V8中的快慢属性(图文分解更易理解)
出于好奇:js中使用json存数据查找速度快,还是使用数组存数据查找快?
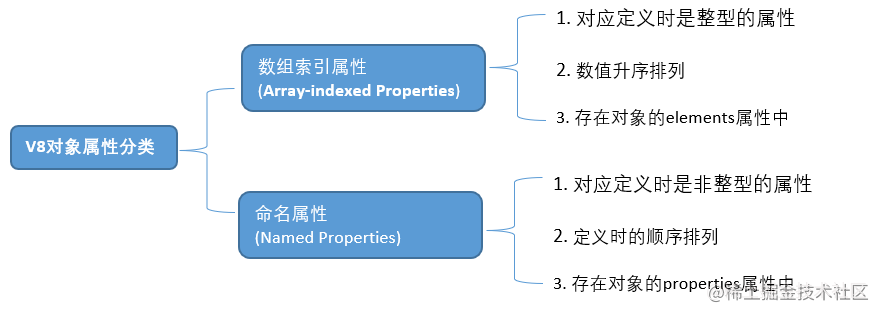
探究V8中对象的实现原理,熟悉数组索引属性、命名属性、对象内属性、隐藏类、描述符数组、快慢属性等等。
D8调试工具使用请来这里
对象属性
我们先来看一个例子。假设我们有这样的代码:
function testV8() {
this[100] = 'test-100'
this[1] = 'test-1'
this["D"] = 'foo-D' // 字符串key
this["B"] = 'foo-B'
this[50] = 'test-50'
this[9] = 'test-9'
this[8] = 'test-8'
this[3] = 'test-3'
this[5] = 'test-5'
this["4"] = 'test-4' // 整型key
this["A"] = 'foo-A'
this["C"] = 'foo-C'
this[4.5] = "foo-4.5" // 非整型key
}
const testObj = new testV8()
for (const key in testObj) {
console.log(`key:${key}, value:${testObj[key]}`)
}
运行输出结果如下:

输出结果分析:
多次运行代码,发现输出key-value的顺序是一致的,并不存在随机性。
再经测试并仔细观察发现有如下结论:
对于整数型的 key 值,会从小到大遍历(
按数值升序)对于非整数型的 key 值,会按照设置的先后顺序遍历
根据这一个现象,我们就要探究下,在V8引擎中,对象属性内部的设计思想。
