OpenPower服务使用node-exporter prometheus以及grafana进行性能监控的流程
OpenPower服务器性能监控操作流程
1. 前言
最近看了很多prometheus以及influxdb进行性能监控的帖子,简单学习了下influxdb是一个单纯的时序数据库,prometheus是一个比较全面的性能监控平台. 前几天使用 influxdb还有esxi的部分配置进行了vcenter的性能监控,但是公司这边凭条技术部是prometheus为主进行性能监控的, 所以今天趁着早上没有人, 我就进行了一下OpenPower机器上面的性能监控的设置, 发现还是比较简单的, 为了备忘, 简单记录一下搭建流程.
2. 搭建思路
- node-exporter 使用二进制本地运行
下载相关二进制,二进制的方式避免不同平台拉取镜像比较麻烦
最新的下载地址为:
https://github.com/prometheus/node_exporter/releases/tag/v1.2.2
注意可以选择想对应的平台进行下载 我这边下载的是 ppc64le 的linux的tar包.
下载后 将文件解压缩并且放到 /usr/bin 目录下备用
两种方式可以设置开机启动, 一种是crontab 方式 一种是systemd的方式. 我这边为了简单起见使用systemd
创建一个文件为:
vim /etc/systemd/system/node-exporter.service
[Unit]
Description=Prometheus Node Exporter
After=network.target
[Service]
ExecStart=/usr/bin/node_exporter
User=root
[Install]
WantedBy=multi-user.target
然后 systemctl enable node-exporter && systemctl restart node-exporter
即可
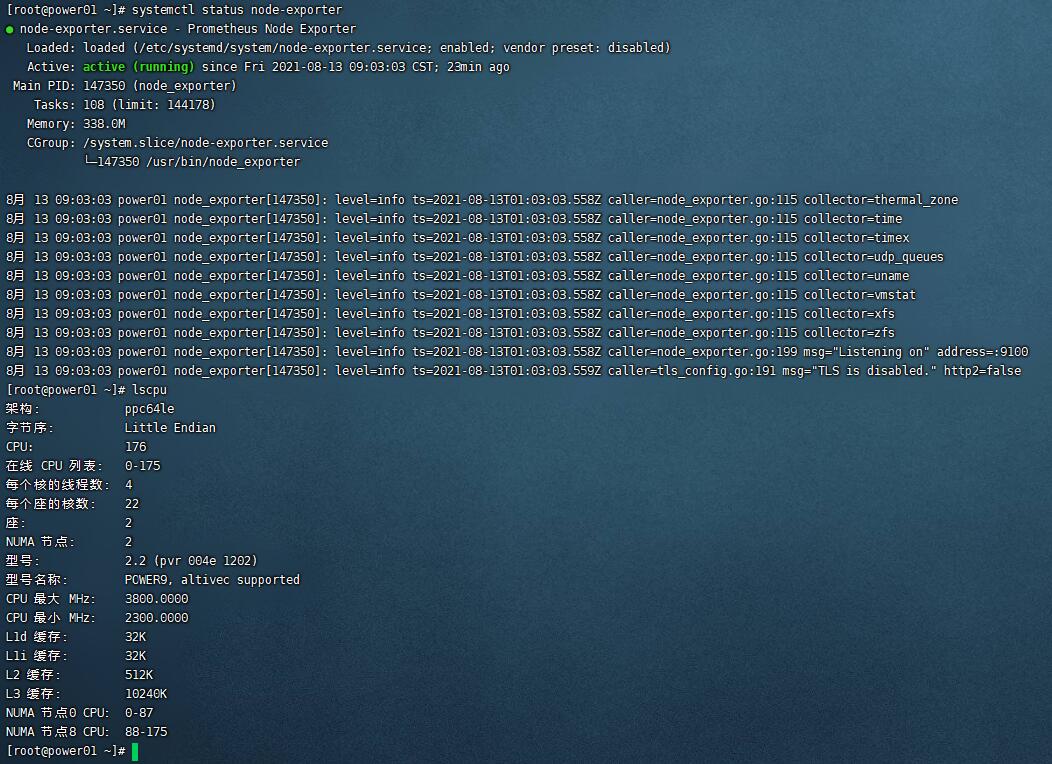
- prometheus和grafana 使用docker方式运行.
