[转帖]010 Linux 文本统计与去重 (wc 和 uniq)
https://my.oschina.net/u/3113381/blog/5427461
wc 命令一般是作为组合命令的一员与其他命令一同起到统计的作用。而一般情况下使用 wc -l 命令较多。 uniq 可检查文本文件中重复出现的行,一般与 sort 命令结合使用。一起组合搭配使用完成统计、排序、去重。
1 wc 常用组合命令
- ls | wc -l # 统计当前文件夹下,文件数量;
- ls *.txt | wc -l # 统计当前文件夹下、第一层目录下所有的 txt 文件数量;
- find . -maxdepth 1 -name '*.txt' | wc -l # 统计当前文件夹、第一层目录下所有的 txt 文件数量;
2 wc 基本参数和格式
命令格式: wc [-clmw] [file ...]
- -c # 统计字节数
- -l # 统计行数
- -w # 统计单词数
- -m # 统计字符数
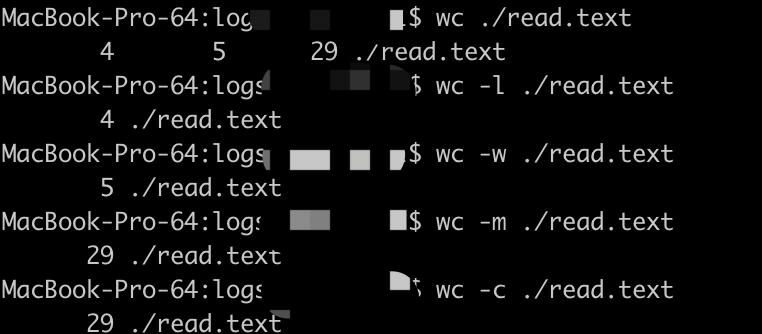
3 wc 命令示例
c、l、w、m 用例
read.text 内容如下:
!
hello china!
hello!
china!
配合 grep 统计命中的目标行数用例
# grep 正则匹配统计命中的目标行数,wc 命令在后面
grep -E "(14:41(.)+internal-internal spend)" 002.info.log | wc -l
4 uniq 的常用参数以及配合 sor t 应用示例
uniq 常用参数
uniq 可检查文本文件中重复出现的行,一般与 sort 命令结合使用。
- -c 或 --count 在每列旁边显示该行重复出现的次数;
- -d 或 --repeated 仅显示重复出现的行;
- -u 或 --unique 仅显示出一次的行;
info.log 内容如下:
111,222,333
111,222,333
333,444,555
xxx,yyy,zzz
cat info.log |sort -r
xxx,yyy,zzz
333,444,555
111,222,333
111,222,333
cat info.log |sort|uniq
111,222,333
333,444,555
xxx,yyy,zzz
cat info.log |sort -r|uniq -u
xxx,yyy,zzz
333,444,555
cat info.log |sort -r|uniq -d
111,222,333
cat info.log |sort -r|uniq -c
1 xxx,yyy,zzz
1 333,444,555
2 111,222,333
5 案例一(文本统计)
有一个 b. txt 文本 (内容如下),要求将所有域名截取出来,并统计重复域名出现的次数。
http://www.baidu.com/index.html
https://www.atguigu.com/index.html
http://www.sina.com.cn/1024.html
https://www.atguigu.com/2048.html
http://www.sina.com.cn/4096.html
https://www.atguigu.com/8192.html
命令和结果
cat b.txt |cut -d "/" -f3 |sort| uniq -c|sort -nr
3 www.atguigu.com
2 www.sina.com.cn
1 www. baidu.com
# cut -d "/" -f3 用"/"作为分隔符,截取第个3字段
# sort 第一次排序
# uniq -c 显示该行重复次数
# sort -nr 按照数值从大到小排序
6 案例二( ip 连接数统计并排序)
统计当前服务器正在连接的 ip 地址,并按连接次数排序;
netstat -an I grep ESTABLISHED | awk '{print $5}' | cut -d ":" -f1 | sort -n | uniq -c | sort -nr
7 小结
wc 用来统计指定文件中的字节数、行数、单词数、字符数; uniq 可检查文本文件中重复出现的行列。 可对标准输入,配合 grep、sort、find 等命令完成统计、排序、去重。
[转帖]010 Linux 文本统计与去重 (wc 和 uniq)的更多相关文章
- 010 Linux 文本统计与去重 (wc 和 uniq)
wc 命令一般是作为组合命令的一员与其他命令一同起到统计的作用.而一般情况下使用wc -l 命令较多. uniq 可检查文本文件中重复出现的行,一般与 sort 命令结合使用.一起组合搭配使用完成统计 ...
