Python数据挖掘——银行分控模型的建立
数据初始化
import pandas as pd from keras.models import Sequential from keras.layers.core import Dense, Activation import numpy as np # 参数初始化 inputfile = 'F:\Python\data(1)\data\bankloan.xls' data = pd.read_excel(inputfile) x_test = data.iloc[:,:8].values y_test = data.iloc[:,8].values
神经网络
inputfile = 'F:\Python\data(1)\data\bankloan.xls'
data = pd.read_excel(inputfile)
x_test = data.iloc[:,:8].values
y_test = data.iloc[:,8].values
model = Sequential() # 建立模型
model.add(Dense(input_dim = 8, units = 8))
model.add(Activation('relu')) # 用relu函数作为激活函数,能够大幅提供准确度
model.add(Dense(input_dim = 8, units = 1))
model.add(Activation('sigmoid')) # 由于是0-1输出,用sigmoid函数作为激活函数
model.compile(loss = 'mean_squared_error', optimizer = 'adam')
# 编译模型。由于我们做的是二元分类,所以我们指定损失函数为binary_crossentropy,以及模式为binary
# 另外常见的损失函数还有mean_squared_error、categorical_crossentropy等,请阅读帮助文件。
# 求解方法我们指定用adam,还有sgd、rmsprop等可选
model.fit(x_test, y_test, epochs = 1000, batch_size = 10)
predict_x=model.predict(x_test)
classes_x=np.argmax(predict_x,axis=1)
yp = classes_x.reshape(len(y_test))
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y, yp)
import matplotlib.pyplot as plt
plt.matshow(cm, cmap=plt.cm.Greens)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