- 需要注意的是这个地方尽量拉取最新的镜像, 避免出现很多chart 组件展示不出来的情况.
prometheus 的搭建
1. 拉取镜像:
sudo docker pull prom/prometheus
sudo docker pull grafana/grafana
# 我2021.8 拉取到的grafana的镜像版本是 8.1 左右, 已经比较新了.
2. 创建prometheus的配置文件目录
mkdir /prometheus && cd /prometheus
vim prometheus.yml
# 添加内容为
# Prometheus全局配置项
global:
scrape_interval: 15s # 设定抓取数据的周期,默认为1min
evaluation_interval: 15s # 设定更新rules文件的周期,默认为1min
scrape_timeout: 15s # 设定抓取数据的超时时间,默认为10s
external_labels: # 额外的属性,会添加到拉取得数据并存到数据库中
monitor: 'codelab_monitor'
# Alertmanager配置
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"] # 设定alertmanager和prometheus交互的接口,即alertmanager监听的ip地址和端口
# rule配置,首次读取默认加载,之后根据evaluation_interval设定的周期加载
rule_files:
- "alertmanager_rules.yml"
- "prometheus_rules.yml"
# scape配置
scrape_configs:
- job_name: 'OpenPowerAPP244' # job_name默认写入timeseries的labels中,可以用于查询使用
scrape_interval: 15s # 抓取周期,默认采用global配置
static_configs: # 静态配置
- targets: ['10.24.xx.xx:9100'] # prometheus所要抓取数据的地址,即instance实例项
- job_name: 'OpenPowerDB243' # job_name默认写入timeseries的labels中,可以用于查使用
scrape_interval: 15s # 抓取周期,默认采用global配置
static_configs: # 静态配置
- targets: ['10.24.xx.xx:9100'] # prometheus所要抓取数据的地址,即instance实例项
- job_name: 'example-random' #个人测试用接口
static_configs:
- targets: ['localhost:8080']
# 有文档还会处理两个文件主要如下:
vim alertmanager_rules.yml
groups:
- name: test-rules
rules:
- alert: InstanceDown # 告警名称
expr: up == 0 # 告警的判定条件,参考Prometheus高级查询来设定
for: 2m # 满足告警条件持续时间多久后,才会发送告警
labels: #标签项
team: node
annotations: # 解析项,详细解释告警信息
summary: "{{$labels.instance}}: has been down"
description: "{{$labels.instance}}: job {{$labels.job}} has been down "
value: {{$value}}
以及
vim prometheus_rules.yml
groups:
- name: example #报警规则的名字
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown #检测job的状态,持续1分钟metrices不能访问会发给altermanager进行报警
expr: up == 0
for: 1m #持续时间
labels:
serverity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
- alert: "it's has problem" #报警的名字
expr: "test_tomcat{exported_instance="uat",exported_job="uat-app-status",host="test",instance="uat",job="uat-apps-status"} - test_tomcat{exported_instance="uat",exported_job="uat-app-status",host="test",instance="uat",job="uat-apps-status"} offset 1w > 5" # 这个意思是监控该表达式查询出来的值与一周前的值进行比较,大于5且持续10m钟就发送给altermanager进行报警
for: 1m #持续时间
labels:
serverity: warning
annotations:
summary: "{{ $labels.type }}趋势增高"
description: "机器:{{ $labels.host }} tomcat_id:{{ $labels.id }} 类型:{{ $labels.type }} 与一周前的差值大于5,当前的差值为:{{ $value }}" #自定义的报警内容
运行容器:
sudo docker run -d -p 9091:9090 --name prometheus -v /prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
# 注意 我机器上面 9100 被其他进程占用了 所以我换了一个端口.
然后使用域名 http://yourip:9091/metrics
能够看到如下内容就说明可以监控到数据了.
