ORM执行sql语句 双下划线 外键字段创建 ORM跨表查询
模型层之ORM执行SQL语句
有时候ORM的操作效率可能偏低 我们是可以自己编写SQL的
如何在django中使用原生SQL?
方式1一
使用pymysql模块
方式二
raw查询关键字主要是对应sql里select查
使用for循环才能打印,raw方法查询到的数据值:
models.User.objects.raw('select * from app01_user;')
使用query方法查看SQL:

方式三
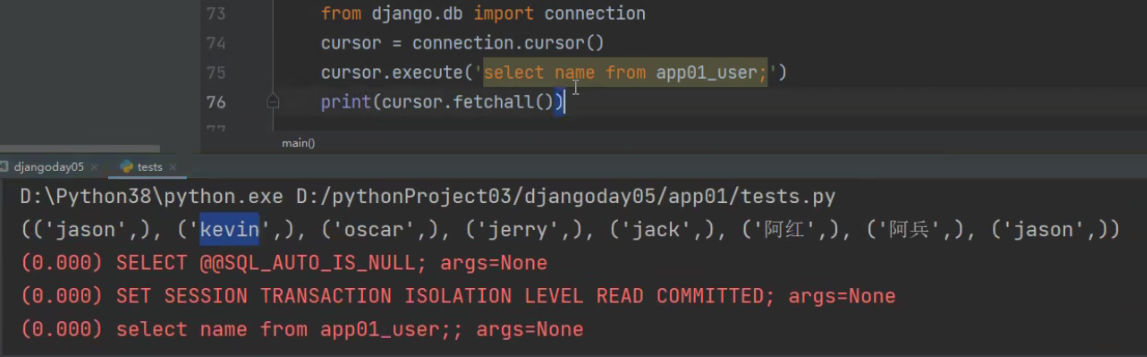
from django.db import connection
cursor = connection.cursor()
cursor.execute('select name from app01_user;')
print(cursor.fetchall())
神奇的双下划线查询
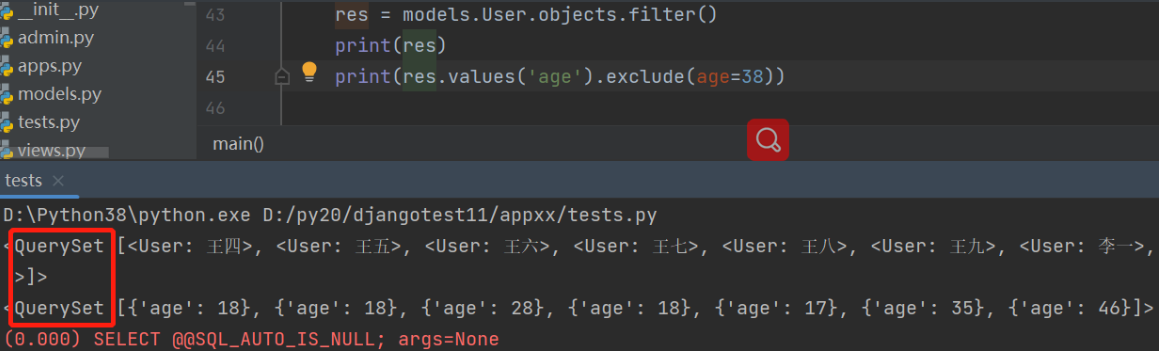
只要我们拿到的是queryset对象就可以无限制的点queryset对象的方法
''' queryset.filter().values().filter().values_list().filter()...
'''
表数据:
大于 小于
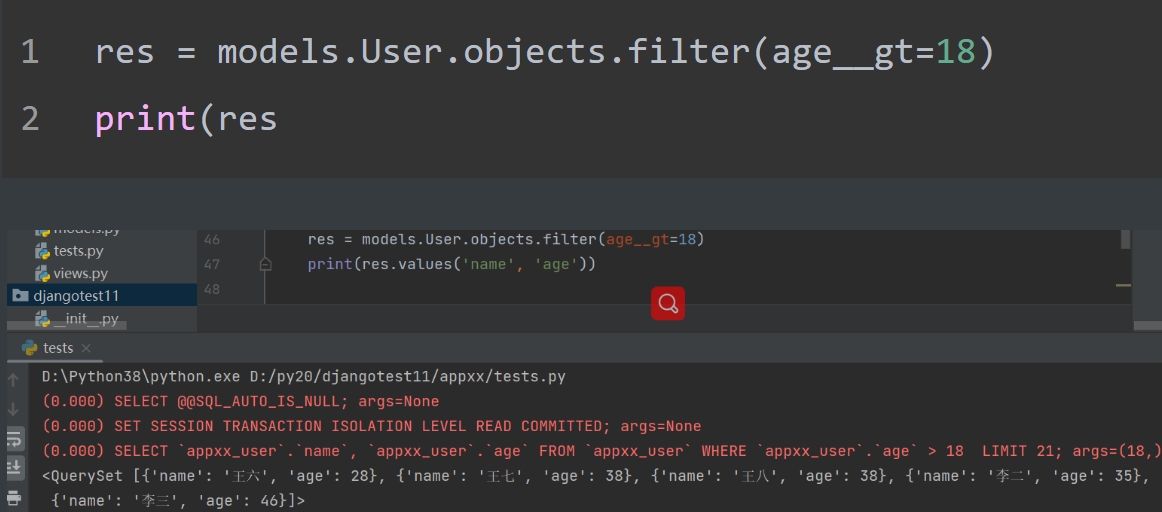
查询年龄大于18的用户数据:
res = models.User.objects.filter(age__gt=18)
print(res
注意:这里的age是user表内的一个字段名
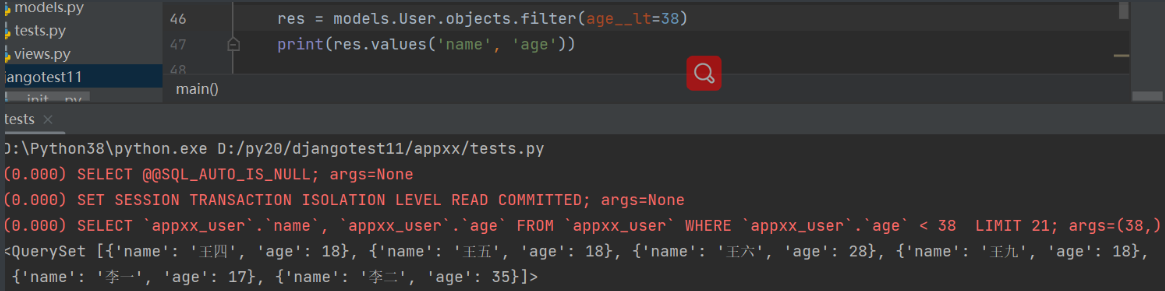
查询小于年龄38的用户数据:
res = models.User.objects.filter(age__lt=38)
print(res)
大于等于 小于等于
res = models.User.objects.filter(age__gte=18)
res = models.User.objects.filter(age__lte=38)
类似于成员运算
查询年龄是18或者28或者38的数据
res = models.User.objects.filter(age__in=(18, 28, 38))
print(res)
查询年龄在18到38范围之内的数据
相当于原生SQL中的between
res = models.User.objects.filter(age__range=(18, 38))
print(res)
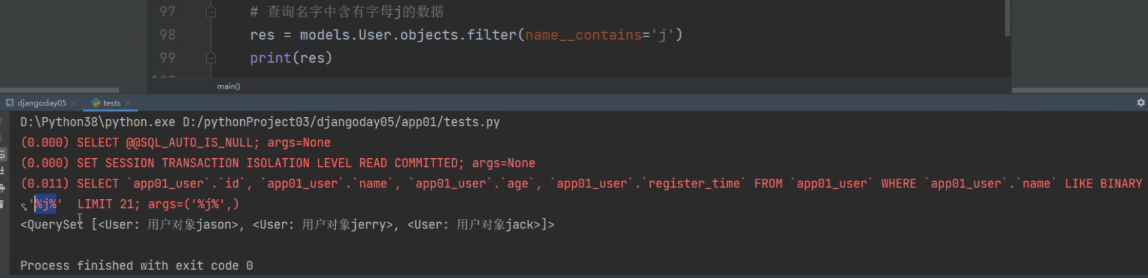
查询名字中含有字母j的数据
相当于原生SQL中的模糊查询(like
