我用Python做了一个咖啡馆数据分析
在做案例前,我还想回答大家一个疑问,就是excel做数据分析可以实现Python一样的效果,那用Python的意义在哪呢?
经过这段时间学习理解,我的回答是: (https://jq.qq.com/?_wv=1027&k=gAwXvrat)
- 第一,在处理海量数据时,Python效率远高于excel。一般几万行的数据以上,excel基本就无能为力,很卡了。但是Python依然可以行云流水,效率高几十倍上百倍都有可能。
- 第二,Python的自动化水平非常高。你也许觉得excel的VBA一样可以自动化对不对?但是VBA有个致命弱点是,它只能基于excel内部进行自动化,其他方面就没办法了。比如你要对硬盘某些储存几百个的文件名称批量修改,VBA没办法,但Python实现起来很简单。
- 第三,Python是可以做算法模型的。Python语言可以让你搞懂一些最基础的算法原理,然后根据这些搭建一些算法模型,并通过matplotlib模块表现出来。.
下面我想通过一个咖啡公司的数据做一个简单的数据分析案例,从导入数据到最后形成图表,过一下整个流程,让大家知道,Python数据分析到底是怎么一回事。
— 1 —
准备数据 (https://jq.qq.com/?_wv=1027&k=gAwXvrat)
1、导入python数据分析模块三剑客:pandas\matplotlib\numpy
2、用read_excel()方法导入数据源
输出结果截图如下(部分):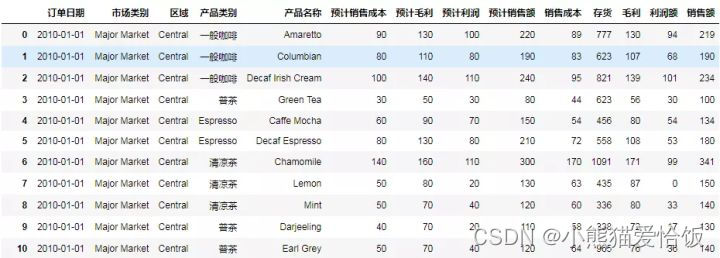
可以看到有这些数据:订单日期、市场类别、区域、产品类别、产品名称、预计销售成本、预计毛利、预计利润、预计销售额、销售成本、存货、毛利、利润额、销售额等等。
— 2 —
数据清洗 (https://jq.qq.com/?_wv=1027&k=gAwXvrat)
1、缺失值的处理
可以看到,这份数据很干净,没有空值。缺失值查询也可以用info()方法。
如果数据中有缺失值,我们可以用dropna()方法进行删除,或者用fillna()进行填充。
2、重复值处理很多数据都是有重复值的,这个在数据分析前必须删除掉,不然影响结果的准确度,清洗方法为drop_duplicates()。
结果显示,无重复。完了,我找的这个数据可能是别人已经清洗过的了,可能不需要我清洗了,打扰了。
— 3 —
数据分析
1、数据整体情况把握,用shape方法查看维度。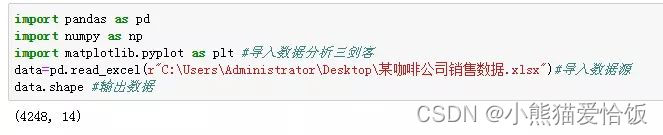
结果显示,这个数据有4248行,14列。
2、用describe()方法进行描述性分析