在 V8 内部,为了有效地提升存储和访问这两种属性的性能,分别使用了两个线性数据结构来分别保存两种属性。
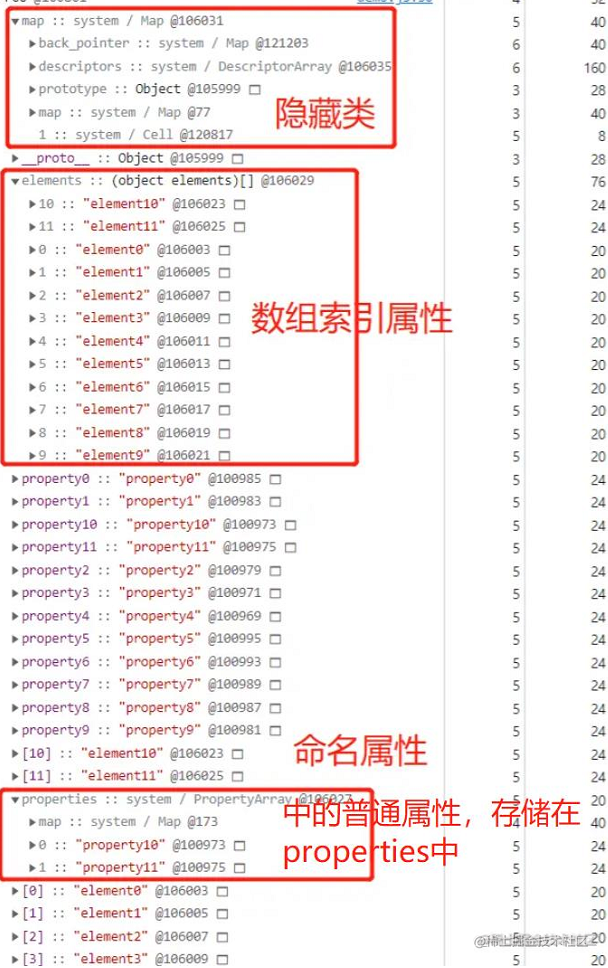
这两个结论在V8中也被证实,前后者分别被称为 数组索引属性(Array-indexed Properties)和 命名属性(Named Properties),遍历时一般会先遍历数组索引属性。前后两者在底层存储在两个单独的数据结构中,分别用 properties 和 elements 两个指针指向它们,如下图
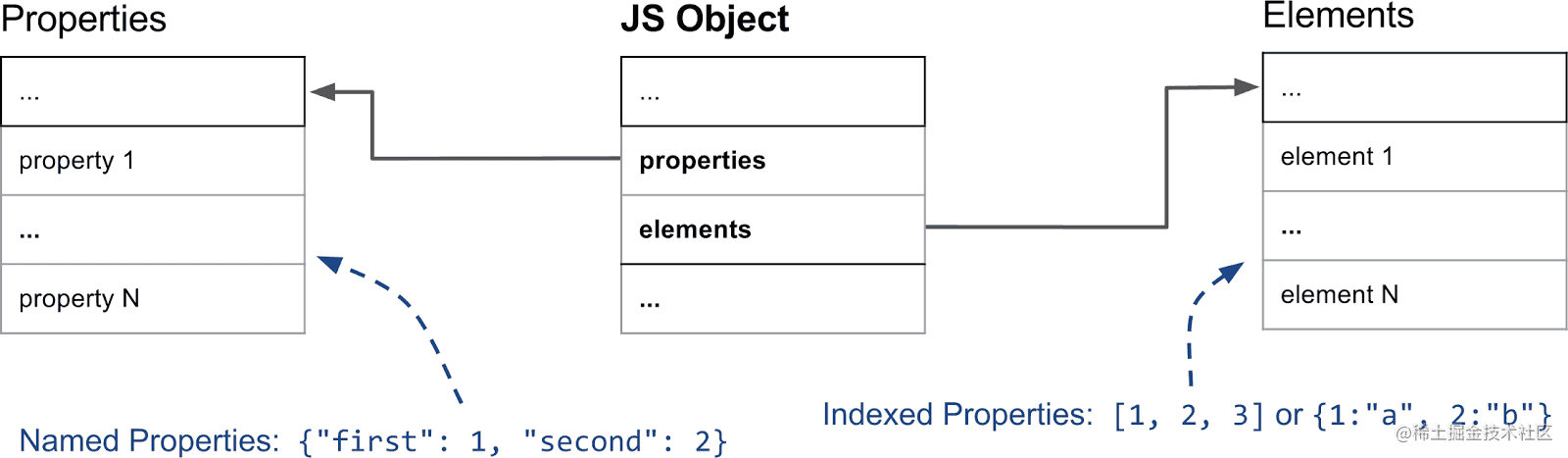
如果在数组索引属性(排序属性)和命名属性(常规属性)同时存在的情况下,优先按数组属性排序,上面的例子中将字符串形式的整型key:"4"转换成了数字整型,而浮点数"4.5"转换成了字符串,V8 会先从 elements 属性中按照顺序读取所有的元素,然后再在 properties 属性中读取所有的元素,这样就完成一次索引操作。我们通过chrome调试工具snapshot来佐证下:
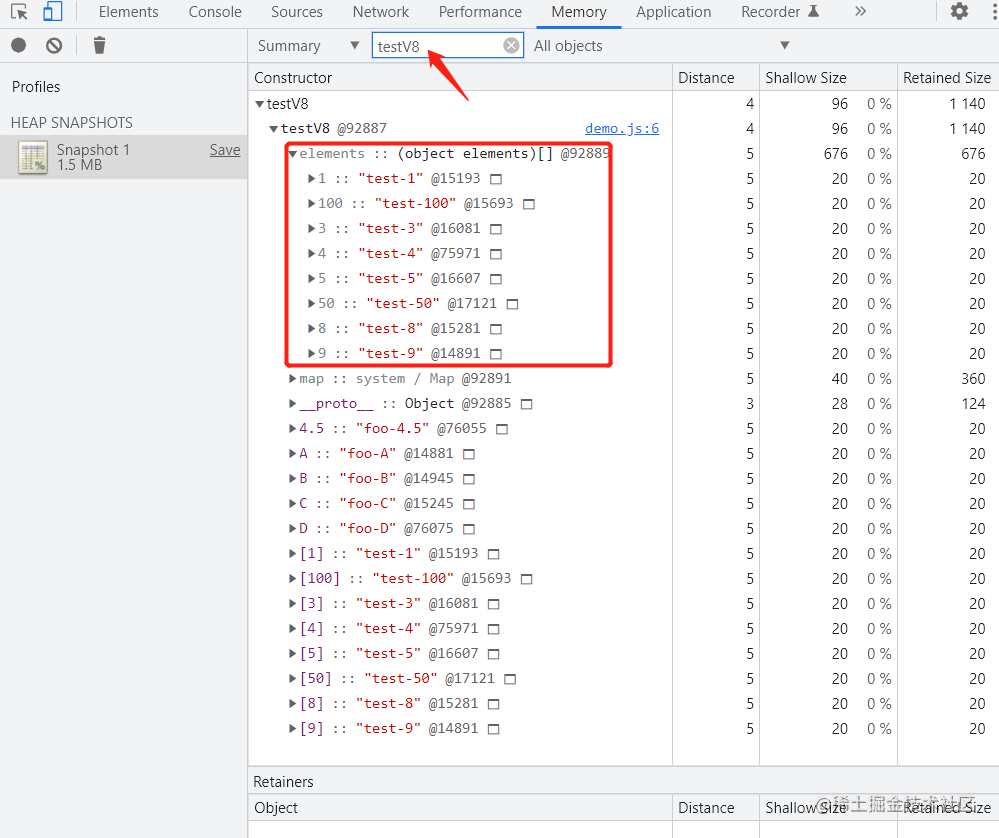
发现并没有 properties 属性?实际上,V8 有一种策略:如果命名属性少于等于 10 个时,命名属性会直接存储到对象本身,而无需先通过 properties 指针查询,再获取对应 key 的值,省去中间的一步,从而提升了查找属性的效率。直接存储到对象本身的属性被称为 对象内属性(In-object Properties)。对象内属性与 properties、elements 处于同一层级。
插话:chrome调试工具snapshot使用
打开控制台
