MS-TCT: Multi-Scale Temporal ConvTransformer for Action Detection概述
1.针对的问题
为了在未修剪视频中建模时间关系,以前的多种方法使用一维时间卷积。然而,受核大小的限制,基于卷积的方法只能直接获取视频的局部信息,不能学习视频中时间距离较远的片段之间的直接关系。因此,这种方法不能模拟片段之间的远程交互作用,而这对动作检测可能很重要。
多头自注意力虽然可以对视频中的长期关系建模,然而,现有的方法依赖于在输入帧本身上对这种长期关系建模,一个时序token只包含很少的帧,这通常与动作实例的持续时间相比太短了。此外,在这种设置中,transformers需要明确地学习由于时间一致性而产生的相邻token之间的强关系,而这对于时间卷积来说很自然的(即局部归纳偏差)。因此,纯粹的transformer体系结构可能不足以建模复杂的动作检测时序依赖关系。
2.主要贡献
(1)提出了一种高效的ConvTransformer用于建模未修剪视频中的复杂时序关系;
(2)引入一个新分支来学习与实例中心相关的位置,这有助于在密集标注的视频中进行动作检测;
(3)在3个具有挑战性的密集标注动作数据集上改进了最先进的技术。
3.方法
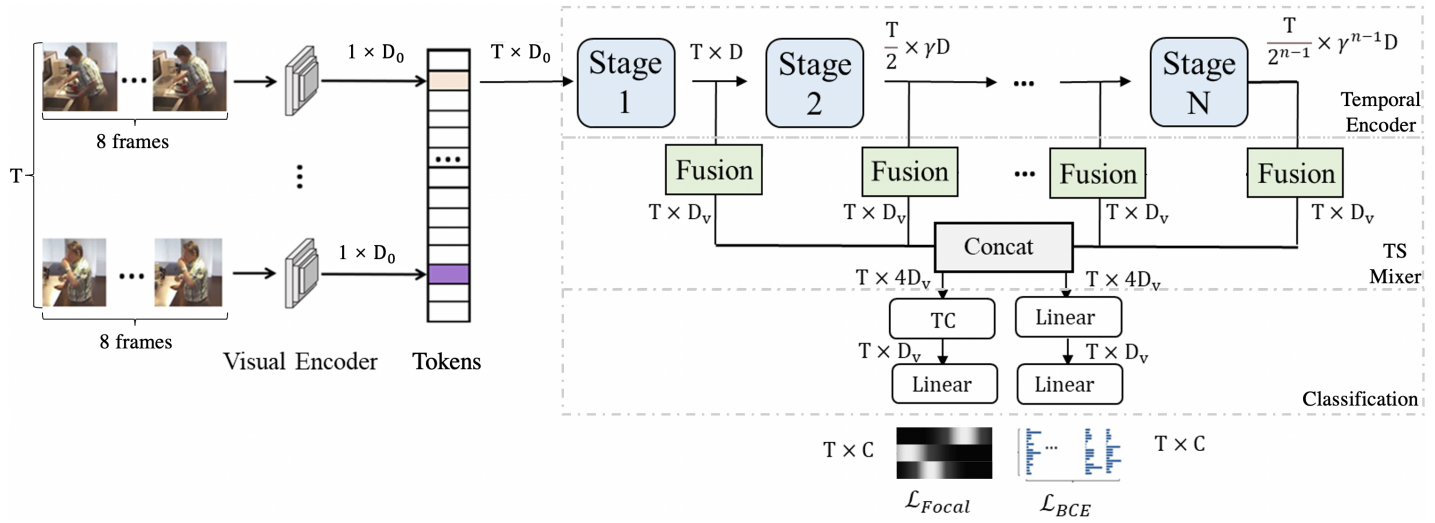
本文提出了一种新的transformer:MS-TCT,它继承了transformer编码器结构,同时利用了时间卷积技术。可以在不同的时间尺度上对全局和局部的时间token进行建模。
模型由4部分组成:
(1)对初步视频表示进行编码的视觉编码器(Visual Encoder),使用I3D主干编码视频。每个视频分为T个不重叠的片段(训练时),每个片段由8帧组成。这样的RGB帧作为输入片段提供给I3D网络。每一个片段级特征(I3D的输出)都可以看作是一个时间步的transformer token(即时序token)。沿着时间轴堆叠token,形成T × D0视频token表示,被送入时间编码器。
(2)在不同时间尺度上对时间关系进行结构建模的时间编码器(即时间编码器)。每个stage都为一个下面的模块
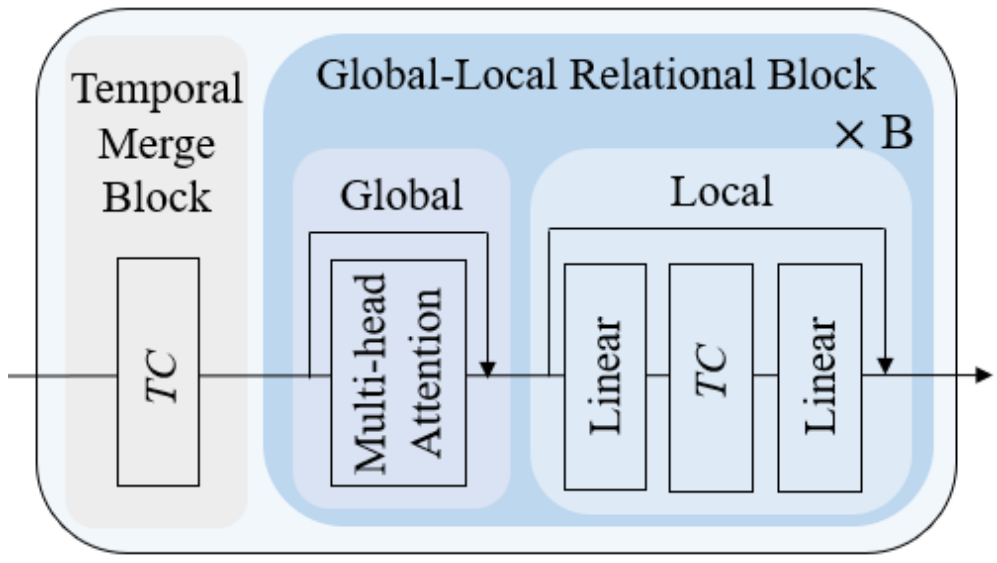
包括(1)一个时序合并块和(2)×B Global-Local关系块。每个全局-局部关系块包含一个全局和一个局部关系块。其中Linear和TC分别表示核大小为1和k的一维卷积层。早期阶段学习带有较多时序token的细粒度动作表示,而后期阶段学习带有较少时序token的粗粒度表示。