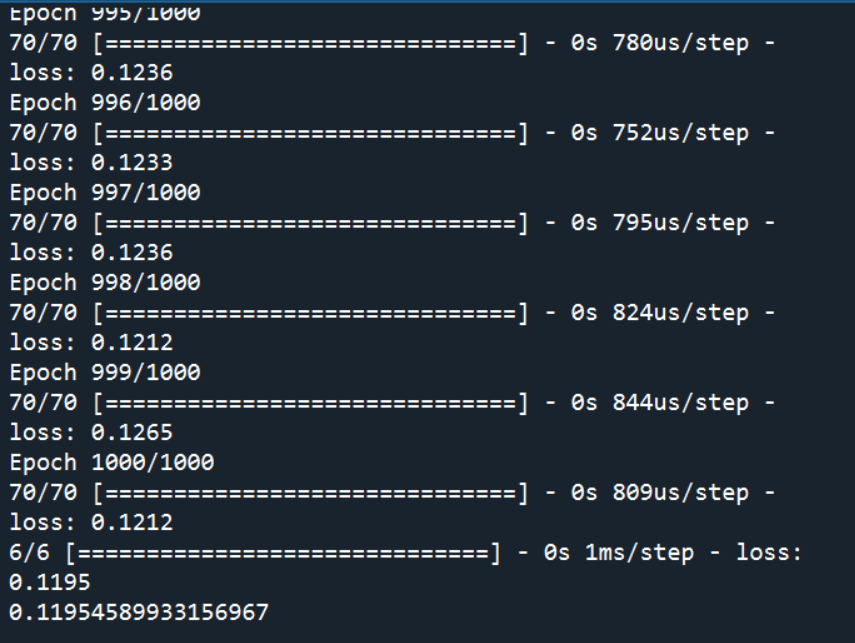
cm_plot(y_test,yp).show()# 显示混淆矩阵可视化结果
score = model.evaluate(x_test,y_test,batch_size=128) # 模型评估
print(score)
SVM支持向量机
from sklearn import svm
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from matplotlib import pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
data_load = "F:\Python\data(1)\data\bankloan.xls"
data = pd.read_excel(data_load)
data.describe()
data.columns
data.index
## 转为np 数据切割
X = np.array(data.iloc[:,0:-1])
y = np.array(data.iloc[:,-1])
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1, train_size=0.8, test_size=0.2, shuffle=True)
svm = svm.SVC()
svm.fit(X_test,y_test)
y_pred = svm.predict(X_test)
accuracy_score(y_test, y_pred)
print(accuracy_score(y_test, y_pred))
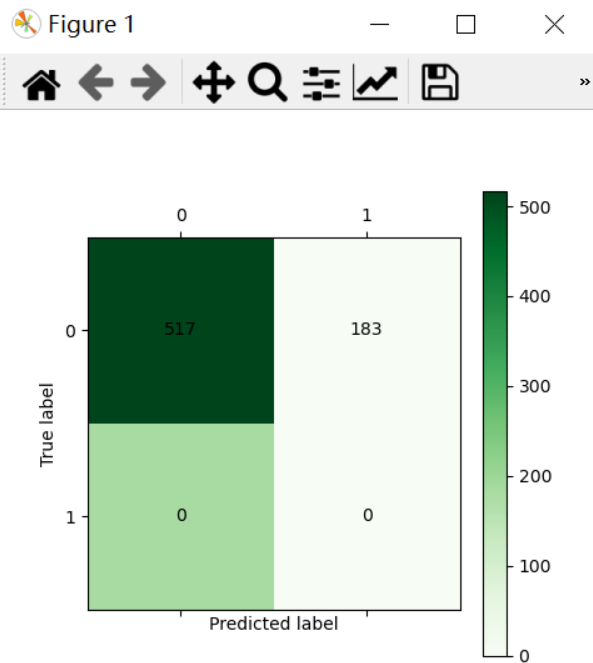
cm = confusion_matrix(y_test, y_pred)
heatmap = sns.heatmap(cm, annot=True, fmt='d')
heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha='right')
heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha='right')
plt.ylabel("true label")
plt.xlabel("predict label")
plt.show()

决策树
import pandas as pd
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.tree import export_graphviz
from IPython.display import Image
from sklearn import tree
import pydotplus
# 参数初始化
filename = 'F:\Python\data(1)\data\bankloan.xls'
