【爬虫GUI】YouTube评论采集软件,突破反爬,可无限爬取!
一、背景介绍
你好,我是@马哥python说 ,一名10年程序猿。
最近我用python开发了一个GUI桌面软件,作用是爬取YouTube指定视频的评论,6个关键字段,含:
评论id、评论内容、评论时间、评论作者昵称、评论作者频道、点赞数
1.1 软件说明
几点重要说明:
- 运行之前,先打开魔法
- Windows用户可直接双击打开使用,无需Python运行环境
- 可爬取指定数量评论,或者全部评论(不存在反爬问题)
- 排序方式支持:按日期排序/按热门排序
- 可爬取6个字段,含:评论id、评论内容、评论时间、评论作者昵称、评论作者频道、点赞数
- 其中,评论时间含绝对时间(年月日时分秒的格式)
1.2 效果演示
演示视频:
【Python爬虫GUI】我开发了一个采集YouTube评论的软件!
运行截图1:
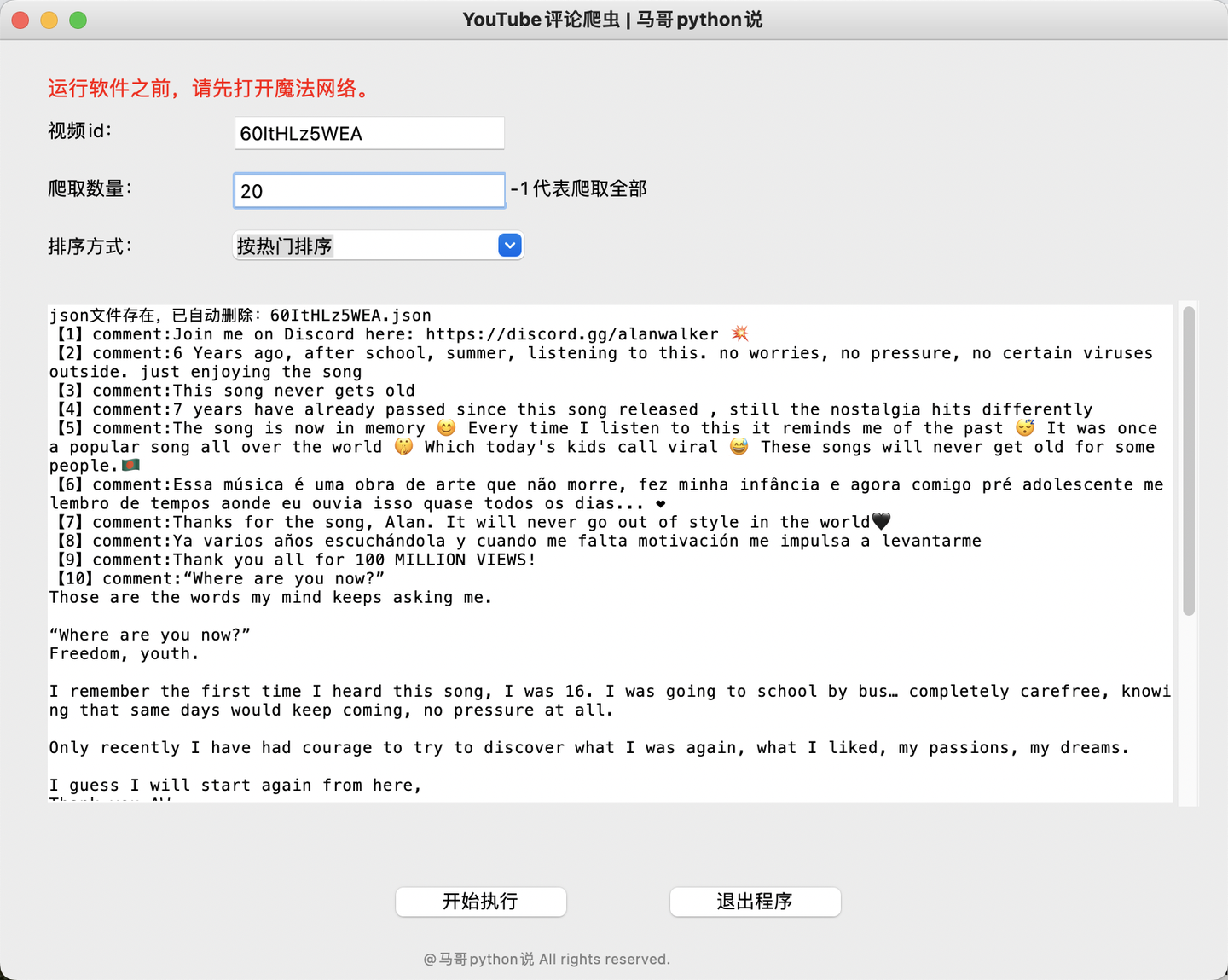
运行截图2:
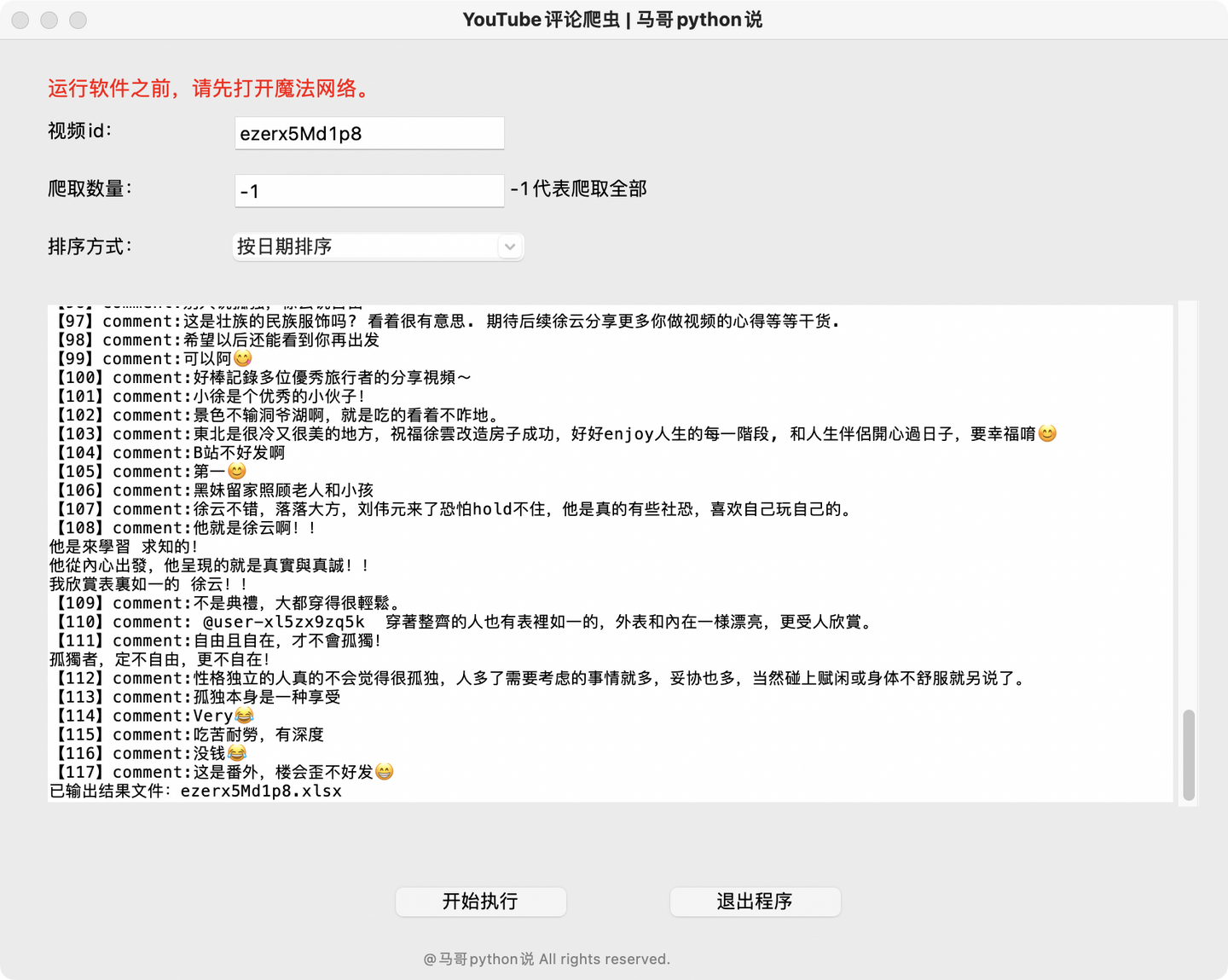
二、科普知识
2.1 关于视频id
油管视频id号,比如,https://www.youtube.com/watch?v=9lc6D6nPd38 这个视频链接的视频id就是"9lc6D6nPd38"。YouTube的每个视频都是如此。
2.2 关于评论时间
YouTube网页上是看不到绝对时间(年月日时分秒格式)的,只能看到相对时间(几个月前、几天前之类),此软件支持爬取绝对时间。