但这里是区分大小写的:
区分大小写
res = models.User.objects.filter(name__contains='j') #
print(res)
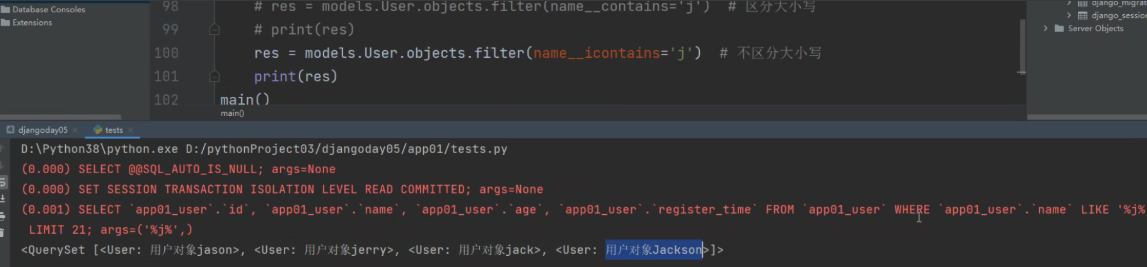
不区分大小写
res = models.User.objects.filter(name__icontains='j')
print(res)
查询注册年份是2022的数据
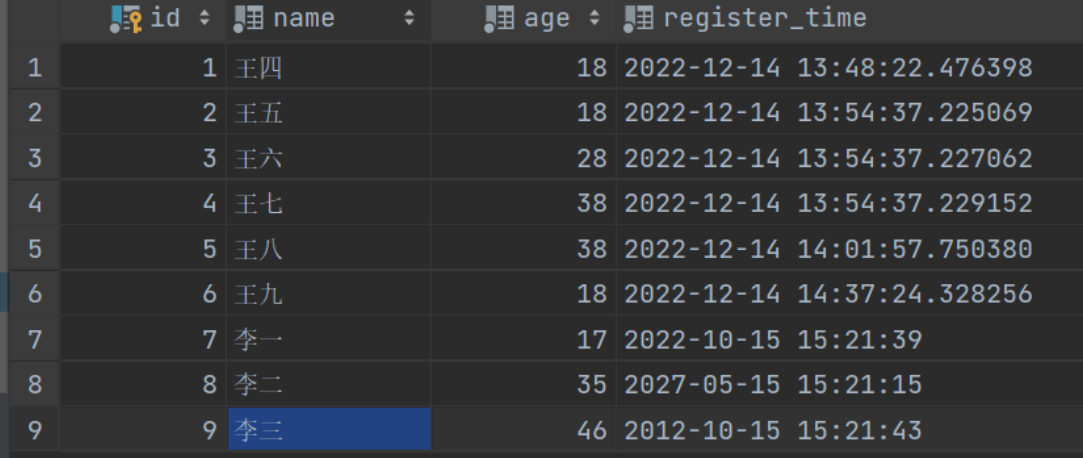
看我我们的数据表中:
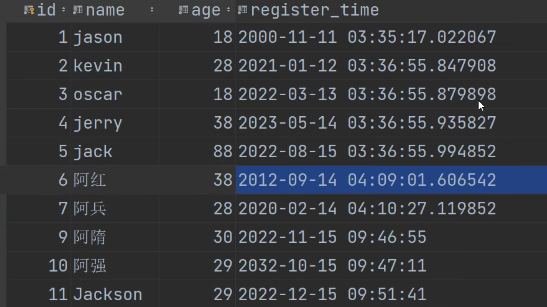
要从中查询出是2022年的数据(只按年份筛选)
res = models.User.objects.filter(register_time__year=2022)
print(res)
注意:register_time是User表的字段名
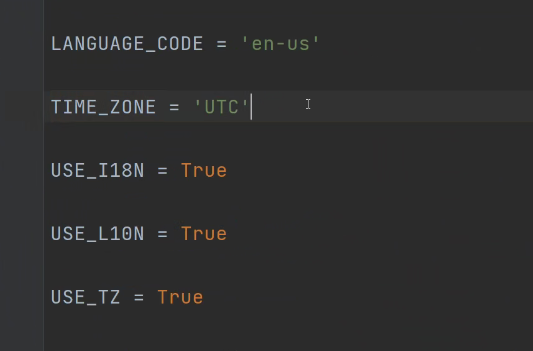
针对Django框架的时区问题 是需要配置文件中修改的 后续在bbs会给讲解

按照时间字段筛选数据的方式有很多
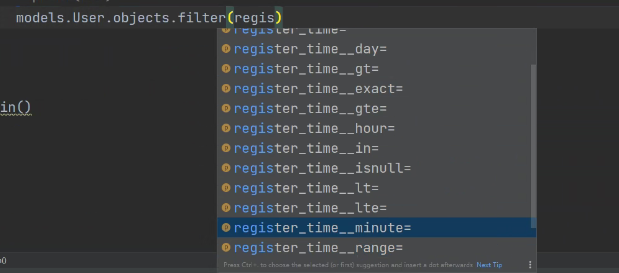
但都得要更改配置文件 后续会讲
要在setting配一下 TIME_ZONE
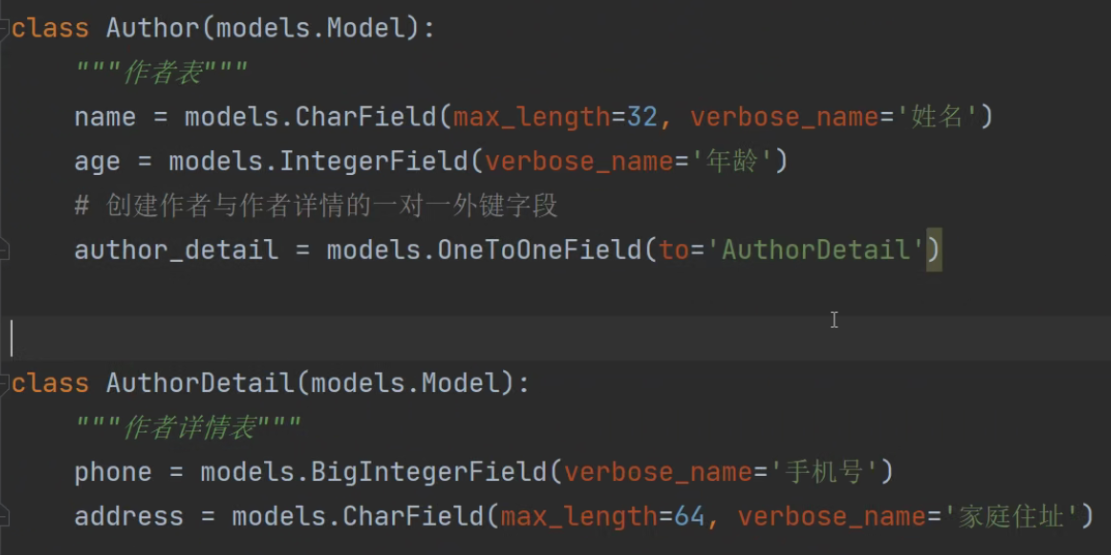
ORM外键字段的创建
'''
复习MySQL外键关系
一对多
外键字段建在多的一方
多对多
外键字段统一建在第三张关系表
一对一
建在任何一方都可以 但是建议建在查询频率较高的表中
ps:关系的判断可以采用换位思考原则 熟练的之后可以瞬间判断
```
1.创建基础表
(书籍表、出版社表、作者表、作者详情)
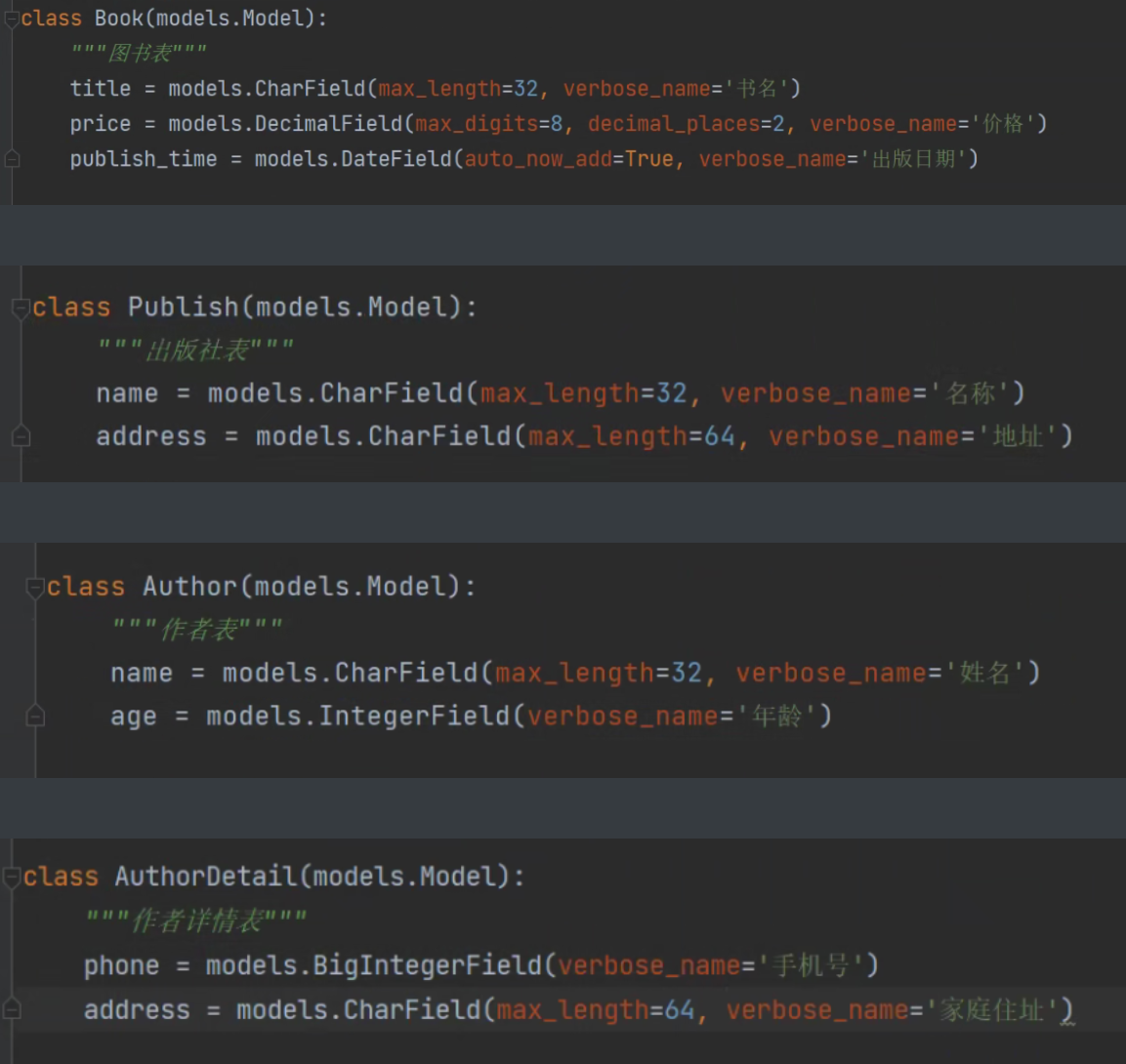
2.确定外键关系
书籍表与出版社表(一对多)
一对多
ORM与MySQL一致 外键字段建在多的一方
书籍与出版社是一对多关系。
一对多 ORM与MySQL一致。
外键字段建在多的一方,也就是建立在书籍表
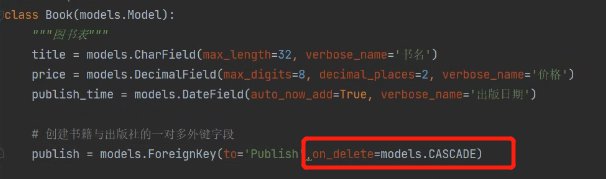
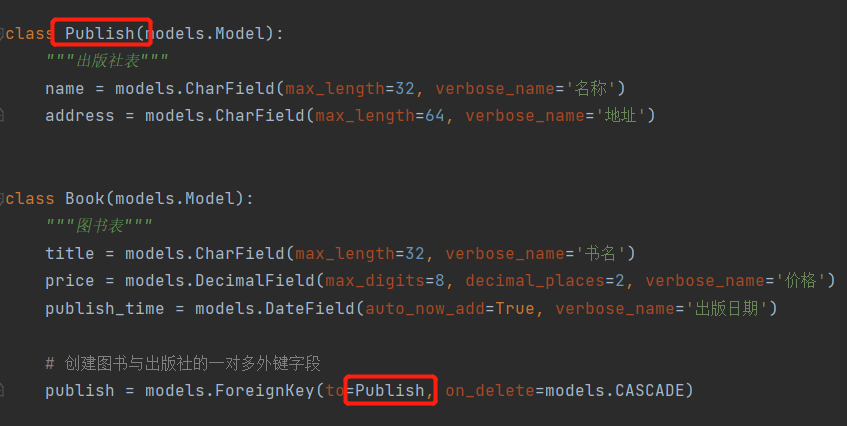
ForeignKey:创建一对多外键。
to:这里的to相当于原生SQL的reference。也就是在book表创建一个publish字段 关联publish表的主键。to后面也可以传一个出版社类,这样ORM也会知道你这个外键字段是要跟这个类绑定,只不过这个列就必须写在to所在类的上面
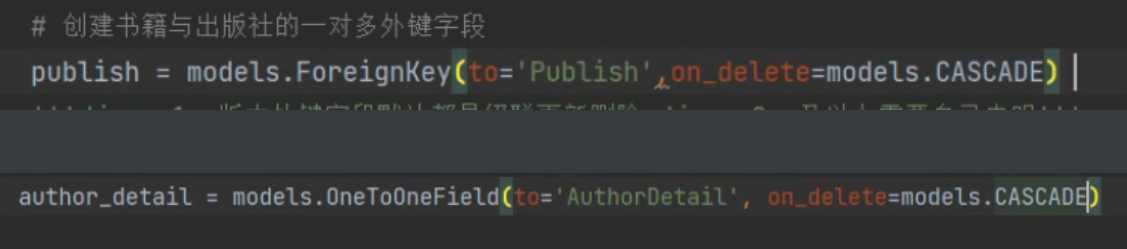