时间合并块可以减少token的数量(即时序分辨率),同时增加特征维数。通过单个卷积层将token数量减半,并将通道大小扩展×γ,Global-Local关系块包含全局关系块和局部关系块,前者通过多头自注意力层对长期动作依赖关系进行建模,后者使用一个时间卷积层通过输入来自相邻token的上下文信息(即局部归纳偏差)来增强token表示。每个阶段最后一个Global-Local关系块的输出token被组合并提供给下面的Temporal Scale Mixer。
(3)一个时间尺度混合器,称为TS混合器,它结合了多尺度的时间表征,将时间编码器产生的多尺度token聚合起来,形成统一的视频表示,具体结构如下:
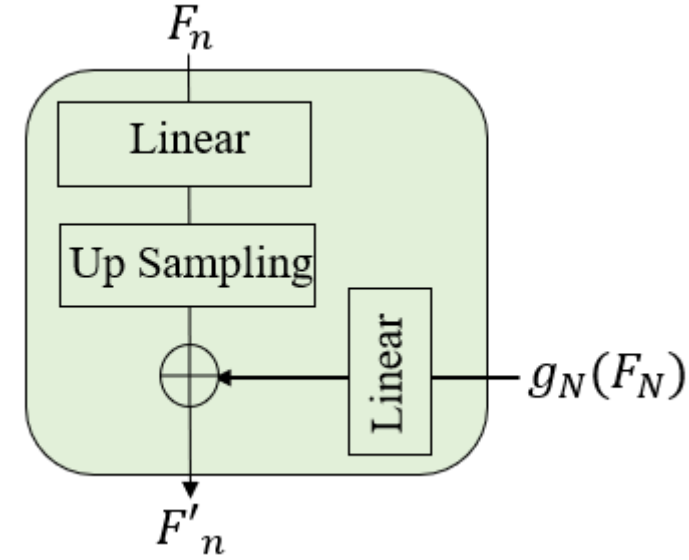
为了预测动作概率,分类模块需要以原始的时间长度作为网络输入进行预测。因此,通过执行上采样和线性投影步骤在时间维度上插入token,阶段n的输出tokens Fn调整大小并向上采样到T×Dv,由于早期阶段(低语义)具有较高的时间分辨率,而后期阶段(高语义)具有较低的时间分辨率。为了平衡分辨率和语义,最后一阶段N的上采样token经过线性层处理,并与每一阶段(N < N)上采样的token求和。最后,将所有refine tokens串联起来,得到最终的多尺度视频表示Fv∈RT×NDv。
(4)一个分类模块,预测类的概率。联合学习两个分类任务,引入了一个新的分类分支来学习动作实例的热图,它基于动作中心和持续时间而随时间变化。使用这种热图表示的目的是在学习到的MS-TCT tokens中编码时间相对位置。首先需要构建class-wise ground-truth热图响应,通过考虑一组一维高斯滤波器的最大响应构建了G∗ 。每个高斯滤波器对应于视频中的一个动作类实例,在时间上以特定的动作实例为中心。然后在预测的热图和ground-truth热图间应用action focus loss,另一个分支执行常见的多标签分类,通过BCE损失进行训练。
模型结构如下:
MS-TCT: Multi-Scale Temporal ConvTransformer for Action Detection概述的更多相关文章
- Temporal Action Detection with Structured Segment Networks (ssn)【转】
Action Recognition: 行为识别,视频分类,数据集为剪辑过的动作视频 Temporal Action Detection: 从未剪辑的视频,定位动作发生的区间,起始帧和终止帧并预测类别 ...