三、爬虫代码
3.1 界面模块
软件界面采用tkinter开发。
主窗口部分:
# 创建主窗口
root = tk.Tk()
root.title('YouTube评论爬虫 | 马哥python说')
# 设置窗口大小
root.minsize(width=850, height=650)
show_list_Frame = tk.Frame(width=800, height=350) # 创建<消息列表分区>
show_list_Frame.pack_propagate(0)
show_list_Frame.place(x=30, y=180, anchor='nw') # 摆放位置
# 滚动条
scroll = tk.Scrollbar(show_list_Frame)
# 放到Y轴竖直方向
scroll.pack(side=tk.RIGHT, fill=tk.Y)
按钮控件部分:
# 界面设计
# 视频id
tk.Label(root, text='视频id:').place(x=30, y=50)
video_id = tk.StringVar()
video_id.set('')
entry = tk.Entry(root, bg='#ffffff', width=20, textvariable=video_id)
entry.place(x=160, y=50, anchor='nw') # 摆放位置
3.2 爬虫模块
通过请求YouTube评论的ajax接口实现,详见文末完整代码。
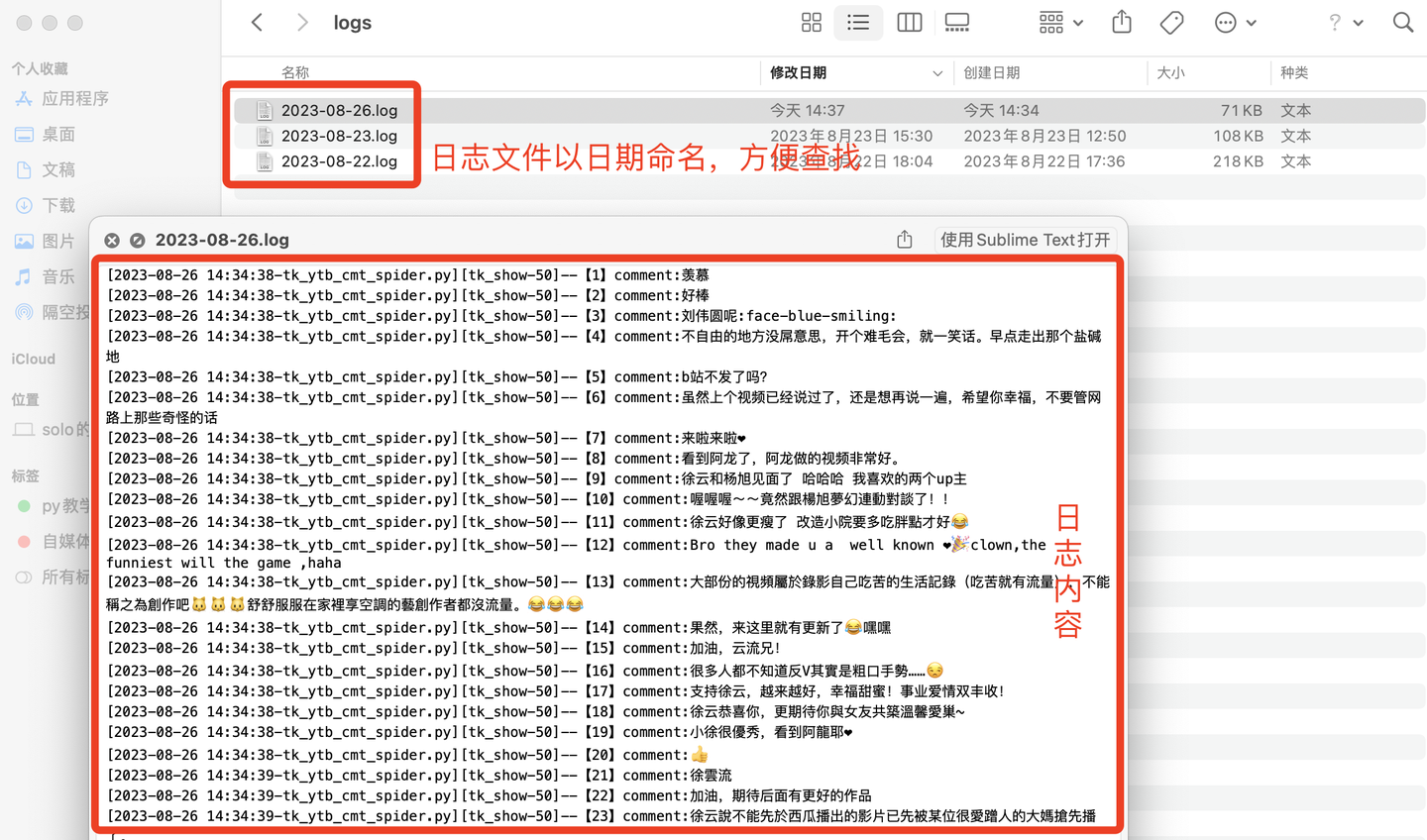
3.3 日志模块
好的日志功能,方便软件运行出问题后快速定位原因,修复bug。
核心代码:
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')
日志截图:
四、获取源码及软件
爱学习的小伙伴,完整python源码及可执行软件,我已打包好,并上传至我的微信公众号"老男孩的平凡之路",后台回复"爬油管评论软件"即可获取。
获取链接:【爬虫GUI】YouTube评论采集软件,突破反爬,可无限爬取!
我是@马哥python说,一名10年程序猿,持续分享python干货中!
【爬虫GUI】YouTube评论采集软件,突破反爬,可无限爬取!的更多相关文章
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- 第7章 Scrapy突破反爬虫的限制
7-1 爬虫和反爬的对抗过程以及策略 Ⅰ.爬虫和反爬虫基本概念 爬虫:自动获取网站数据的程序,关键是批量的获取. 反爬虫:使用技术手段防止爬虫程序的方法. 误伤:反爬虫技术将普通用户识别为爬虫,如果误 ...
- 网络采集软件核心技术剖析系列(5)---将任意博主的全部博文下载到内存中并通过Webbrower显示(将之前的内容综合到一起)
一 本系列随笔概览及产生的背景 自己开发的豆约翰博客备份专家软件工具问世3年多以来,深受广大博客写作和阅读爱好者的喜爱.同时也不乏一些技术爱好者咨询我,这个软件里面各种实用的功能是如何实现的. 该软件 ...