# 注意 我的node_exporter已经创建好的情况下才有.
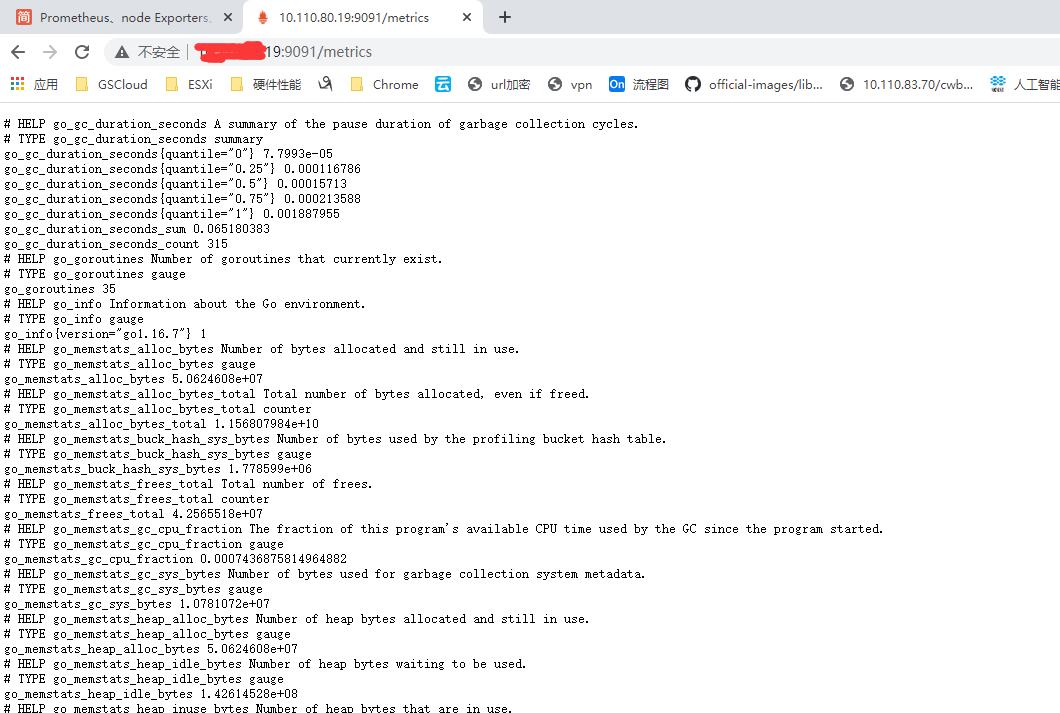
- grafana 也是使用容器化搭建方式也比较简单
docker run -d -p 3000:3000 --name=grafana -v /opt/grafana-storage:/var/lib/grafana grafana/grafana
# 注意一定要持久化, 不然机器重启或者是容器重启就没有了. 注意启动之后需要设置密码 不要用默认密码 admin/admin
容易出现安全问题.
3. grafana 展示结果
- 3.1 先去官网下载响应的json文件.
- 公司连grafana的官网都不让上.还得用流量赖上,电话费报销还这么低. diss一下.