on_delete:这里的表示的是级联删除,级联更新。注意有如下版本区别:
django1.x版本:所有外键字段默认都是级联更新级联删除
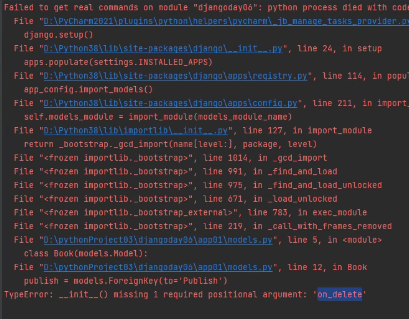
django2.x版本:需要自己声明。也就是添加on_delete=models.CASCADE
如果不申明会报错:
这里还需要注意:
针对外键一对多和一对一同步到表中之后会自动加_id的后缀
publish = models.ForeignKey(to='Publish',on_delete=models.CASCADE)
author_detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE)
如我们创的外键字段是:
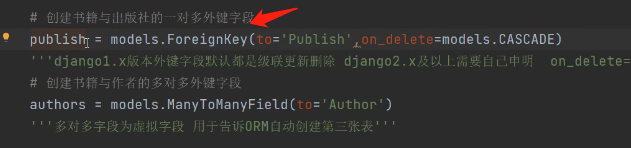
到表中显示的字段都会自己添加后缀_id

多对多
书籍表与作者表是多对多关系。
这里建议把外键建立在查询频率较高的书籍表。
在书籍表创建多对多外键字段,使用ManyToManyField方法
ORM比MySQL有更多变化
1.外键字段可以直接建在某张表中(查询频率较高的)内部会自动帮你创建第三张关系表
2.自己创建第三张关系表并创建外键字段 详情后面会讲
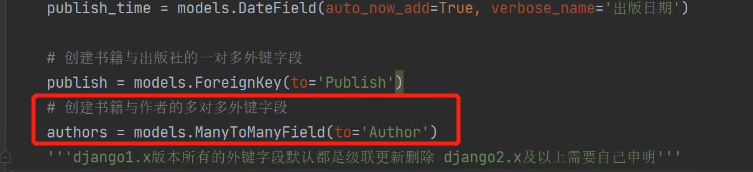
多对多字段为虚拟字段,会告诉Mysql自动创建第三张表,他不会在自己所处的表Book,创建一个新字段author。
除了这种使用虚拟字段创第三张表的方式,还可以自己手动在书籍库创第三张表。且自己手动创也具备一定优势
一对一
ORM与MySQL一致 外键字段建在查询较高的一方
由于作者表访问次数较多,所以我们在作者表创建一对一外键字段,使用OneToOneField
3.表的查看

所以针对一对多和一对一得申明
如果没就报错:
针对一对多和一对一同步到表中之后会自动加_id的后缀
publish = models.ForeignKey(to='Publish',on_delete=models.CASCADE)
author_detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE)
针对多对多 不会在表中有展示 而是创建第三张表 用于告诉ORM自动创建第三张表
authors = models.ManyToManyField(to='Author')
自动创建了书跟作者的表
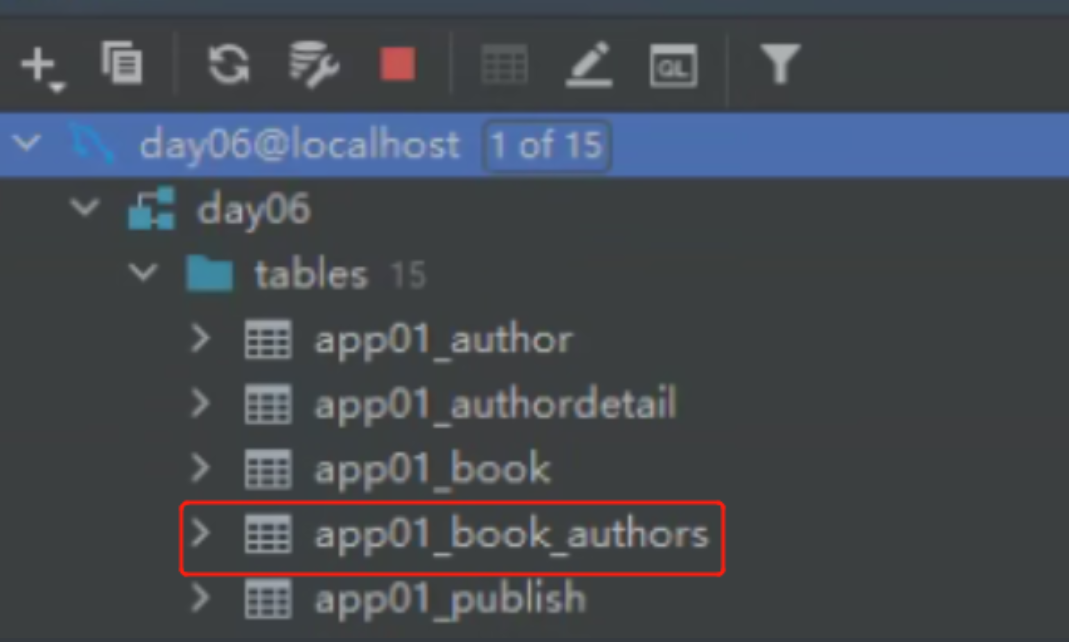
上面的蓝色表示外键字段。可见里面有两个是外键相关联字段
数据的录入
表的录入顺序:先从没有外键字段的表开始填 除了book表不录 其他表都可以录
作者详情表 --- > 作者表