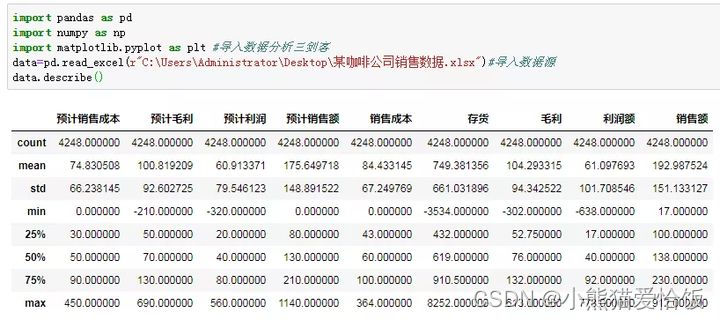
从这个步骤,想必你已经看出Python的强大之处了,一个小方法,瞬间可以查看各列数据的计数、平均数、极值、方差、4分位数等等。当然,如果你这样写:describe(include=‘all’),数据会更加详细。
3、排序分析比如我想看每个产品利润额从高到低的分析。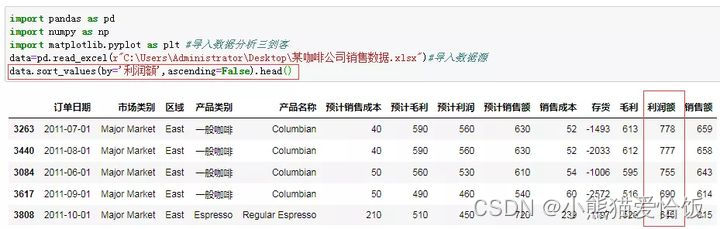
sort_values(by=‘利润额’)表示按利润额排序,ascending=False表示降序排序,head()数据太大了,所以我用这个函数默认取前5个数据。
4、数据分组(跟SQL中的分组一样)比如,我想看不同产品类别的利润额大小。

我用groupby()查看了利润额和销售额,根据肉眼,你一下估计看不出利润额哪个大对不对?那可以根据上面我介绍的排序知识来排序。
超快吧,要比excel方便对不对。
5、根据条件查询数据比如,我要看看哪些产品有负利润。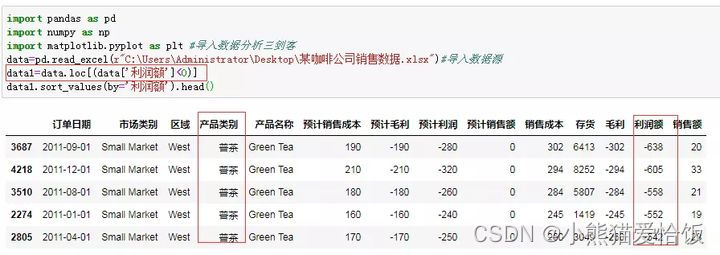
发现普洱茶的部分产品很多是亏本的。也许你想,如果我只想查询清凉茶的负利润产品呢?也可以的,在条件查询中多加个条件就好了。如图:
看到这里,你应该可以根据自己的分析需求运用条件格式畅所欲为了吧。是不是比excel嵌套会好用一点呢,关键excel如果碰到大数据嵌套会,人会很崩溃。比如我有次看到同事为了匹配数据一跑数据就是一两个小时。这在Python里是分分钟的事。
6、条件复杂一点分析(透视表)比如,我要看看不同区域清凉茶的利润额和销售额的求和、平均值、极值呢?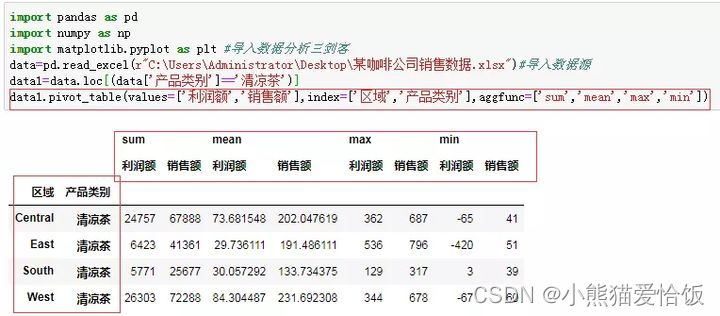
这就需要用到上图展示中的pivot_table(),这就是透视表功能。这个功能可以让你实现各种复杂分析。但需要熟练。
7、增加一列,算利润率比如我要算利润率,那么我就得用利润额除以销售额,再换成百分比对不对?如图:
先算出利润率,这时候是一个小数,那么我们得想办法把小数转化为百分数,而且需要添加到表格里去。这时候就要用到lambda匿名函数了、格式化函数format、以及聚合函数apply了。
到此为止,我把我们日常数据分析的基本流程和分析方法演示了一遍了。接下来开始最后一个模块。
— 4 —
数据可视化
Python的图表功能也很强大,可以有各种组合形式,然后图表如果设置格式的话,可以制作得很专业且清晰,因此很多商业图表制图,都会借助Python。下面我只会简单展示,因为复杂的东西我目前也没办法随心所欲做出来,虽然我知道方法。
1、各产品种类利润额的图
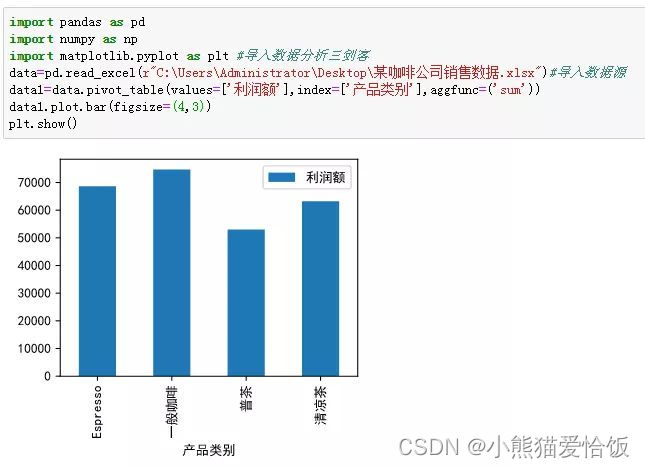