- 论文阅读: End-to-end Learning of Action Detection from Frame Glimpses in Videos
End-to-End Learning of Action Detection from Frame Glimpses in Videos CVPR 2016 Motivation: 本 ...
- Object Detection / Human Action Recognition 项目
https://towardsdatascience.com/real-time-and-video-processing-object-detection-using-tensorflow-open ...
- 【论文笔记】Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition 2018-01-28 15:4 ...
- 行为识别(action recognition)相关资料
转自:http://blog.csdn.net/kezunhai/article/details/50176209 ================华丽分割线=================这部分来 ...
- 【计算机视觉】行为识别(action recognition)相关资料
================华丽分割线=================这部分来自知乎==================== 链接:http://www.zhihu.com/question/3 ...
- ASP.NET MVC的Action Filter
一年前写了一篇短文ASP.NET MVC Action Filters,整理了Action Filter方面的资源,本篇文章详细的描述Action Filter.Action Filter作为一个可以 ...
- Recent papers on Action Recognition | 行为识别最新论文
CVPR2019 1.An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognit ...
- .Net MVC 自定义Action类型,XmlAction,ImageAction等
MVC开发的时候,难免会用到XML格式数据,如果将XML数据当作字符串直接返回给前台,其实这不是真正意义上的xmL,你可以看到ContentType是text/html而非XML类型,这往往会造成前端 ...
- 老刘 Yii2 源码学习笔记之 Action 类
Action 的概述 InlineAction 就是内联动作,所谓的内联动作就是放到controller 里面的 actionXXX 这种 Action.customAction 就是独立动作,就是直 ...
随机推荐
- 基于 Traefik 的 Basic Auth 配置
前言 Traefik是一个现代的HTTP反向代理和负载均衡器,使部署微服务变得容易. Traefik可以与现有的多种基础设施组件(Docker.Swarm模式.Kubernetes.Marathon. ...
- 2022年7月13日,第四组,周鹏,JS做计算器代码
代码不难,看了我前面笔记的应该能看懂. 没看?(= ̄ω ̄=)喵了个咪(๑‾᷅^‾᷅๑) 嫌弃你 还看啥,去看啊!要不直接复制代码吧!( ̄へ ̄)( ̄へ ̄)( ̄へ ̄) Document 0 / * - 7 ...
- CH32V307以太网(芯片内部10M)
用过WCH的CH579M或者CH563的话,就会发现CH32V307这个自带的10M以太网代码编写与前两颗芯片流程十分相似.部分区别就在于初始化方面. 代码流程依旧按照 初始化--->等待PHY ...
- forms组件渲染标签、展示信息、校验数据的一些补充,forms组件参数和源码剖析,modelform组件,Django中间
今日内容 forms组件渲染标签 forms组件渲染标签的方式1 <p>forms组件渲染标签的方式1</p> {{ form_obj.as_p }} {{ form_obj. ...
- lock 和 Monitor (转载)
Lock和Monitor都是对被操作对象同步控制的方法 Lock 是 Monitor的简化版本,IL callvirt ...Monitor.Enter(object)...leave.s.... c ...
- 使用gm/ID方法设计二级运算放大器
1 设计指标 运算放大器采用图1所示的电路结构,电路中的电流源均采用共源共栅结构,可以获得较高的共模抑制比和电流复制精度.其性能指标为增益带宽积GBW=100MHz,负载电容CL=2pF.本设计采用的 ...
- Java基础学习笔记-数据类型、数制
数据类型,跟JS感觉差异不是很大,但是有个String不是很一样的样子 数据类型分为 基本数据类型和复合数据类型 基本数据类型分为下面三种 数值类型 1.整数类型:byte,short,int,lon ...
- angular打包部署设置publicPath文件目录及访问地址,解决打包完成后,运行打包文件,报错404,js,css未找到
方案1.改变文件目录 不改变访问地址:XXXPRO 是部署的服务器上面的 文件夹名称 ng build --prod --base-href /XXXPRO 方案2.改变访问地址录同时改变文件目录-- ...
- WPF中使用WebView2控件
目录 WebView2简介 概述 优势 支持的运行时平台 进程模型 基本使用 安装WebView2运行时 安装WebView2Sdk 打开一个网页 导航事件 打开一个网页的过程 更改url的过程 空u ...
- 应用容器引擎-Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化.容器是完全使用沙箱 ...