出版社 ---> 图书表
要先给作者详情表添加数据,再给作者表添加数据。
先给出版社表添加数据,再给图书表添加数据
因为当有外键字段 基表相关联的表数据还未创建出来数据是无法录入的
外键字段相关操作
针对一对多
插入数据可以直接填写表中的实际字段
# models.Book.objects.create(title='三国演义', price=888.88, publish_id=1)
# models.Book.objects.create(title='人性的弱点', price=777.55, publish_id=1)
插入数据也可以填写表中的类中字段名
# publish_obj = models.Publish.objects.filter(pk=1).first()
# models.Book.objects.create(title='水浒传', price=555.66, publish=publish_obj)
'''一对一与一对多 也一致'''
既可以传数字也可以传对象
针对多对多关系绑定
多对多关系表models是点不出来的 ORM自动创的
需要获取出含有多对多字段的数据就可以了
# book_obj = models.Book.objects.filter(pk=1).first()
# book_obj.authors.add(1) # 在第三张关系表中给当前书籍绑定作者
# book_obj.authors.add(2, 3)
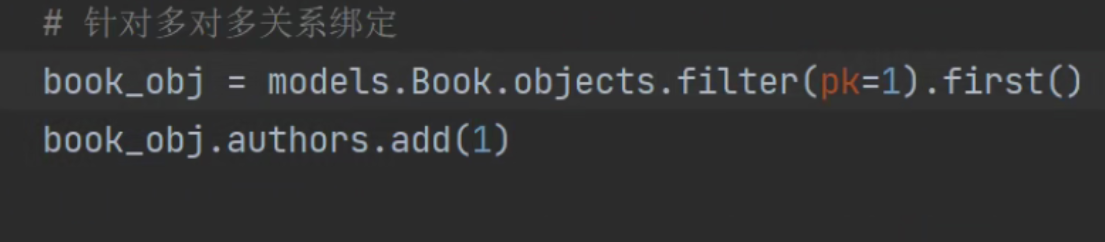
# book_obj = models.Book.objects.filter(pk=4).first()
# author_obj1 = models.Author.objects.filter(pk=1).first()
# author_obj2 = models.Author.objects.filter(pk=2).first()
# book_obj.authors.add(author_obj1)
# book_obj.authors.add(author_obj1, author_obj2)
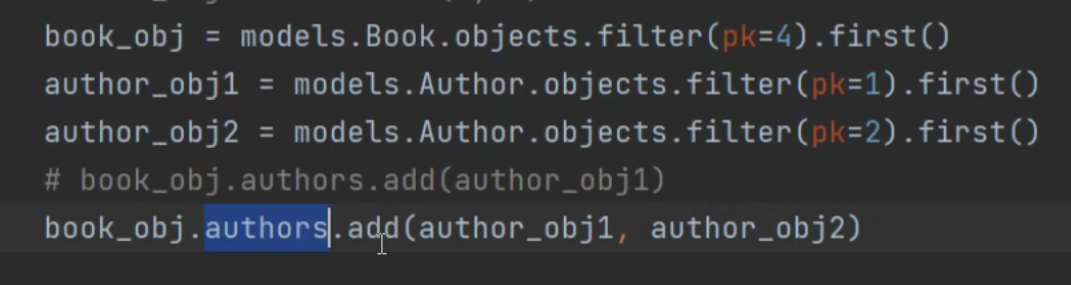
修改关系
book_obj = models.Book.objects.filter(pk=1).first()
# book_obj.authors.set((1, 3)) # 修改关系
得传元组或列表 能够支持for循环