点击 Memory , 可以看到 Profiles
点击下方 Take snapshot 按钮
过滤 testV8, 查看信息
如下图
对象内属性(In-object Properties)
当采用两种线性结构存储后,在查询属性的时候,就会明显多出了一个步骤,要先去查询到Properties对应的对象(多了一次寻址的过程),再从Properties对象中查到对应的某个key的值。
V8 有一种策略:如果命名属性少于等于 10 个时,命名属性会直接存储到对象本身,而无需先通过 properties 指针查询,再获取对应 key 的值,省去中间的一步,从而提升了查找属性的效率。直接存储到对象本身的属性被称为 对象内属性(In-object Properties)。对象内属性与 properties、elements 处于同一层级。
为了印证这个说法,将代码替换为如下内容,重新打 snapshot。可以看到超出 10 个的部分 property10 和 property11 存储在 properties 中,这部分命名属性称为普通属性:
function Foo(properties, elements) {
//添加可索引属性
for (let i = 0; i < elements; i++) {
this[i] = `element${i}`
}
//添加常规属性
for (let i = 0; i < properties; i++) {
const prop = `property${i}`
this[prop] = prop
}
}
const foo = new Foo(12, 12)
至此,我们已经对命名属性、数组索引属性与对象内属性有一个基本了解。
对象内属性 or 普通属性