- 选择如下这一个就可以
下载路径为:
https://grafana.com/grafana/dashboards?dataSource=influxdb&direction=desc&orderBy=downloads&search=vmware&collector=Telegraf
下载好json
打开grafana
3.2 添加数据源
方式比较简单 见图即可3.2.1 打开数据源管理
3.2.2 添加数据源
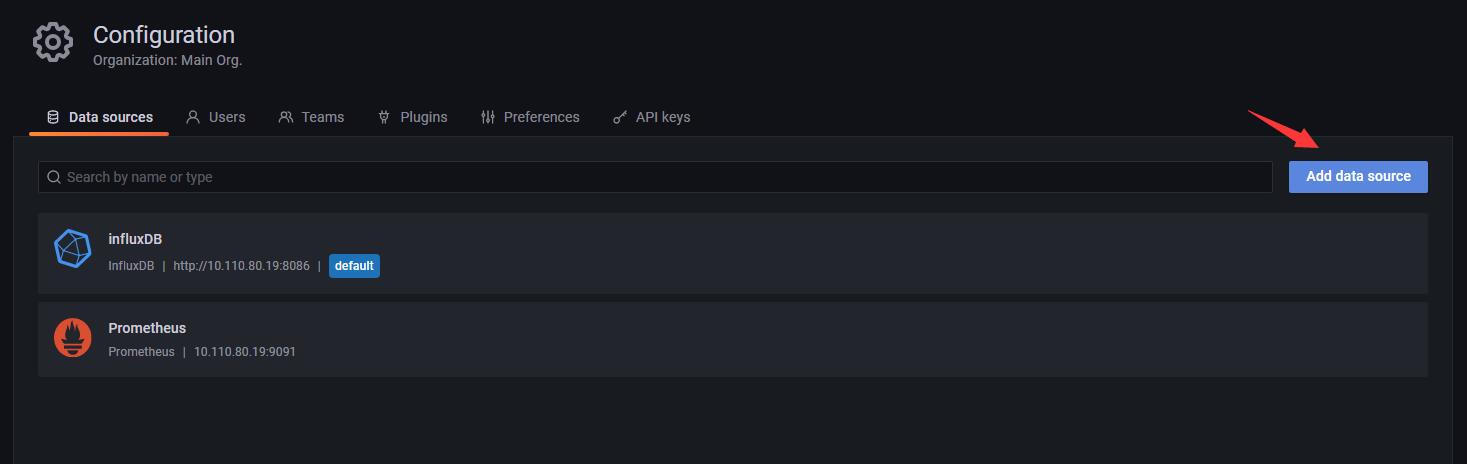
3.2.3 选择prometheus
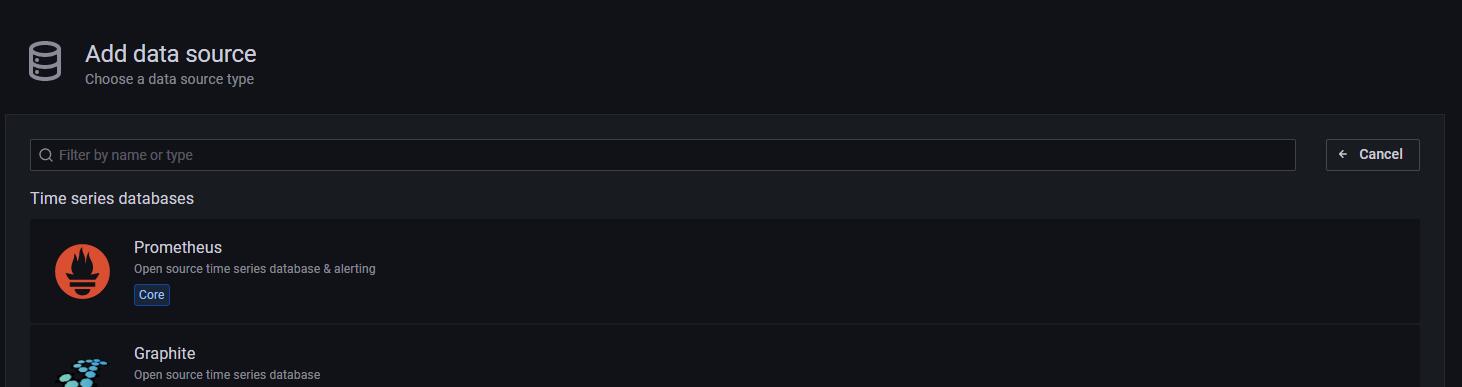
3.2.4 输入自己的服务器的信息, 注意端口号需要跟自己运行的端口号匹配起来
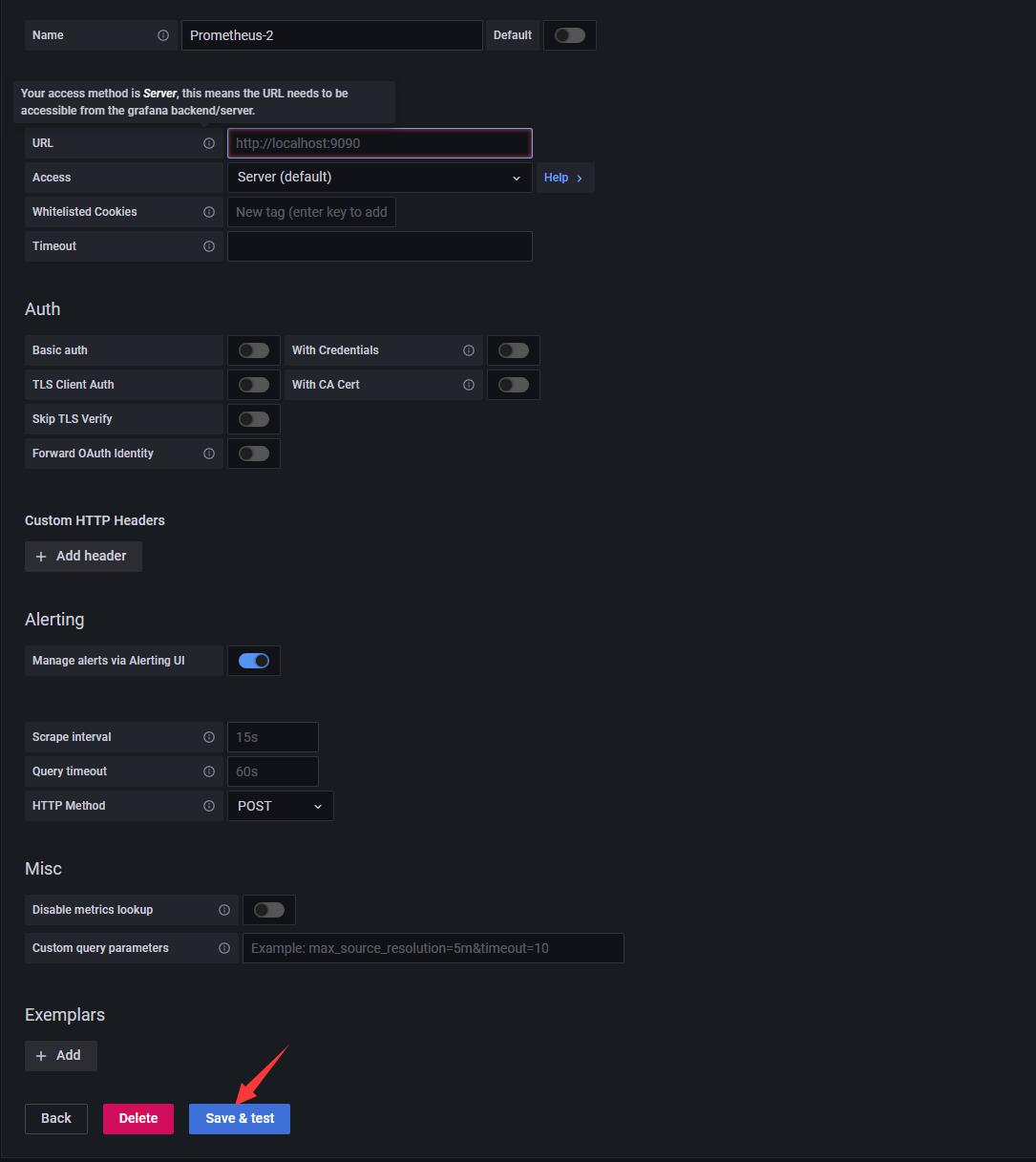
3.2.5 save and test 提示成功可以运行即可.