- 采用VSPD、ModbusTool模拟串口、MODBUS TCP设备进行Python采集软件开发
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 不少仪器/设备都提供了数据采集的接口,其中不少是串口或网络的MODBUS/TCP协议. 串口是比较简单 ...
- 网络采集软件核心技术剖析系列(7)---如何使用C#语言搭建程序框架(经典Winform界面,顶部菜单栏,工具栏,左边树形列表,右边多Tab界面)
一 本系列随笔概览及产生的背景 自己开发的豆约翰博客备份专家软件工具问世3年多以来,深受广大博客写作和阅读爱好者的喜爱.同时也不乏一些技术爱好者咨询我,这个软件里面各种实用的功能是如何实现的. 该软件 ...
- 网络采集软件核心技术剖析系列(6)---将任意博主的全部博文下载到SQLite数据库中并通过Webbrower显示(将之前的内容综合到一起)
一 本系列随笔目录及本节代码下载 自己开发的豆约翰博客备份专家软件工具问世3年多以来,深受广大博客写作和阅读爱好者的喜爱.同时也不乏一些技术爱好者咨询我,这个软件里面各种实用的功能是如何实现的. 该软 ...
- 网络采集软件核心技术剖析系列(4)---使用C#语言如何将html网页转换成pdf(html2pdf)
一 本系列随笔概览及产生的背景 本系列开篇受到大家的热烈欢迎,这对博主是莫大的鼓励,此为本系列第四篇,希望大家继续支持,为我继续写作提供动力. 自己开发的豆约翰博客备份专家软件工具问世3年多以来,深受 ...