# book_obj.authors.set([2, ]) # 修改关系
# author_obj1 = models.Author.objects.filter(pk=1).first()
# author_obj2 = models.Author.objects.filter(pk=2).first()
# book_obj.authors.set((author_obj1,))
# book_obj.authors.set((author_obj1, author_obj2))
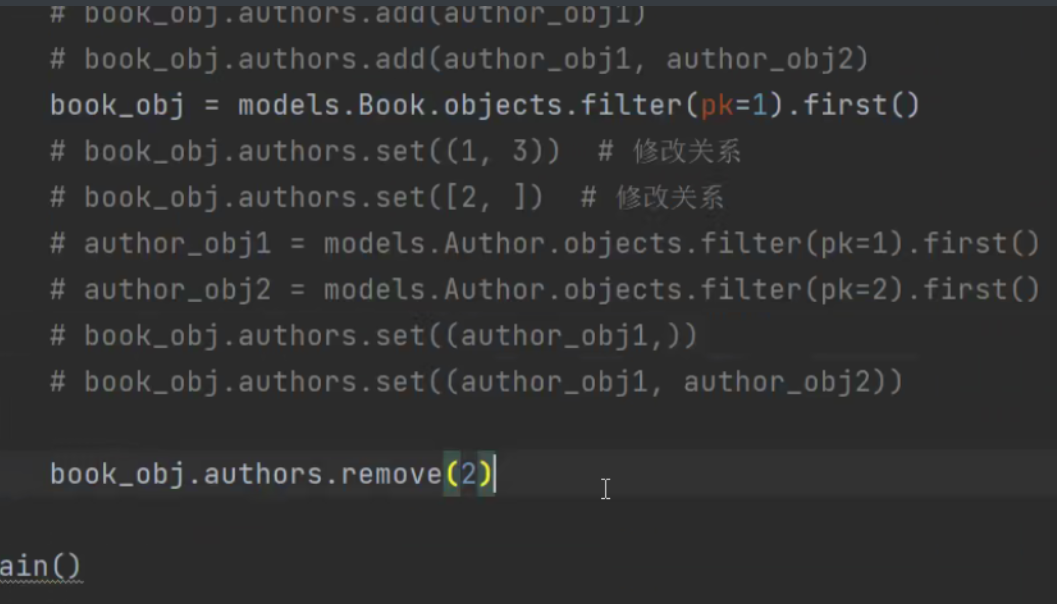
删除:
# book_obj.authors.remove(2)
# book_obj.authors.remove(1, 3)
# book_obj.authors.remove(author_obj1,)
# book_obj.authors.remove(author_obj1,author_obj2)
清除
book_obj.authors.clear()
add()\remove() 多个位置参数(数字 对象)
set() 可迭代对象(元组 列表) 数字 对象
clear() 情况当前数据对象的关系
ORM跨表查询
"""
复习MySQL跨表查询的思路
子查询
分步操作:将一条SQL语句用括号括起来当做另外一条SQL语句的条件
连表操作
先整合多张表之后基于单表查询即可
inner join 内连接
left join 左连接
right join 右连接
"""
正反向查询的概念(重要)
正向查询
由外键字段所在的表数据查询关联的表数据 正向
ps:正反向的核心就看外键字段在不在当前数据所在的表中
反向查询
没有外键字段的表数据查询关联的表数据 反向
ORM跨表查询的口诀(重要)
正向查询按外键字段
反向查询按表名小写
基于对象的跨表查询
1.查询主键为1的书籍对应的出版社名称
# 先根据条件获取数据对象
# book_obj = models.Book.objects.filter(pk=1).first()
# 再判断正反向的概念 由书查出版社 外键字段在书所在的表中 所以是正向查询
# print(book_obj.publish.name)
2.查询主键为4的书籍对应的作者姓名
# 先根据条件获取数据对象
# book_obj = models.Book.objects.filter(pk=4).first()
# 再判断正反向的概念 由书查作者 外键字段在书所在的表中 所以是正向查询
# print(book_obj.authors) # app01.Author.None
# print(book_obj.authors.all())
# print(book_obj.authors.all().values('name'))
3.查询jason的电话号码
author_obj = models.Author.objects.filter(name='jason').first()