data = pd.read_excel(filename) # 导入数据
# 数据是类别标签,要将它转换为数据
x = data.iloc[:,:8].astype(int)
y = data.iloc[:,8].astype(int)
dtc = DTC(criterion='entropy') # 建立决策树模型,基于信息熵
dtc.fit(x, y) # 训练模型
# 导入相关函数,可视化决策树。
x = pd.DataFrame(x)
with open("C:/Users/GPC2019/Desktop/大数据挖掘/data/tree.dot", 'w') as f:
export_graphviz(dtc, feature_names = x.columns, out_file = f)
f.close()
dot_data = tree.export_graphviz(dtc, out_file=None, #regr_1 是对应分类器
feature_names=data.columns[:8], #对应特征的名字
class_names=data.columns[8], #对应类别的名字
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png('F:\Python\data(1)\data\bankloan.xls') #保存图像
Image(graph.create_png())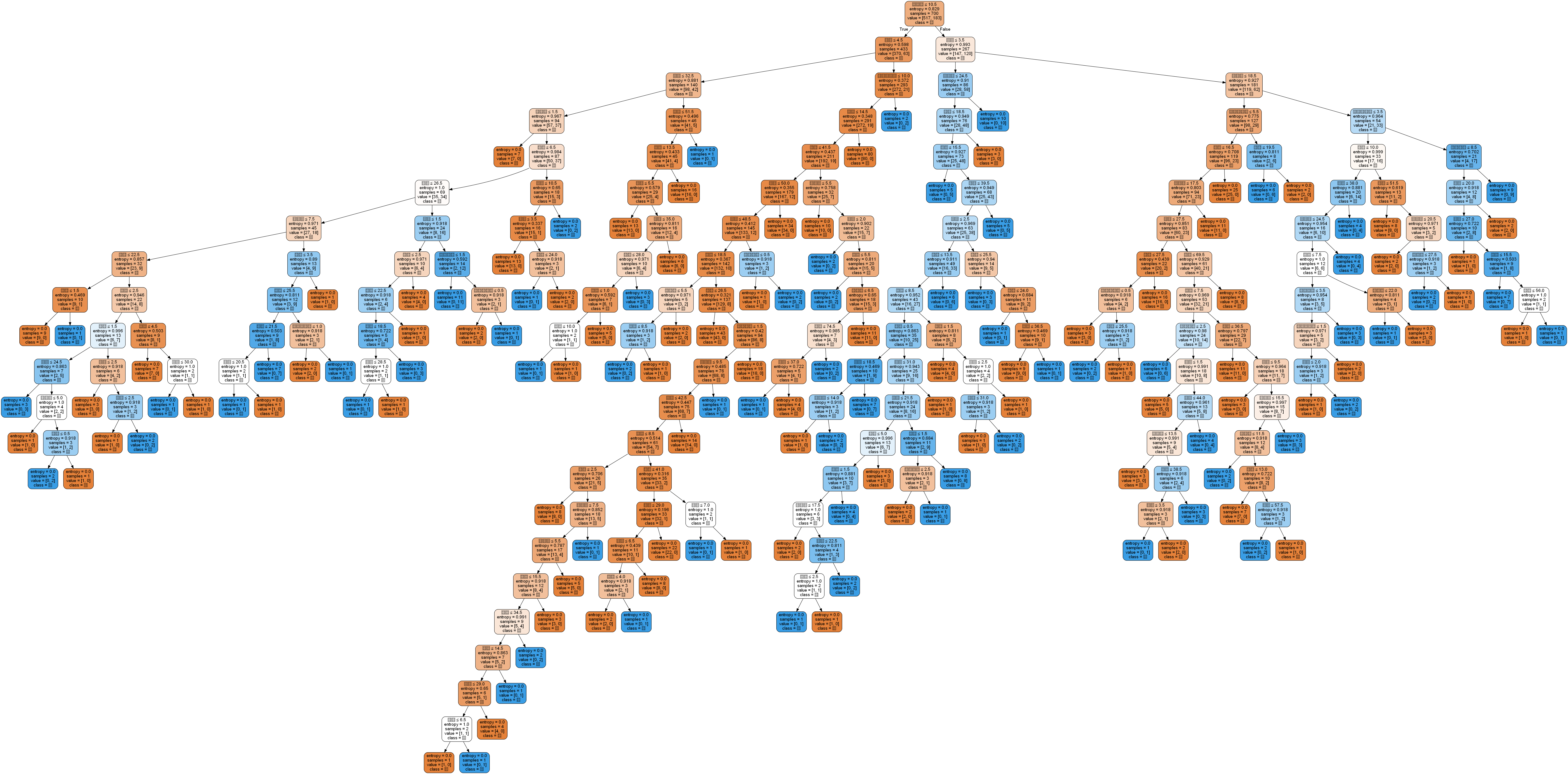
Python数据挖掘——银行分控模型的建立的更多相关文章
- python数据分析与挖掘实战————银行分控模型(几种算法模型的比较)
一.神经网络算法: 1 import pandas as pd 2 from keras.models import Sequential 3 from keras.layers.core impor ...
- Python数据挖掘之决策树DTC数据分析及鸢尾数据集分析
Python数据挖掘之决策树DTC数据分析及鸢尾数据集分析 今天主要讲述的内容是关于决策树的知识,主要包括以下内容:1.分类及决策树算法介绍2.鸢尾花卉数据集介绍3.决策树实现鸢尾数据集分析.希望这篇 ...
- python数据挖掘领域工具包
原文:http://qxde01.blog.163.com/blog/static/67335744201368101922991/ Python在科学计算领域,有两个重要的扩展模块:Numpy和Sc ...
- 使用sklearn进行数据挖掘-房价预测(6)—模型调优
通过上一节的探索,我们会得到几个相对比较满意的模型,本节我们就对模型进行调优 网格搜索 列举出参数组合,直到找到比较满意的参数组合,这是一种调优方法,当然如果手动选择并一一进行实验这是一个十分繁琐的工 ...