2、查看各种产品的利润额分布在哪些区间
这是一个简单箱式图能看出极值、特殊值、4分位值,中位数等等。
3、雷达图这个就我随便画一个了,没时间根据这个数据来做了,现在凌晨1点半,要睡了。

以上,就是整理出来的用Python进行数据分析的全过程。
如果大家熟练了,就可以在这个基础上玩出各种花样了。我将在接下来的时间里,继续做一些分析案例,希望能分享一些比较容易上手,又能符合数据分析行业实际工作的东西出来。
大家有更好的方法和案例,也可以一起共享,共同学习进步。
备注:Python学习并不难,但是需要坚持,我正式学是从今年3月23日开始的,到现在不到5个月。当然Python有很多方向,比如web开发、数据分析与科学计算、爬虫、数据挖掘与机器学习、算法人工智能等等,我只是选择了数据分析方向。
END
我用Python做了一个咖啡馆数据分析的更多相关文章
- 这几天有django和python做了一个多用户博客系统(可选择模板)
这几天有django和python做了一个多用户博客系统(可选择模板) 没完成,先分享下 断断续续2周时间吧,用django做了一个多用户博客系统,现在还没有做完,做分享下,以后等完善了再慢慢说 做的 ...
- 1.2 Why Python for Data Analysis(为什么使用Python做数据分析)
1.2 Why Python for Data Analysis?(为什么使用Python做数据分析) 这节我就不进行过多介绍了,Python近几年的发展势头是有目共睹的,尤其是在科学计算,数据处理, ...
- 用Python做一个知乎沙雕问题总结
用Python做一个知乎沙雕问题总结 松鼠爱吃饼干2020-04-01 13:40 前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以 ...
- 做为一个Python程序员的基本素养
今天在学习的过程中,明白了一些不是Python标准所必须要做的事情,二是做为一个合格的Python程序员应该所遵从的一些规范 分享给大家,有不足的地方请大家指正,此下是我学习的一点心得: 1.在给变量 ...
- 使用python做一个IRC在线下载器
使用python做一个IRC在线下载器 1.开发流程 2.软件流程 3.开始 3.0 准备工作 3.1寻找API接口 3.2 文件模块 3.2.1 选择文件弹窗 3.2.2 提取文件名 3.2.2.1 ...
- 使用python做科学计算
这里总结一个guide,主要针对刚开始做数据挖掘和数据分析的同学 说道统计分析工具你一定想到像excel,spss,sas,matlab以及R语言.R语言是这里面比较火的,它的强项是强大的绘图功能以及 ...