对象内属性是指那些直接存存储在对象上的命名属性(10个),超出对象内属性数量限制的属性被存放与 properties 指针指向的数据结构中,这部分虽然增加了一层查询,但扩容非常方便。
注意:下图中,先不用管HiddenClass,后面会讲,暂且把它看成一个“指针”吧
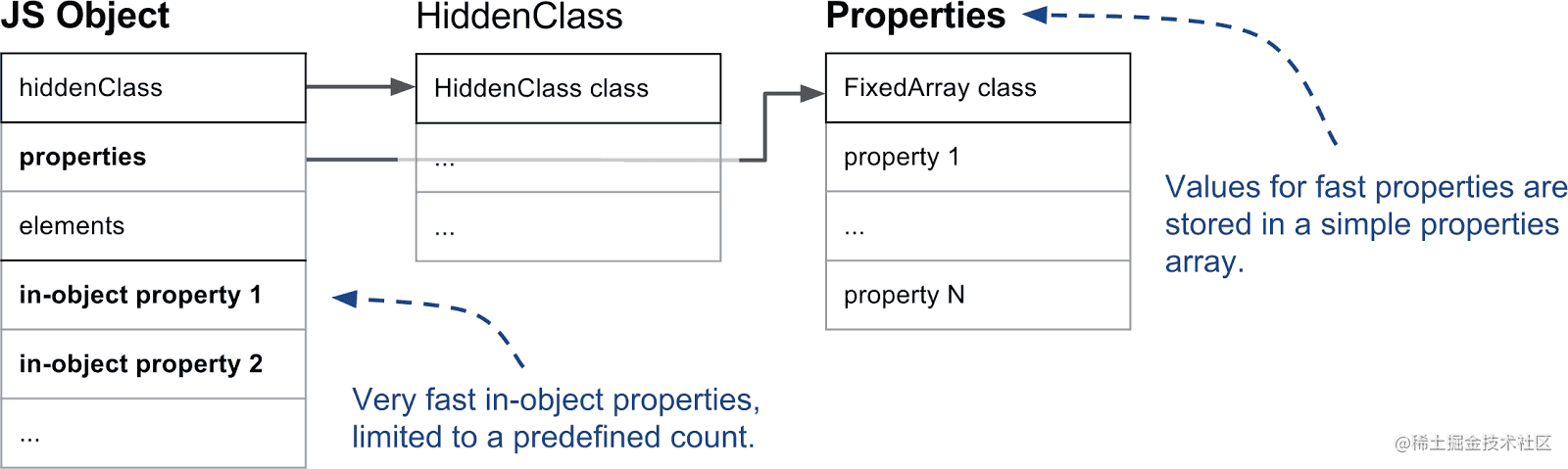
接着看什么是HiddenClass隐藏类(Hidden Class)
隐藏类(Hidden Class)
静态语言中,当创建类型后,就不能再次改变了,属性可以通过固定的偏移量来访问,但在js中却不是,对象的属性的类型、值等信息是可以随时改变的,也就是说运行的时候才能拿到最后的属性内存偏移量,V8为了提升对象的属性获取性能,设计了Hidden Class 隐藏类的概念,每一个对象都有对应的隐藏类,当每次对象的属性发生改变时,V8会动态更新对应的内存偏移量更新到隐藏类中。
每个对象都拥有自己的隐藏类:上面例子中对应的
map属性就是隐藏类对象。隐藏类中记录了对象中每个属性的标识信息(descriptors),它保存了属性key以及描述符数组的指针。
描述符数组包含了有关命名属性的信息,例如名称本身以及值保存的位置,但只会存命名属性相关的,不会保存整数类的属性
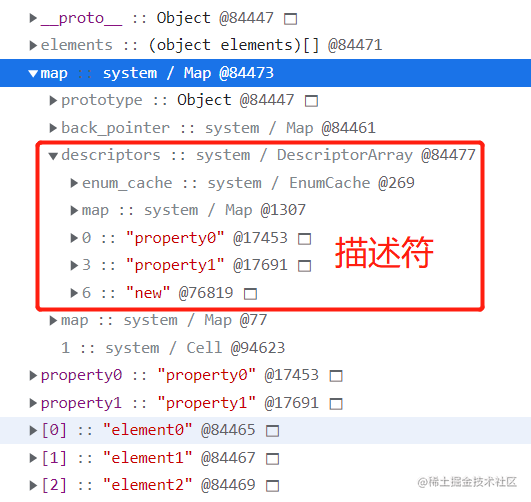
- 当对象创建一个新属性,或者一个老属性被删除时,V8会创建一个新的隐藏类并通过back_pointer指针指向老的隐藏类,新的隐藏类中只记录进行了变更的属性信息,随后对象指向隐藏类的指针会指向新的隐藏类。
const testobj1 = new Foo(2, 3);
const testobj2 = new Foo(2, 3);
testobj2.new = "new";

