1.5.5 HDFS读写解析-hadoop-最全最完整的保姆级的java大数据学习资料
1.5.5 HDFS读写解析
1.5.5.1 HDFS读数据流程
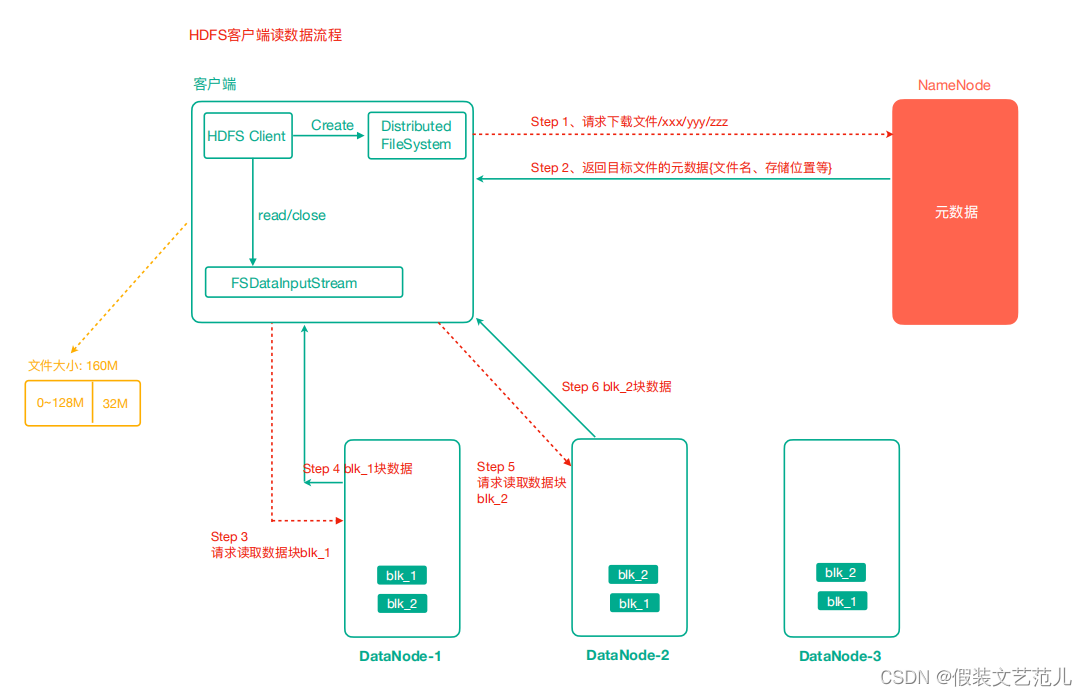
- 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据, 找到文件块所在的DataNode地址。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
1.5.5.2 HDFS写数据流程
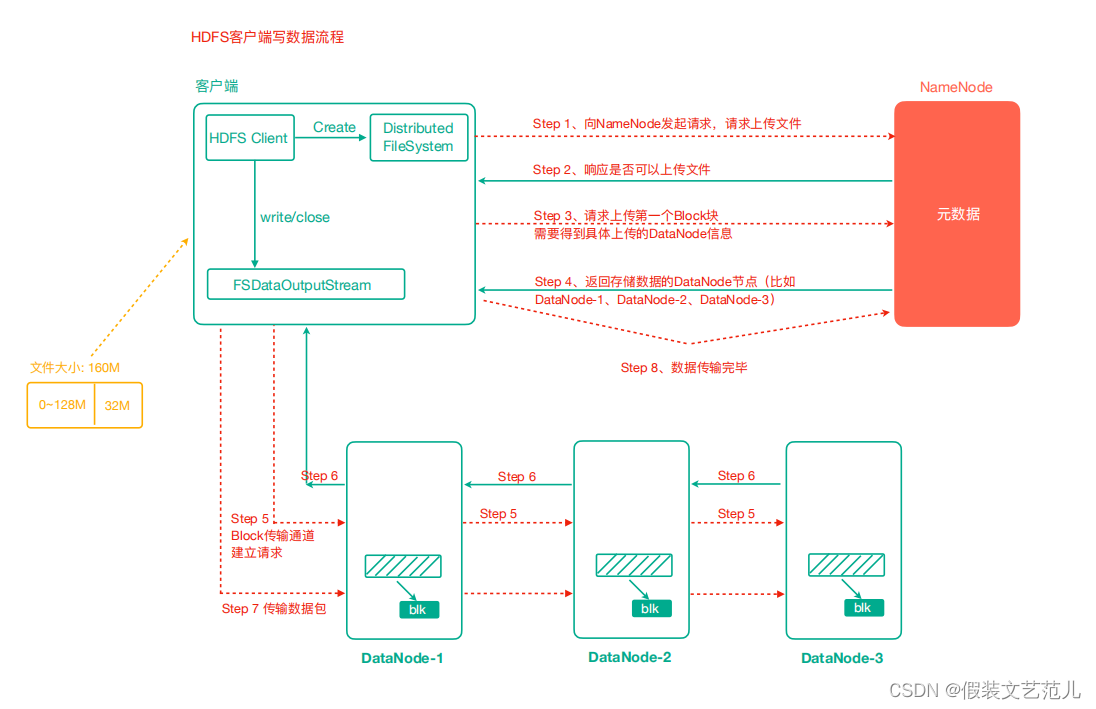
客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
NameNode返回是否可以上传。
客户端请求第一个 Block上传到哪几个DataNode服务器上。
NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
dn1、dn2、dn3逐级应答客户端。
客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个确认队列等待确认。
当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行 3-7步)。
验证Packet代码
@Test
public void testUploadPacket() throws IOException {
//1 准备读取本地文件的输入流
final FileInputStream in = new FileInputStream(new File("e:/lagou.txt"));
//2 准备好写出数据到hdfs的输出流
final FSDataOutputStream out = fs.create(new Path("/lagou.txt"), new Progressable() {
public void progress () { //这个progress方法就是每传输64KB(packet)就会执行一次,
System.out.println("&");
}
});
//3 实现流拷贝
IOUtils.copyBytes(in, out, configuration); //默认关闭流选项是true,所以会自动 关闭
//4 关流 可以再次关闭也可以不关了
}
1.5.5 HDFS读写解析-hadoop-最全最完整的保姆级的java大数据学习资料的更多相关文章
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习之路之Hadoop
Hadoop介绍 一.简介 Hadoop是一个开源的分布式计算平台,用于存储大数据,并使用MapReduce来处理.Hadoop擅长于存储各种格式的庞大的数据,任意的格式甚至非结构化的处理.两个核心: ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- 大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一: package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream ...