- 基于Python的信用评分卡模型分析(二)
上一篇文章基于Python的信用评分卡模型分析(一)已经介绍了信用评分卡模型的数据预处理.探索性数据分析.变量分箱和变量选择等.接下来我们将继续讨论信用评分卡的模型实现和分析,信用评分的方法和自动评分 ...
- python网络编程——网络IO模型
1 网络IO模型介绍 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-bl ...
- 2019年Python数据挖掘就业前景前瞻
Python语言的崛起让大家对web.爬虫.数据分析.数据挖掘等十分感兴趣.数据挖掘就业前景怎么样?关于这个问题的回答,大家首先要知道什么是数据挖掘.所谓数据挖掘就是指从数据库的大量数据中揭示出隐含的 ...
- Python数据挖掘课程
[Python数据挖掘课程]一.安装Python及爬虫入门介绍[Python数据挖掘课程]二.Kmeans聚类数据分析及Anaconda介绍[Python数据挖掘课程]三.Kmeans聚类代码实现.作 ...
- Python数据挖掘——数据预处理
Python数据挖掘——数据预处理 数据预处理 数据质量 准确性.完整性.一致性.时效性.可信性.可解释性 数据预处理的主要任务 数据清理 数据集成 数据归约 维归约 数值归约 数据变换 规范化 数据 ...
- python实现六大分群质量评估指标(兰德系数、互信息、轮廓系数)
python实现六大分群质量评估指标(兰德系数.互信息.轮廓系数) 1 R语言中的分群质量--轮廓系数 因为先前惯用R语言,那么来看看R语言中的分群质量评估,节选自笔记︱多种常见聚类模型以及分群质量评 ...
随机推荐
- docker kafka 一键搞定
1. docker network create app-tier 2. docker run -d --name zookeeper-server \ --network app-tier \ -e ...
- java spring 理解
1.spring IOC容器 其实就是 new 了一个 ApplicationContext 类对象.->应用上下文对象. 2.应用上下文对象 实例化.配置,并管理 bean. 所以上下文对象是 ...
- java方法的笔记
方法 方法的概念 方法(method)是将具有独立功能的代码块组织成为一个整体,使其具有特殊功能的代码集 注意: 方法必须先创建才可以使用,该过程成为方法定义 方法创建后并不是直接可以运行的,需要手动 ...
- 12组-Beta冲刺-3/5
一.基本情况 队名:字节不跳动 组长博客:https://www.cnblogs.com/147258369k/p/15599024.html Github链接:https://github.com/ ...
- global 函数
x = 15 # 全局变量Gdef func_a(): print(x)def func_b(): print(x)def func_c(): global x # 在定义函数内声明x为全局变量后,才 ...
- Educational Codeforces Round 143 (Rated for Div
Educational Codeforces Round 143 (Rated for Div. 2) Problem - B Ideal Point 给定n个线段区间\([l,r]\),我们定义\( ...
- ES6-Promise上
一.Promise作用:解决回调地狱问题 transitionend是过渡结束事件,只要过渡结束就会触发: 回调地狱:指的是层层嵌套的回调函数,代码看起来非常晕 <!DOCTYPE html&g ...
- Android Studio 生成Jar包以及是否混淆打包等ZengYuanFinn博客等你来查看
1,Android studio生成jar包的前提是要确保生成的代码是引用的module工程: 2,在需要生成jar包的build.gradle(上图倒数第三行)中添加如下代码: //生成jar包 t ...
- centos7.6 dokcer-compose在线和离线安装
在线安装可参考官网文档:https://docs.docker.com/compose/install/#install-compose curl -SL https://github.com/doc ...
- Docker的常见使用
一.Docker的常见使用 1.docker的使用 1.1 查看docker版本号信息 docker version docker info 1.2 启动docker systemctl start ...