隐藏类和描述符数组
在 V8 中,每个 JavaScript 对象的第一个字段都指向一个隐藏类(HiddenClass)。隐藏类是用来描述和便于跟踪 JavaScript 对象的「形状」的,里面存储了对象的元信息如:对象的属性数量、对象原型的引用等等。多个具有相同结构(即命名属性和顺序均相同)的对象共享相同的隐藏类。因此,动态地为对象增加属性的过程中隐藏类会被更改。
我们先看看隐藏类的结构:
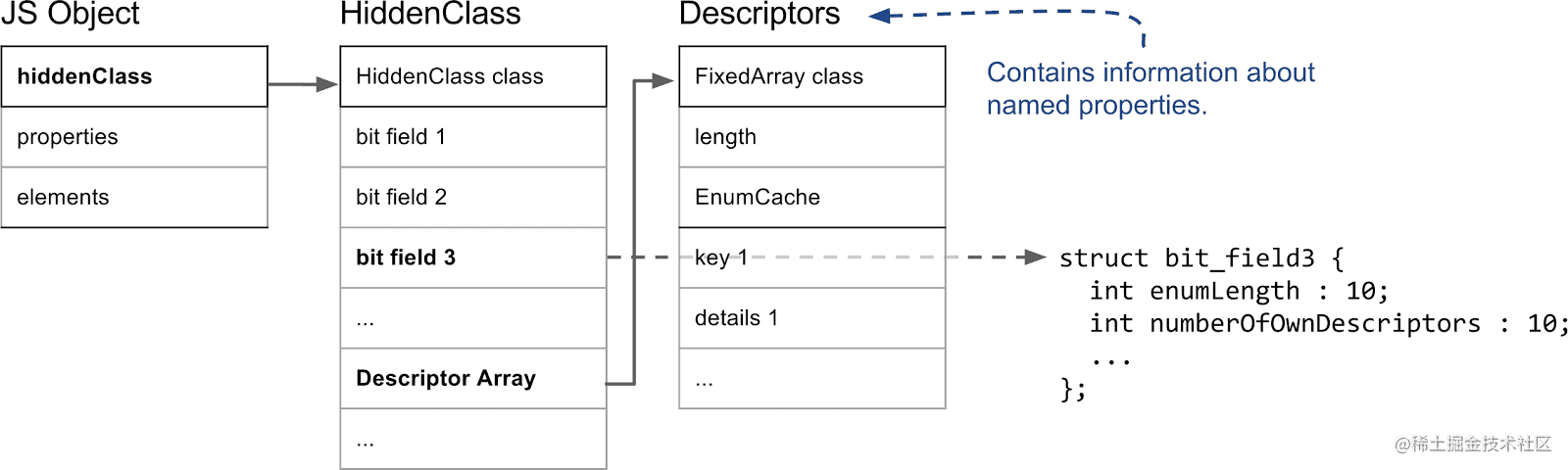
对于隐藏类来说最重要的是第三位字段(bit field 3),记录了命名属性的数量和一个指向描述符数组(Descriptor Array)的指针,描述符数组中存储了命名属性的相关信息,因此当 V8 需要获取命名属性的具体信息时,需要先通过 hiddenClass 指针找到对应的 HiddenClass,获取 HiddenClass 第三位字段中记录的描述符数组指针,然后在数组中查询特定的命名属性(修改的时候也是一样的过程,划重点!!)。数组索引属性是不会被记录在该数组的,因为他们不会让 V8 更改隐藏类。
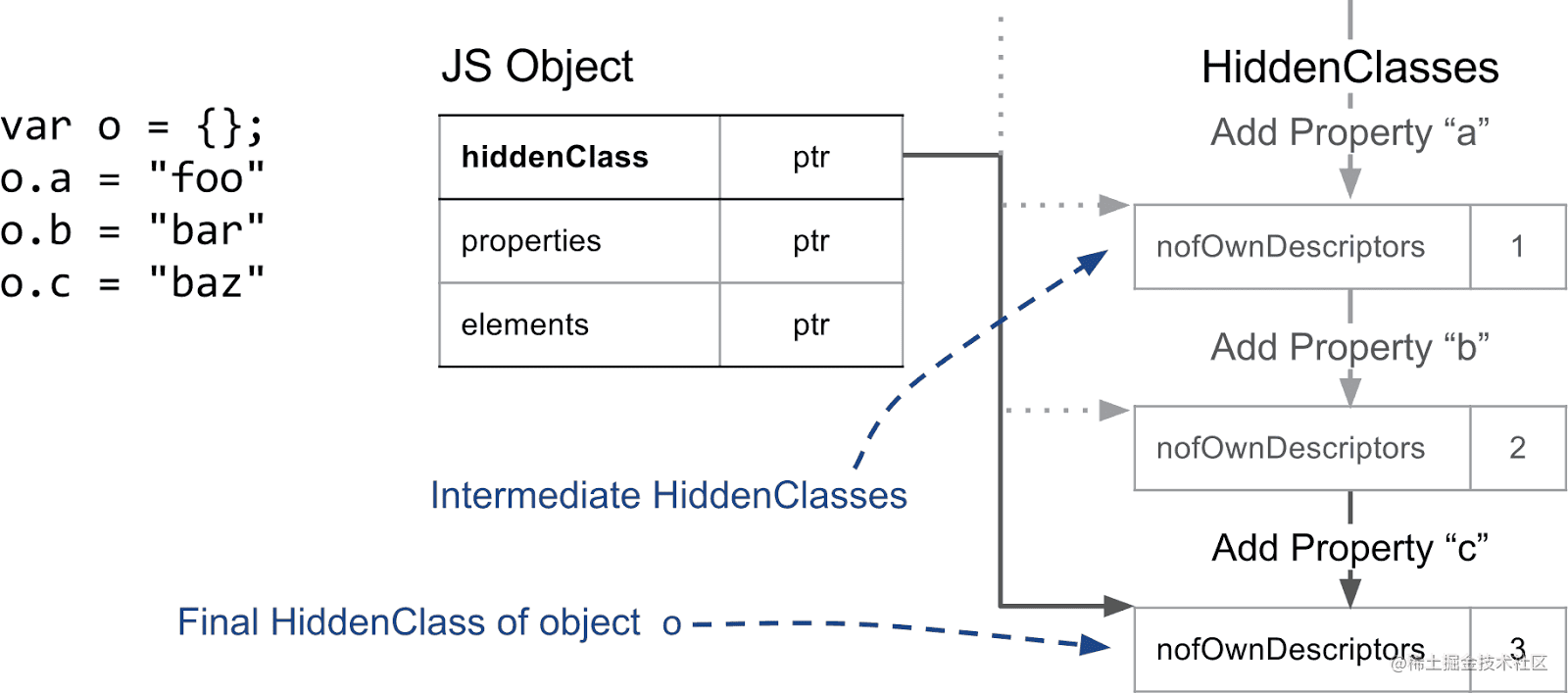
以上图为例,当我们创建一个空对象 o 并依次为其增加 a、b、c 三个命名属性时,object o 中的 hiddenClass 会经历以下阶段:
增加 a 属性,生成过渡 HiddenClass 1
增加 b 属性,生成过渡 HiddenClass 2
增加 c 属性,生成过渡 HiddenClass 3
属性添加完成,此时 object o 的 hiddeClass 指针指向 HiddenClass 3
