1.5.5 HDFS读写解析-hadoop-最全最完整的保姆级的java大数据学习资料
1.5.5 HDFS读写解析
1.5.5.1 HDFS读数据流程
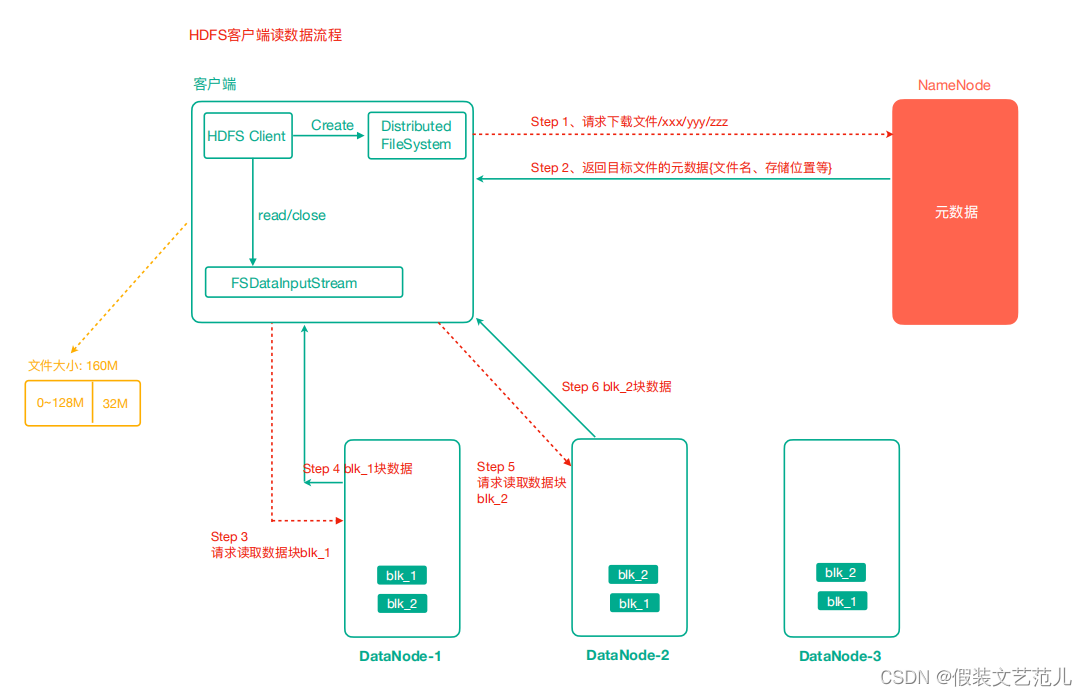
- 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据, 找到文件块所在的DataNode地址。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
1.5.5.2 HDFS写数据流程
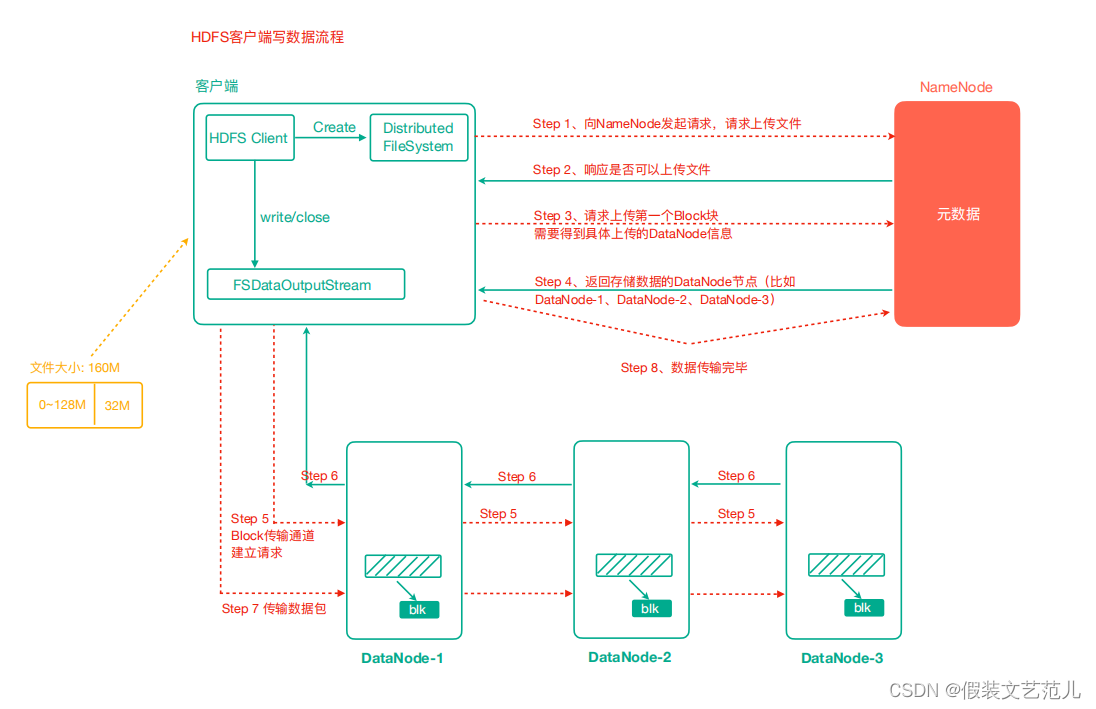
客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
NameNode返回是否可以上传。
客户端请求第一个 Block上传到哪几个DataNode服务器上。
NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
dn1、dn2、dn3逐级应答客户端。
客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个确认队列等待确认。
当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行 3-7步)。
验证Packet代码
@Test
public void testUploadPacket() throws IOException {
//1 准备读取本地文件的输入流
final FileInputStream in = new FileInputStream(new File("e:/lagou.txt"));
//2 准备好写出数据到hdfs的输出流
final FSDataOutputStream out = fs.create(new Path("/lagou.txt"), new Progressable() {
public void progress () { //这个progress方法就是每传输64KB(packet)就会执行一次,
System.out.println("&");
}
});
//3 实现流拷贝
IOUtils.copyBytes(in, out, configuration); //默认关闭流选项是true,所以会自动 关闭
//4 关流 可以再次关闭也可以不关了
}
1.5.5 HDFS读写解析-hadoop-最全最完整的保姆级的java大数据学习资料的更多相关文章
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习之路之Hadoop
Hadoop介绍 一.简介 Hadoop是一个开源的分布式计算平台,用于存储大数据,并使用MapReduce来处理.Hadoop擅长于存储各种格式的庞大的数据,任意的格式甚至非结构化的处理.两个核心: ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- 大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一: package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream ...