- 大数据学习-2 认识Hadoop
一.什么是Hadoop? Hadoop可以简单的理解为一个数据存储和数据分析分布式系统.随着互联网的普及产生的数据是非常的庞大的,那么我们怎么去处理这么大量的数据呢?传统的单一计算机肯定是完成不了的, ...
随机推荐
- linux系统下查看某个进程内存使用量
- 基于Alpine镜像定制自己的工具箱
Alpine介绍 Alpine 操作系统是一个面向安全的轻型 Linux 发行版.目前 Docker 官方已开始推荐使用 Alpine 替代之前的 Ubuntu 做为基础镜像环境.这样会带来多个好处. ...
- Beats:使用 Filebeat 导入 JSON 格式的日志文件
转载自:https://blog.csdn.net/UbuntuTouch/article/details/108504014 在今天的文章中,我来用另外的一种方式来展示如何导入一个 JSON 格式的 ...
- [笔记] 一种快速求 1 ~ n 逆元的方法
我们现在要求1~n在mod m意义下的逆元(n<m,m为素数). 对于一个[1,n]中的数i,我们令\(k=\lfloor\frac{m}{i}\rfloor,r=m \ mod \ i\) 然 ...
- Hbase之命令
Hbase之命令 -- 查询数据量 hbase org.apache.hadoop.hbase.mapreduce.RowCounter '{namespaceName:tablename}' cou ...
- JSP脚本知识
JSP脚本元素 1.在jsp中嵌入的服务端运行的小程序称为脚本.实质是java程序. 2.脚本元素可以分为三类:表达式.Scriptlet.声明. 表达式 计算java表达式的值,得到的结果转化为字符 ...
- 驱动开发:内核枚举Registry注册表回调
在笔者上一篇文章<驱动开发:内核枚举LoadImage映像回调>中LyShark教大家实现了枚举系统回调中的LoadImage通知消息,本章将实现对Registry注册表通知消息的枚举,与 ...
- Aspose.Words 操作 Word 画 EChart 图
使用 Aspose.Words 插件在 Word 画 EChart 图 使用此插件可以画出丰富的 EChart 图,API 参考 https://reference.aspose.com/words/ ...
- iOS开发之自定义日历控件
前言 日常开发中经常会遇到日期选择,为了方便使用,简单封装了一个日历控件,在此抛砖引玉供大家参考. 效果 功能 支持单选.区间 支持默认选中日期 支持限制月份 支持过去.当前.未来模式 支持frame ...
- 5.websocket原理
websocket协议原理 1.WebSocket协议是基于TCP的一种新的协议.WebSocket最初在HTML5规范中被引用为TCP连接,作为基于TCP的套接字API的占位符.它实现了浏览器与 ...