这三个过渡的 HiddenClasses 会被 V8 连接起来,生成一个叫过渡树(transition tree)的结构,从而让 V8 可以追踪 HiddenClasses 之间的关系,并保证相同结构的对象经过相同顺序的命名属性增加操作后,具有相同的 HiddenClass。
如果相同结构的对象增加不同的命名属性,V8 会为在过渡树中开出新的分支,以标识原本相同的 hiddenClass 增加不同命名属性后派生出的不同 Class:

总结
相同结构(命名属性和顺序均相同)的对象共享相同的 HiddenClass新属性的添加伴随着新 HiddenClass 的创建
数组索引索性不会改变 HiddenClass
快属性 or 慢属性
线性数据结构的读取速度更快(读取复杂度为 O(1)),因此将存储在线性结构中的命名属性称为快属性。快属性只通过 properties 中的索引访问,但是如前文所述,为了从属性名访问到实际存储位置,V8 必须参考 HiddenClass 上的 Descriptor Array,因为里面存储了关于命名属性的元信息。
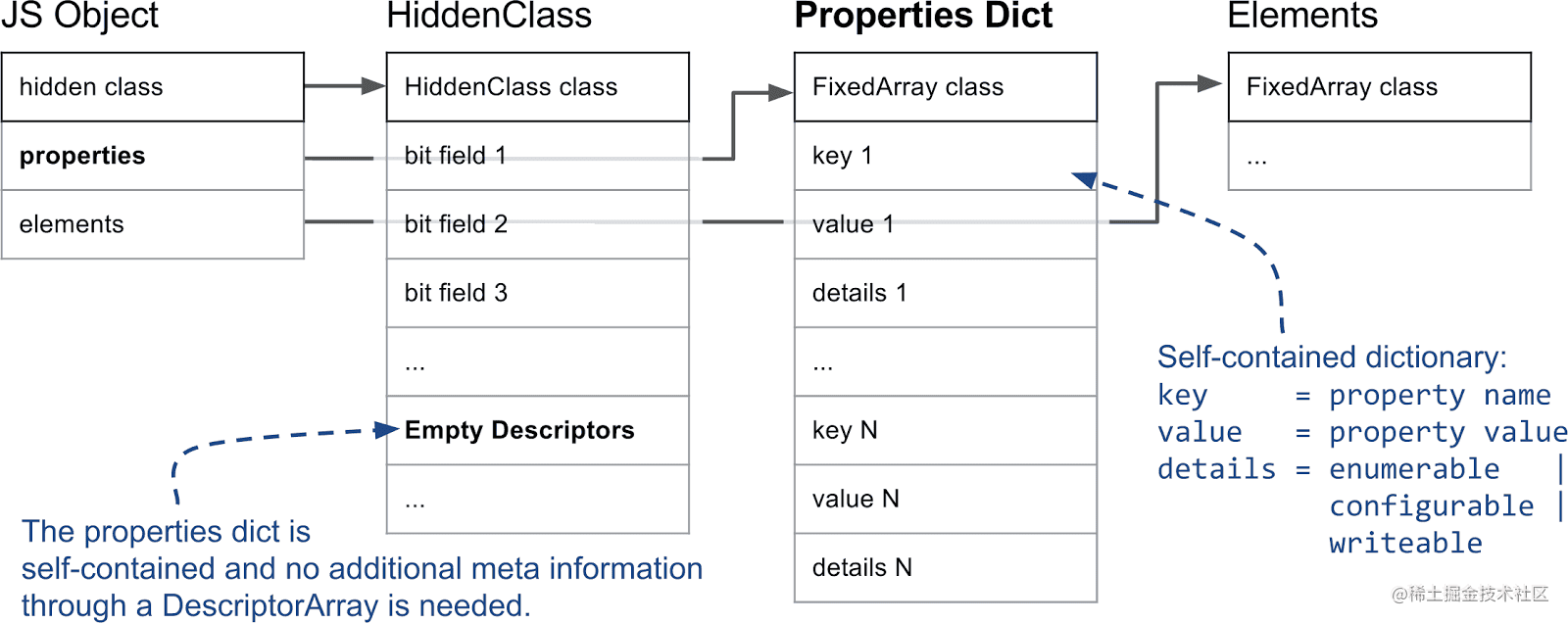
因此,倘若一个对象频繁地增删属性,而 V8 还维持原来的线性结构存储的话,插入和删除的复杂度都为 O(n),同时耗费大量的时间、内存在维护 HiddenClass 和 Descriptor Array 上。
为了减少这部分开销,V8 将这些本来会存储在线性结构中的快属性降级为慢属性。此时原本用于存储属性元信息的 Descriptor Array 被置空,转而将信息存储到 properties 内部维护的一个字典(称为 Properties Dictionary)中,这样对对象的增删属性操作便不需更新 HiddenClass 了。但这也意味着 V8 内部的内联缓存(inline-cache)不会生效,所以这种属性被称为慢属性。