- 网络采集软件核心技术剖析系列(3)---如何使用C#语言下载博文中的全部图片到本地并可以离线浏览
一 本系列随笔概览及产生的背景 本系列开篇受到大家的热烈欢迎,这对博主是莫大的鼓励,此为本系列第三篇,希望大家继续支持,为我继续写作提供动力. 自己开发的豆约翰博客备份专家软件工具问世3年多以来,深受 ...
- 网络采集软件核心技术剖析系列(2)---如何使用C#语言获得任意站点博文的正文及标题
一 本系列随笔概览及产生的背景 本系列开篇受到大家的热烈欢迎,这对博主是莫大的鼓励,此为本系列第二篇,希望大家继续支持,为我继续写作提供动力. 自己开发的豆约翰博客备份专家软件工具问世3年多以来,深受 ...
- C#图片采集软件 自动翻页 自动分类(收集美图必备工具)(一)
网站管理员希望将别人的整站数据下载到自己的网站里或者将别人网站的一些内容保存到自己的服务器上.从内容中抽取相关的字段,发布到自己的网站系统中.有时需要将网页相关的文件也保存到本地,如图片.附件等. 图 ...
随机推荐
- BeanUtils.copyProperties() 详解
BeanUtils.copyProperties会进行类型转换:BeanUtils.copyProperties方法简单来说就是将两个字段相同的对象进行属性值的复制. 如果 两个对象之间存在名称不相同 ...
- kingbaseES 优化之操作系统瓶颈排查
针对操作系统性能瓶颈的判断和排查是数据库优化工作的一项重要技能,尤其是针对实例整体优化 操作系统的性能瓶颈排查无外乎四个方面 CPU.内存.磁盘.网络 针对这四个方面整理了一些相关心得和大家分享. 在 ...
- 如何安装和使用Docker
本文深入解析Docker,一种革命性的容器化技术,从其基本概念.架构和组件,到安装.配置和基本命令操作.文章探讨了Docker在虚拟化.一致性环境搭建及微服务架构中的关键作用,以及其在云计算领域的深远 ...
- #欧拉回路#AT4518 [AGC032C] Three Circuits
题目 给定一个 \(n\) 个点,\(m\) 条边的简单无向连通图, 问是否能将边分成三部分,使每部分都能成为环 分析 每个点的度数都得为偶数,这不由得想到了欧拉回路. 如果整张图是一个简单环那么一定 ...
- #前缀和,后缀和#洛谷 4280 [AHOI2008]逆序对
题目传送门 分析 首先填的数字单调不降,感性理解 那可以维护\([a_1\sim a_{i-1}]\)的\(cnt\)后缀和以及 \([a_{i+1}\sim a_n]\)的\(cnt\)前缀和,那可 ...
- CSP2019-S2总结
目录 前言 洛谷 5657 格雷码 代码(找规律) 洛谷 5658 括号树 分析 代码 洛谷 5659 树上的数 洛谷 5664 Emiya 家今天的饭 洛谷 5665 划分 分析 代码 洛谷 566 ...
- 新零售SaaS架构:客户管理系统架构设计(万字图文总结)
什么是客户管理系统? 客户管理系统,也称为CRM(Customer Relationship Management),主要目标是建立.发展和维护好客户关系. CRM系统围绕客户全生命周期的管理,吸引和 ...
- 直播回顾 | 点击率提升400%,Ta是怎么做到的?
Discovery第18期直播已于3月30日圆满结束,本期直播邀请天眼查做客直播间,从天眼查与华为Push用户增长服务合作历程切入,聚焦用户增长,分享提升应用活跃度和渠道ROI的经验与见解.一起来回顾 ...
- 为什么使用gs_probackup执行全量备份时,提示无法连接到数据库?
为什么使用 gs_probackup 执行全量备份时,提示无法连接到数据库? 背景介绍: 在使用 gs_probackup 执行全量备份时,提示无法连接到数据库. 报错内容: [ommdoc@host ...
- JDK 19新特性 & JDK 多版本安装切换配置
新的JDK 19包含如下7个新的特性: 转自:JDK19中比较重要的新特性-电子发烧友网 JEP 405: Record Patterns(Record模式) JEP 422: Linux/RISC- ...