print(author_obj.author_detail.phone)
4.查询北方出版社出版过的书籍
publish_obj = models.Publish.objects.filter(name='北方出版社').first()
print(publish_obj.book_set) # app01.Book.None
print(publish_obj.book_set.all())
5.查询jason写过的书籍
author_obj = models.Author.objects.filter(name='jason').first()
print(author_obj.book_set) # app01.Book.None
print(author_obj.book_set.all())
6.查询电话号码是110的作者姓名
author_detail_obj = models.AuthorDetail.objects.filter(phone=110).first()
print(author_detail_obj.author)
print(author_detail_obj.author.name)
基于上下划线的跨表查询
基于双下划线的跨表查询
# 1.查询主键为1的书籍对应的出版社名称
# res = models.Book.objects.filter(pk=1).values('publish__name','title')
# print(res)
# 2.查询主键为4的书籍对应的作者姓名
# res = models.Book.objects.filter(pk=4).values('title', 'authors__name')
# print(res)
# 3.查询jason的电话号码
# res = models.Author.objects.filter(name='jason').values('author_detail__phone')
# print(res)
# 4.查询北方出版社出版过的书籍名称和价格
# res = models.Publish.objects.filter(name='北方出版社').values('book__title','book__price','name')
# print(res)
# 5.查询jason写过的书籍名称
# res = models.Author.objects.filter(name='jason').values('book__title', 'name')
# print(res)
# 6.查询电话号码是110的作者姓名
res = models.AuthorDetail.objects.filter(phone=110).values('phone', 'author__name')