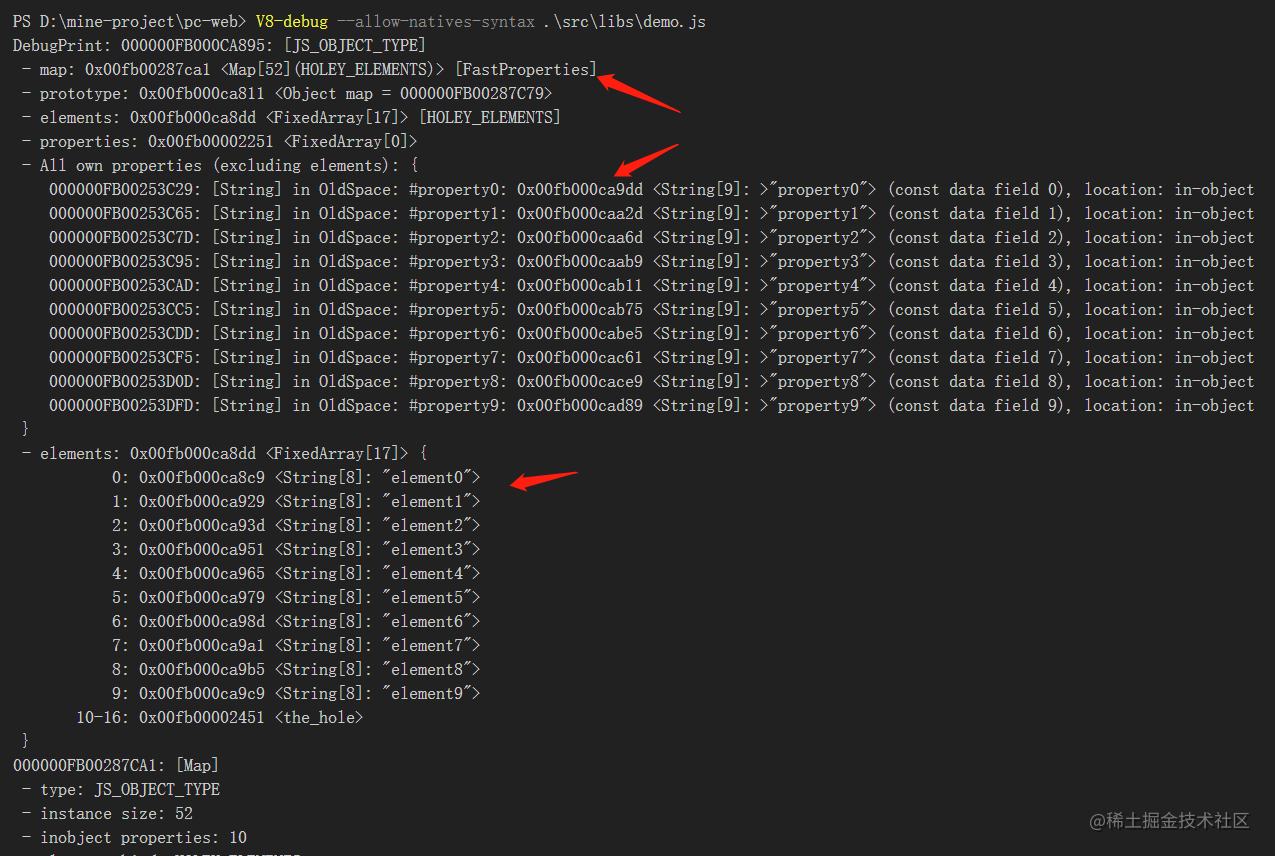
快属性
保存在线性数据结构中的属性,通过索引就可以访问到对应的属性值
const testobj = new Foo(10, 10);
%DebugPrint(testobj);
如图
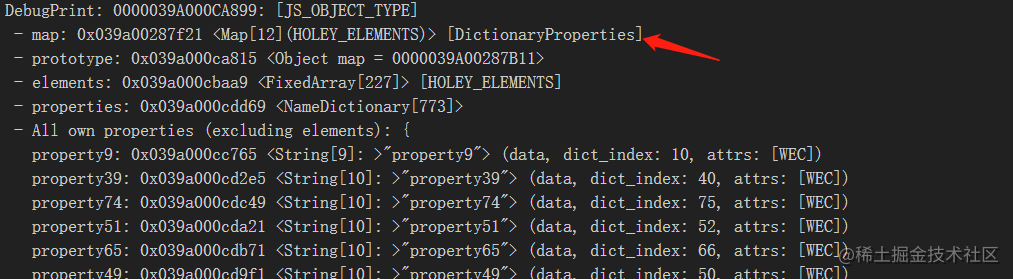
慢属性
属性过多的时候,V8会采用"慢属性"的处理,属性的对象内部会有独立的非线性数据结构(字典)
const testobj = new Foo(100, 200);
%DebugPrint(testobj);
如图
总结:
当属性数量不是特别多的情况下,Properties的索引是有序的(快属性)
当属性数量特别多的时候,就会变成无序的字典类型的存储(慢属性)。
最后
这篇文章难产了,由于工作较忙,用碎片时间在学习,大概三四天前我就着手写了,今天才算发出来。
加油
本来想着把快慢数组一块分析了,留在下一篇吧,谢谢
参考文档: https://z3rog.tech/blog/2020/fast-properties.html
持续更文,关注我,你会发现一个踏实努力的宝藏前端,让我们一起学习,共同成长吧。
喜欢的小伙伴记得点赞关注收藏哟,回看不迷路
欢迎大家评论交流, 蟹蟹
V8中的快慢属性(图文分解更易理解)的更多相关文章
- V8中的快慢数组(附源码、图文更易理解😃)
接上一篇掘金 V8 中的快慢属性,本篇分析V8 中的快慢数组,了解数组全填充还是带孔.快慢数组.快慢转化.动态扩缩容等等.其实很多语言底层都采用类似的处理方式,比如:Golang中切片的append操 ...