- 大数据学习-2 认识Hadoop
一.什么是Hadoop? Hadoop可以简单的理解为一个数据存储和数据分析分布式系统.随着互联网的普及产生的数据是非常的庞大的,那么我们怎么去处理这么大量的数据呢?传统的单一计算机肯定是完成不了的, ...
随机推荐
- 获取Docker容器名称和ID
docker ps --format "{{.Names}}" docker ps -q
- 普通用户使用CI/CD权限使用
根据文章:授权用户访问名称空间 (https://www.cnblogs.com/sanduzxcvbnm/p/15015576.html) 进行有关操作后,普通用户点击 会报错如下信息: 解决办法: ...
- Elasticsearch索引生命周期管理探索
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484130&idx=1&sn=454f199 ...
- androidmanifest.xml 反编译
androidmanifest.xml 反编译 去除更新只修改androidmanifest.xml内容 解压apk文件后得到这个文件androidmanifest.xml windwos安装java ...
- 【Java8新特性】- Lambda表达式
Java8新特性 - Lambda表达式 生命不息,写作不止 继续踏上学习之路,学之分享笔记 总有一天我也能像各位大佬一样 一个有梦有戏的人 @怒放吧德德 分享学习心得,欢迎指正,大家一起学习成长! ...
- 关于for循环当中发生强制类型转换的问题
Map map1 = new HashMap(); Map map2 = new HashMap(); Map map3 = new HashMap(); List<Map> list = ...
- Tableau Server注册安装及配置详细教程
Tableau Server注册安装及配置详细教程 本文讲解的是 Tableau Server 10.0 版本的安装及配置 这里分享的 TableauServer 安装版本为64位的10.0版本Ser ...
- 驱动开发:内核枚举DpcTimer定时器
在笔者上一篇文章<驱动开发:内核枚举IoTimer定时器>中我们通过IoInitializeTimer这个API函数为跳板,向下扫描特征码获取到了IopTimerQueueHead也就是I ...
- KTV和泛型(3)
泛型除了KTV,还有一个让人比较疑惑的玩意,而且它就是用来表达疑惑的:? 虽然通过泛型已经达到我们想要的效果了,例如: List<String> list = new ArrayList& ...
- NVIDIA Isaac Gym安装与使用
NVIDIA做的Isaac Gym,个人理解就是一个类似于openai的Gym,不过把环境的模拟这个部分扔到了GPU上进行,这样可以提升RL训练的速度. 官网:https://developer.nv ...