- 一步一步教你如何用Python做词云
前言 在大数据时代,你竟然会在网上看到的词云,例如这样的. 看到之后你是什么感觉?想不想自己做一个? 如果你的答案是正确的,那就不要拖延了,现在我们就开始,做一个词云分析图,Python是一个当下很流 ...
- What exactly can you do with Python? Here are Python’s 3 main applications._你能用Python做什么?下面是Python的3个主要应用程序。
原文链接 Github地址 一.陈述 1,我到底能用Python做什么? 我观察注意到Python三个主要流行的应用: 网站开发: 数据科学——包括机器学习,数据分析和数据可视化: 做脚本语言. 二. ...
- 你用 Python 做过什么有趣的数据挖掘项目?
有网友在知乎提问:「你用 Python 做过什么有趣的数据挖掘项目?」 我最近刚开始学习 Python, numpy, scipy 等, 想做一些数据方面的项目,但是之前又没有这方面的经验.所以想知道 ...
随机推荐
- 2022.02.27 CF811E Vladik and Entertaining Flags
2022.02.27 CF811E Vladik and Entertaining Flags https://www.luogu.com.cn/problem/CF811E Step 1 题意 在一 ...
- 使用 .net + blazor 做一个 kubernetes 开源文件系统
背景 据我所知,目前 kubernetes 本身或者其它第三方社区都没提供 kubernetes 的文件系统.也就是说要从 kubernetes 的容器中下载或上传文件,需要先进入容器查看目录结构,然 ...
- 新作!分布式系统韧性架构压舱石OpenChaos
摘要:本文首先以现今分布式系统的复杂性和稳定性的需求引出混沌工程概念,并阐述了OpenChaos在传统混沌工程上的优化与创新. 背景 随着Serverless,微服务(含服务网格)与越来越多的容器化架 ...
- 项目完成小结 - Django3.x版本 - 开发部署小结 (2)
前言 好久没更新博客了,最近依然是在做之前博客说的这个项目:项目完成 - 基于Django3.x版本 - 开发部署小结 这项目因为前期工作出了问题,需求没确定好,导致了现在要做很多麻烦的工作,搞得大家 ...
- 152. Maximum Product Subarray - LeetCode
Question 152. Maximum Product Subarray Solution 题目大意:求数列中连续子序列的最大连乘积 思路:动态规划实现,现在动态规划理解的还不透,照着公式往上套的 ...
- Windows 程序安装与更新方案: Clowd.Squirrel
我的Notion Clowd.Squirrel Squirrel.Windows 是一组工具和适用于.Net的库,用于管理 Desktop Windows 应用程序的安装和更新. Squirrel.W ...
- 【单片机】NB-IoT移远BC28调试笔记
一.入网总体思路 入网思路是参考 <Quectel_BC95&BC35-G&BC28_应用设计指导_V1.1.pdf>来做的.流程如图所示: 二.具体调试细节3.1 AT+ ...
- Spark: 单词计数(Word Count)的MapReduce实现(Java/Python)
1 导引 我们在博客<Hadoop: 单词计数(Word Count)的MapReduce实现 >中学习了如何用Hadoop-MapReduce实现单词计数,现在我们来看如何用Spark来 ...
- 解读ICDE'22论文:基于鲁棒和可解释自编码器的无监督时间序列离群点检测算法
摘要:本文提出了两个用于无监督的具备可解释性和鲁棒性时间序列离群点检测的自动编码器框架. 本文分享自华为云社区<解读ICDE'22论文:基于鲁棒和可解释自编码器的无监督时间序列离群点检测算法&g ...
- LC T668笔记 & 有关二分查找、第K小数、BFPRT算法
LC T668笔记 [涉及知识:二分查找.第K小数.BFPRT算法] [以下内容仅为本人在做题学习中的所感所想,本人水平有限目前尚处学习阶段,如有错误及不妥之处还请各位大佬指正,请谅解,谢谢!] !! ...