的研究结果相一致。
4 Conclusion
本文研究了图的对比学习问题。从现有的方法和训练前的方法不同,我们提出了一种新的图标签不变增强(GLA)算法,该算法集成了训练前和微调阶段,通过扰动在表示空间中进行标签不变增强。具体来说,GLA首先检查增广表示是否服从标签不变属性,并从合格的样本中选择最困难的样本。通过这种方法,GLA在不生成任何原始图的情况下实现了对比增强,也增加了模型的泛化。在8个基准图数据集上的半监督设置下的广泛实验证明了我们的GLA的有效性。此外,我们还提供了额外的实验来验证我们的动机,并深入探讨了GLA在负对、增强空间和策略效应中的影响因素。
论文解读(GLA)《Label-invariant Augmentation for Semi-Supervised Graph Classification》的更多相关文章
- 论文解读(GraphDA)《Data Augmentation for Deep Graph Learning: A Survey》
论文信息 论文标题:Data Augmentation for Deep Graph Learning: A Survey论文作者:Kaize Ding, Zhe Xu, Hanghang Tong, ...
- 论文解读(GIN)《How Powerful are Graph Neural Networks》
Paper Information Title:<How Powerful are Graph Neural Networks?>Authors:Keyulu Xu, Weihua Hu, ...
- 论文解读(GraphMAE)《GraphMAE: Self-Supervised Masked Graph Autoencoders》
论文信息 论文标题:GraphMAE: Self-Supervised Masked Graph Autoencoders论文作者:Zhenyu Hou, Xiao Liu, Yukuo Cen, Y ...
- 论文解读(SEP)《Structural Entropy Guided Graph Hierarchical Pooling》
论文信息 论文标题:Structural Entropy Guided Graph Hierarchical Pooling论文作者:Junran Wu, Xueyuan Chen, Ke Xu, S ...
- 论文解读(SUBLIME)《Towards Unsupervised Deep Graph Structure Learning》
论文信息 论文标题:Towards Unsupervised Deep Graph Structure Learning论文作者:Yixin Liu, Yu Zheng, Daokun Zhang, ...
- 论文解读(GSAT)《Interpretable and Generalizable Graph Learning via Stochastic Attention Mechanism》
论文信息 论文标题:Interpretable and Generalizable Graph Learning via Stochastic Attention Mechanism论文作者:Siqi ...
- 论文解读(GMT)《Accurate Learning of Graph Representations with Graph Multiset Pooling》
论文信息 论文标题:Accurate Learning of Graph Representations with Graph Multiset Pooling论文作者:Jinheon Baek, M ...
- 论文解读(ClusterSCL)《ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs》
论文信息 论文标题:ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs论文作者:Yanling Wang, Jing ...
- 论文解读(PPNP)《Predict then Propagate: Graph Neural Networks meet Personalized PageRank》
论文信息 论文标题:Predict then Propagate: Graph Neural Networks meet Personalized PageRank论文作者:Johannes Gast ...
- 论文解读(DropEdge)《DropEdge: Towards Deep Graph Convolutional Networks on Node Classification》
论文信息 论文标题:DropEdge: Towards Deep Graph Convolutional Networks on Node Classification论文作者:Yu Rong, We ...
随机推荐
- 【转载】一封面向社会,关于对近日来 CCF 不当行为之抗议的公开信
原文链接:https://101001011.github.io/2022/06/11/zhi-ccf-de-yi-feng-gong-kai-xin/ 原文作者:CCA(CCA's Blog) 前天 ...
- 新版 Ubuntu 中 gnome-terminal 可恶的行间距问题逼我退回了 Ubuntu 20.04
不知道从什么时候起(可能是 Ubuntu 21.04,也可能是 Ubuntu 21.10),Ubuntu 中的 gnome-terminal 的行间距就加大了,看起来极其不爽,特别是和 Powerli ...
- Postman如何做接口测试,那些不得不知道的技巧
Postman如何做接口测试1:如何导入 swagger 接口文档 在使用 postman 做接口测试过程中,测试工程师会往界面中填入非常多的参数,包括 url 地址,请求方法,消息头和消息体等一系列 ...
- Python小游戏——外星人入侵(保姆级教程)第一章 07调整飞船速度 08限制飞船活动范围
系列文章目录 第一章:武装飞船 07调整飞船速度 08限制飞船活动范围 一.代码及演示 1.修改settings 修改文件:settings.py 点击查看代码 #渗透小红帽python的学习之路 # ...
- IDEA:库源与类的字节码不匹配
在我配置pom.xml文件后,进行代码编辑,发现引入的方法并不是想要的内容,然后我就进入下载源码后进入到源码中发现我想要的方法和导入的jar包内的源码方法并不相同 ,于是到jar的存放地址中将其他版本 ...
- AI 音辨世界:艺术小白的我,靠这个AI模型,速识音乐流派选择音乐 ⛵
作者:韩信子@ShowMeAI 数据分析实战系列:https://www.showmeai.tech/tutorials/40 机器学习实战系列:https://www.showmeai.tech/t ...
- KingabseES 锁机制
KingabseES的锁机制 目录 KingabseES的锁机制 一.前言 二.锁机制 三.表级锁 ( Table-Level Locks ) 1.访问共享(ACCESS SHARE) 2.行共享(R ...
- 03 最小CMake项目
03 最小CMake项目 所有CMake项目都从一个CMakeLists.txt文件开始,此文件应该放在源代码树的最顶层目录下.可以将CMakeLists.txt想象成CMake项目文件,定义了从源和 ...
- eclipse 统一设置编码_项目工程统一设置成utf8编码_eclipse代码规范
在做项目的时候文件有的时候编码不同一 经常出现乱码,eclipse统一设置编码 可以解决项目编码混乱的问题, 设置eclipse java,jsp,css,js文件编码的方法如下: 1.在工具栏中点击 ...
- C++ "链链"不忘@必有回响之单链表
1. 前言 数组和链表是数据结构的基石,是逻辑上可描述.物理结构真实存在的具体数据结构.其它的数据结构往往在此基础上赋予不同的数据操作语义,如栈先进后出,队列先进先出-- 数组中的所有数据存储在一片连 ...