print(res)
进阶操作
# 1.查询主键为1的书籍对应的出版社名称
# res = models.Publish.objects.filter(book__pk=1).values('name')
# print(res)
# 2.查询主键为4的书籍对应的作者姓名
# res = models.Author.objects.filter(book__pk=4).values('name','book__title')
# print(res)
# 3.查询jason的电话号码
# res = models.AuthorDetail.objects.filter(author__name='jason').values('phone')
# print(res)
# 4.查询北方出版社出版过的书籍名称和价格
# res = models.Book.objects.filter(publish__name='北方出版社').values('title','price')
# print(res)
# 5.查询jason写过的书籍名称
# res = models.Book.objects.filter(authors__name='jason').values('title')
# print(res)
# 6.查询电话号码是110的作者姓名
res = models.Author.objects.filter(author_detail__phone=110).values('name')
print(res)
补充
# 查询主键为4的书籍对应的作者的电话号码
# res = models.Book.objects.filter(pk=4).values('authors__author_detail__phone')
# print(res)
# res = models.AuthorDetail.objects.filter(author__book__pk=4).values('phone')
# print(res)
res = models.Author.objects.filter(book__pk=4).values('author_detail__phone')
print(res)
"""
ORM执行sql语句 双下划线 外键字段创建 ORM跨表查询的更多相关文章
- Django学习——Django测试环境搭建、单表查询关键字、神奇的双下划线查询(范围查询)、图书管理系统表设计、外键字段操作、跨表查询理论、基于对象的跨表查询、基于双下划线的跨表查询
Django测试环境搭建 ps: 1.pycharm连接数据库都需要提前下载对应的驱动 2.自带的sqlite3对日期格式数据不敏感 如果后续业务需要使用日期辅助筛选数据那么不推荐使用sqlite3 ...