3.3.1 导入josn文件, 非常简单,如图示即可
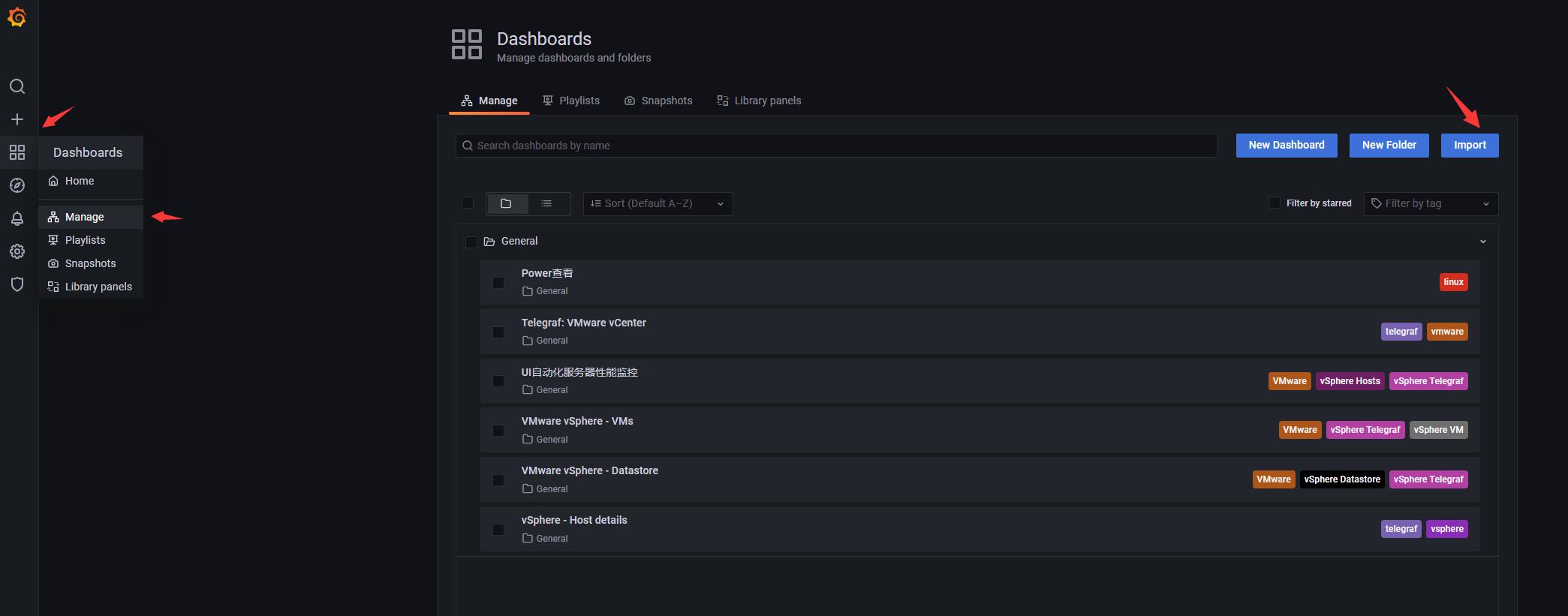
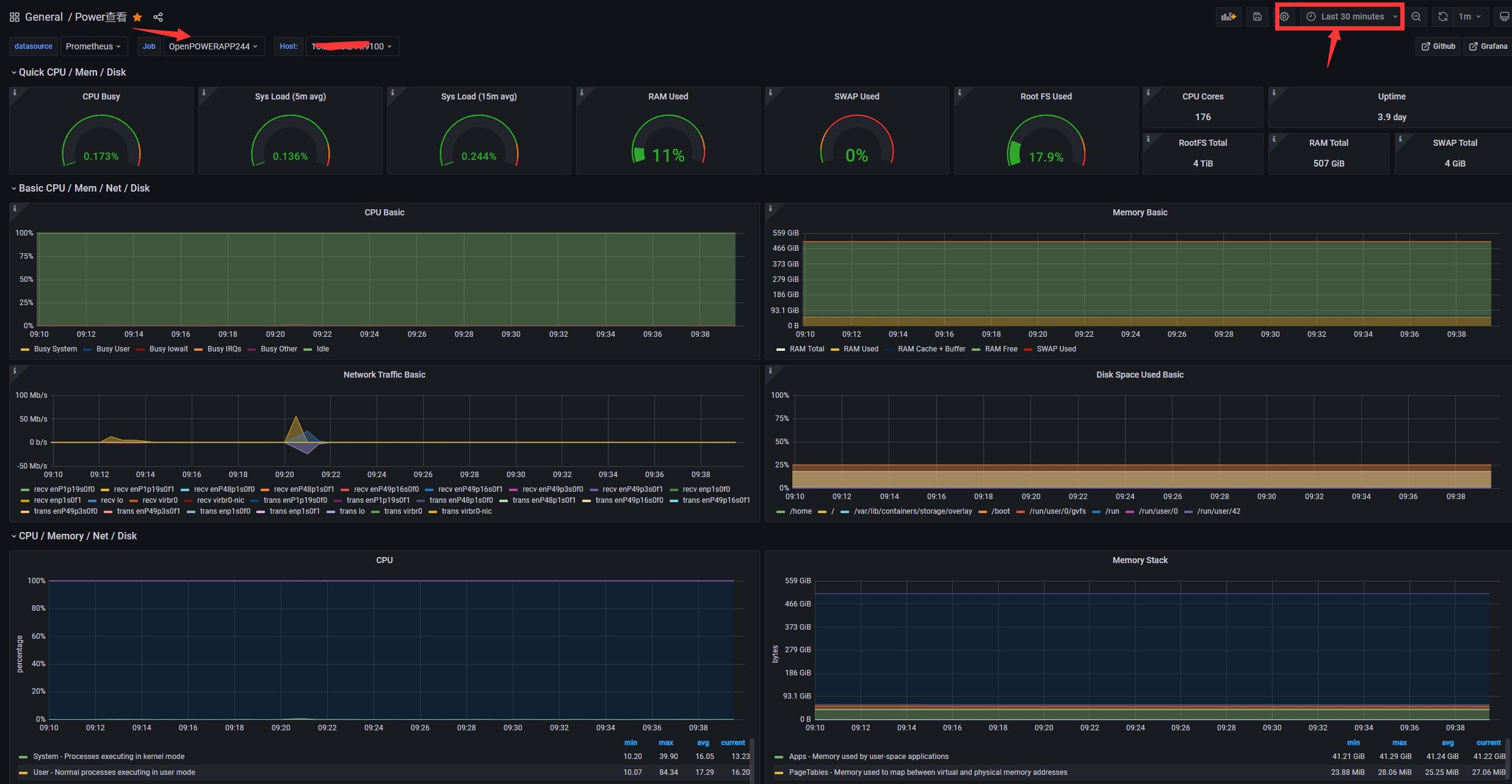
3.4 查看展示结果
注意 需要等一段时间来收集数据
注意 可以缩短时间来进行查看内容
OpenPower服务使用node-exporter prometheus以及grafana进行性能监控的流程的更多相关文章
- incubator-dolphinscheduler 如何在不写任何新代码的情况下,能快速接入到prometheus和grafana中进行监控
一.prometheus和grafana 简介 prometheus是由谷歌研发的一款开源的监控软件,目前已经贡献给了apache 基金会托管. 监控通常分为白盒监控和黑盒监控之分. 白盒监控:通过监 ...
- Docker系列——InfluxDB+Grafana+Jmeter性能监控平台搭建(一)
在做性能测试的时候,重点关注点是各项性能指标,用Jmeter工具,查看指标数据,就是借助于聚合报告,但查看时也并不方便.那如何能更直观的查看各项数据呢?可以通过InfluxDB+Grafana+Jme ...
- Docker系列——InfluxDB+Grafana+Jmeter性能监控平台搭建(三)
在之前系列博文中,已经介绍完了数据采集和数据存储,那数据如何展示呢?所以今天就专门来讲下数据如何展示的问题. 以前博文参考: Docker系列--InfluxDB+Grafana+Jmeter性能监控 ...
- Node.js精进(9)——性能监控(上)
市面上成熟的 Node.js 性能监控系统,监控的指标有很多. 以开源的 Easy-Monitor 为例,在系统监控一栏中,指标包括内存.CPU.GC.进程.磁盘等. 这些系统能全方位的监控着应用的一 ...