- 【转】Raft 为什么是更易理解的分布式一致性算法
编者按:这是看过的Raft算法博客中比较通俗的一篇了,讲解问题的角度比较新奇,图文并茂,值得一看.原文链接:Raft 为什么是更易理解的分布式一致性算法 一致性问题可以算是分布式领域的一个圣殿级问题了 ...
- Raft 为什么是更易理解的分布式一致性算法
一致性问题可以算是分布式领域的一个圣殿级问题了,关于它的研究可以回溯到几十年前. 拜占庭将军问题 Leslie Lamport 在三十多年前发表的论文<拜占庭将军问题>(参考[1]). 拜 ...
- Raft 为什么是更易理解的分布式一致性算法(转)
一致性问题可以算是分布式领域的一个圣殿级问题了,关于它的研究可以回溯到几十年前. 拜占庭将军问题 Leslie Lamport 在三十多年前发表的论文<拜占庭将军问题>(参考[1]). 拜 ...
- Raft 为什么是更易理解的分布式一致性算法——(1)Leader在时,由Leader向Follower同步日志 (2)Leader挂掉了,选一个新Leader,Leader选举算法。
转自:http://www.cnblogs.com/mindwind/p/5231986.html Raft 协议的易理解性描述 虽然 Raft 的论文比 Paxos 简单版论文还容易读了,但论文依然 ...
- 【转载】Raft 为什么是更易理解的分布式一致性算法
一致性问题可以算是分布式领域的一个圣殿级问题了,关于它的研究可以回溯到几十年前. 拜占庭将军问题 Leslie Lamport 在三十多年前发表的论文<拜占庭将军问题>(参考[1]). 拜 ...
- struts.xml 文件中的 namespace 属性图文详解
namespace:名称空间.默认值是""(空字符串). 名称空间+动作名称:构成了动作的访问路径
- V8 是怎么跑起来的 —— V8 中的对象表示
V8 是怎么跑起来的 —— V8 中的对象表示 ThornWu The best is yet to come 30 人赞同了该文章 本文创作于 2019-04-30,2019-12-20 迁移至此本 ...
- android中xml tools属性详解
第一部分 安卓开发中,在写布局代码的时候,ide可以看到布局的预览效果. 但是有些效果则必须在运行之后才能看见,比如这种情况:TextView在xml中没有设置任何字符,而是在activity中设置了 ...
随机推荐
- Ubuntu Linux处理Waiting for cache lock: Could not get lock /var/lib/dpkg/lock-frontend. It is held by process 3365 (unattended-upgr)问题
问题 在Ubuntu中,执行apt install后,出现以下问题: Waiting for cache lock: Could not get lock /var/lib/dpkg/lock-fro ...
- Acwing787.归并排序
Acwing787.归并排序 归并模板 归并排序,合二为一 题目链接:Acwing787.归并排序 #include<iostream> using namespace std; cons ...
- DevStream 成为 CNCF Sandbox 项目啦!- 锣鼓喧天、鞭炮齐鸣、红旗招展、忘词了。
开局两张图,内容全靠"编" 来,有图有真相! DevStream ️ CNCF DevStream joins CNCF Sandbox CNCF Cloud Native Int ...
- JavaScript中DOM查询封装函数
在JavaScript中可以通过BOM查询html文档中的元素,也就是所谓的在html中获取对象然后对它添加一个函数. 常用的方法有以下几种: ①document.getElementById() 通 ...
- SAP APO-PP / DS
在SAP APO中,使用生产计划/详细计划(Production Planning/Detailed Scheduling)生成满足生产要求的采购建议. 此组件还用于定义资源计划和订单明细. 您还可以 ...
- DNS原理&ssh
作用:实现域名的解析! www.baidu.com => 14.215.177.37 域名: www.baidu.com 实际域名为: www.baidu.com. 域名的解析,是反向的. 最后 ...
- 零基础学Python:元组(Tuple)详细教程
Python的元组与列表类似,不同之处在于元组的元素不能修改,元组使用小括号,列表使用方括号,元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可https://jq.qq.com/?_wv=1 ...
- docker下node环境搭建
初始化⼀个NodeJs程序 以下操作必须已经安装了NodeJS. ⾸先创建⼀个空⽂件夹.并创建以下⽂件: server.js package.json Dockerfile .dockerignore ...
- 初始化二维列表时使用[ [0]* N ] * K会出现的问题
声明二维列表使用[ [0]* N ] * K会出现的问题 初始化二维列表时使用[ [0]* N ] * K创建,外层列表的每一个元素地址相同: 创造了一个二维列表: 修改其中的一个元素a[1][1], ...
- 【python】下载中国大学MOOC的视频
[python]下载中国大学MOOC的视频 脚本目标: 输入课程id和cookie下载整个课程的视频文件,方便复习时候看 网站的反爬机制分析: 分析数据包的目的:找到获取m3u8文件的路径 1. 从第 ...