- MYSQL - 外键、约束、多表查询、子查询、视图、事务
MYSQL - 外键.约束.多表查询.子查询.视图.事务 关系 创建成绩表scores,结构如下 id 学生 科目 成绩 思考:学生列应该存什么信息呢? 答:学生列的数据不是在这里新建的,而应该从学生 ...
- (20)模型层 -ORM之msql 基于双下划线的跨表查询(一对一,一对多,多对多)
基于对象的跨表查询是子查询 基于双下划线的查询是连表查询 PS:基于双下划线的跨表查询 正向按字段,反向按表名小写 一对一 需求:查询lqz这个人的地址# 正向查询ret = models.Autho ...
- 2017年10月22日 基础SQL语句&数据库创建主外键关系
1.SQL语句的注释 双减号:-- 或者/**/2.创建数据库create database 数据库名称(不允许以数字开头,不允许以符号开头,不要起汉语名字) 3.如何选中这个数据库use 数据库名 ...
- SQL语句删除和添加外键、主键的方法
--删除外键 语法:alter table 表名 drop constraint 外键约束名 如: alter table Stu_PkFk_Sc drop constraint FK_s alter ...
- 【转】SQL语句删除和添加外键、主键
--删除外键 语法:alter table 表名 drop constraint 外键约束名 如: alter table Stu_PkFk_Sc drop constraint FK_s alter ...
- MySQL数据库(3)- 完整性约束、外键的变种、单表查询
一.完整性约束 在创建表时候,约束条件和数据类型的宽度都是可选参数. 作用:用于保证数据的完整性和一致性. 1.not null(不可空)与default 示例一:插入一个空值,如下: mysql&g ...
- Mysql如何添加外键,如何实现连表查询
创建表student和表score,表student设置主键,表score设置表student中属性相同的为外键: 创建student表 create table student ( id int p ...
- 经典SQL语句大全_主外键_约束
一.基础(建表.建约束.关系) 约束(Constraint)是Microsoft SQL Server 提供的自动保持数据库完整性的一种方法,定义了可输入表或表的单个列中的数据的限制条件(有关数据完整 ...
- django ORM模型表的一对多、多对多关系、万能双下划线查询
一.外键使用 在 MySQL 中,如果使用InnoDB引擎,则支持外键约束.(另一种常用的MyIsam引擎不支持外键) 定义外键的语法为fieldname=models.ForeignKey(to_c ...
随机推荐
- 类和实例,super()函数
class Foo: def __init__(self, name): self.name = name def ord_func(self): """定义实例方法,至 ...
- Java SpringBoot 项目构建 Docker 镜像调优实践
PS:已经在生产实践中验证,解决在生产环境下,网速带宽小,每次推拉镜像影响线上服务问题,按本文方式构建镜像,除了第一次拉取.推送.构建镜像慢,第二.三-次都是几百K大小传输,速度非常快,构建.打包.推 ...
- Tubian系统无法打开Android子系统的解决方法
打开Konsole,Konsole在程序菜单(左下角Logo)-系统中 输入: sudo nano /var/lib/waydroid/waydroid.cfg 回车 按方向键,把光标移动到[prop ...
- windows C++ call ADB command
提供两种方式: 1.Windows API 2.Windows _popen // ADBHelper.cpp : This file contains the 'main' function. Pr ...
- 华为交换机STP常用命令
STP配置和选路规则 stp enable 在交换机上启用STP stp mode stp dis stp 查看stp配置 dis stp brief 查看接口摘要信息 stp priority 40 ...
- LOJ2325「清华集训 2017」小Y和恐怖的奴隶主
题目链接 首先dp很显然,\(f(i,s)\)表示到了第i轮,各种血量人数的情况为s今后的期望攻击boss次数.那么有\(f(i,s)=\frac{1}{num+1}*\sum_{s->s'}( ...
- 靶机: medium_socnet
靶机: medium_socnet 准备工作 需要你确定的事情: 确定 kali 已经安装,并且能正常使用[本文不涉及 kali 安装配置] VirtualBox 以前能正常导入虚拟文件 ova 能正 ...
- ML-梯度下降法的详细推导与代码实现
计算 对于线性回归,梯度下降法的目标就是找到一个足够好的向量\(\theta\),使代价函数\(J(\theta) = \sum_{i=1}^{m}(\hat{y}-y_{i})^{2}\)取得最小值 ...
- 线上Electron应用具备哪些特征?
新用户购买<Electron + Vue 3 桌面应用开发>,加小册专属微信群,参与群抽奖,送<深入浅出Electron>.<Electron实战>作者签名版. 1 ...
- jvm之自动内存管理
一.运行时数据区 程序计数器(线程私有) 1.程序计数器占用jvm内存较小,主要用来记录当前线程所执行的字节码的位置,因为jvm的多线程都是通过cpu对线程进行来回切换,所以在某个确定的时间cpu只会 ...