- Docker系列——InfluxDB+Grafana+Jmeter性能监控平台搭建(二)
在上一篇博文中,主要是讲了InfluxDB的配置,博文链接:https://www.cnblogs.com/hong-fithing/p/14453695.html,今天来分享下Jmeter的配置. ...
- Node.js精进(10)——性能监控(下)
本节会重点分析内存和进程奔溃,并且会给出相应的监控方法. 本系列所有的示例源码都已上传至Github,点击此处获取. 一.内存 虽然在 Node.js 中并不需要手动的对内存进行分配和销毁,但是在开发 ...
- 基于Prometheus和Grafana打造业务监控看板
前言 业务监控对许许多多的场景都是十分有意义,业务监控看板可以让我们比较直观的看到当前业务的实时情况,然后运营人员可以根据这些情况及时对业务进行调整操作,避免业务出现大问题. 老黄曾经遇到过一次比较尴 ...
- collectd+influxDB+Grafana搭建性能监控平台
网上查看了很多关于环境搭建的文章,都比较久远了很多安装包源都不可用了,今天收集了很多资料组合尝试使用新版本来搭建,故在此记录. 采集数据(collectd)-> 存储数据(influxdb) - ...
- 【开源监控】Prometheus+Node Exporter+Grafana监控linux服务器
Prometheus Prometheus介绍 Prometheus新一代开源监控解决方案.github地址 Prometheus主要功能 多维 数据模型(时序由 metric 名字和 k/v 的 l ...
- Prometheus 集成 Node Exporter
文章首发于公众号<程序员果果> 地址:https://mp.weixin.qq.com/s/40ULB9UWbXVA21MxqnjBxw 简介 Prometheus 官方和一些第三方,已经 ...
随机推荐
- 实践案例丨Pt-osc工具连接rds for mysql 数据库失败
[现象] 主机可以telent 通rds 端口,并且使用mysql-client 连接正常: 如下图所示:使用pt-osc工具连接时,一直没有响应,一直卡在哪里 等了4-5分钟左右后,会有响应,如下图 ...
- Asp.net MVC 跨域设置
.Net Core 跨域 <system.webServer> <httpProtocol> <customHeaders> <add name=" ...
- #2612:Find a way(BFS搜索+多终点)
第一次解决双向BFS问题,拆分两个出发点分BFS搜索 #include<cstdio> #include<cstring> #include<queue> usin ...
- 在wsl2 kali发行版中安装docker
前言 因为不想开虚拟机,而又需要多个linux发行版来做测试,也不想使用docker-desktop来曲线救国,所以想直接安装个docker随时使用,这一路也是踩了不少坑.直接复制进终端进行安装 su ...
- vue+spingboot 实现服务器端文件下载功能
vue3 和springboot配合如何实现服务器端文件的下载. 先看springboot的后台代码: @PostMapping("/download") @ResponseBod ...
- 黑马vue学习笔记
1.v-model原理 2.数组相关API 3.prop命名规则: 4.非父子组件传值-事件中心
- Vue中如何使用sass实现换肤(更换主题)功能
Vue中如何使用sass实现换肤(更换主题)功能 https://blog.csdn.net/m0_37792354/article/details/82012278
- C++跨DLL内存所有权问题探幽(一)DLL提供的全局单例模式
最近在开发的时候,特别是遇到关于跨DLL申请对象.指针.内存等问题的时候遇到了这么一个问题. 问题 跨DLL能不能调用到DLL中提供的单例? 问题比较简单,就是我现在有一个进程A,有DLL B DLL ...
- freeswitch 新通话启动过程梳理
概述 freeswitch是一款开源的VOIP软交换平台,功能强大. 在使用fs进行呼叫业务的过程中,我们最常见到的日志就是呼叫通道的启动信息,日志如下 2022-03-03 14:14:30.028 ...
- 杂谈 | 在 SEU 开会可以去哪里
空间预约: 健雄书院预约系统 只对吴院人开放,其他人可通过前台志愿者预约. 秉文书院对全校开放(貌似?),需要 提前一天 预约. 借教室需要 提前两天 申请. 图书馆研讨间可以随时约,只是有点难抢. ...