- linux上文件内容去重的问题uniq/awk
1.uniq:只会对相邻的行进行判断是否重复,不能全文本进行搜索是否重复,所以往往跟sort结合使用. 例子1: [root@aaa01 ~]# cat a.txt 12 34 56 12 [root ...
- linux上文件内容去重的问题uniq/awk 正则表达过滤操作
.uniq:只会对相邻的行进行判断是否重复,不能全文本进行搜索是否重复,所以往往跟sort结合使用. 例子1: [root@aaa01 ~]# cat a.txt 12 34 56 12 [root@ ...
- linux日志分割、去重、统计
一.实例 单条日志模板: 2018-11-08 02:17:22 [Iceberg]process params:IcebergOfferServiceImpl.Params(pk=BF06NA2YE ...
- Linux 文本去重 之 命令sort 与 uniq
sort [-fbMnrtuk] [file or stdin] 选项与参数: -f :忽略大小写的差异,例如 A 与 a 视为编码相同: -b :忽略最前面的空格符部分: -M :以月份的名字来排序 ...
- 【转帖】linux sort,uniq,cut,wc,tr,xargs命令详解
linux sort,uniq,cut,wc,tr,xargs命令详解 http://embeddedlinux.org.cn/emb-linux/entry-level/201607/21-5550 ...
- Linux下统计出现次数最多的指定字段值
假设桌面上有一个叫“data.txt”的文本,内容如下: {id='xxx' info='xxx' kk='xxx' target='111111' dd='xxx'}{id='xxx' info=' ...
- linux文本处理命令
linux文本处理命令 1.wc命令 基本介绍 文件的行统计.字符统计.字节统计 基本语法 wc [OPTION]... [FILE]... wc [OPTION]... --files0-f ...
- Linux文本处理三剑客之grep及正则表达式详解
Linux文本处理三剑客之grep及正则表达式详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Linux文本处理三剑客概述 grep: 全称:"Global se ...
- Linux文本三剑客总结
Linux文本处理三剑客 grep 文本过滤(模式:pattern)工具 grep, egrep, fgrep(不支持正则表达式搜索) grep grep: Global search REgula ...
随机推荐
- 以小博大外小内大,Db数据库SQL优化之小数据驱动大数据
SQL优化中,有一条放之四海而皆准的既定方针,那就是:永远以小数据驱动大数据.其本质其实就是以小的数据样本作为驱动查询能够优化查询效率,在SQL中,涉及到不同表数据的连接.转移.或者合并,这些操作必须 ...
- 案例解读华为隐私计算产品TICS如何实现城市跨部门数据隐私计算
摘要:本文介绍华为可信智能计算服务TICs是如何助力城市跨部门数据实现隐私计算的. 本文分享自华为云社区<基于华为隐私计算产品TICS实现城市跨部门数据隐私计算,助力实现普惠金融>,作者: ...
- vue2升级vue3: TSX Vue 3 Composition API Refs
在vue2时代,$refs 直接操作子组件 this.$refs.gridlayout.$children[index]; 虽然不推荐这么做,但是确实非常好用.但是vue2快速迁移到vue3,之前的这 ...
- JPEG/Exif/TIFF格式解读(1):JEPG图片压缩与存储原理分析
JPEG文件简介 JPEG的全称是JointPhotographicExpertsGroup(联合图像专家小组),它是一种常用的图像存储格式, jpg/jpeg是24位的图像文件格式,也是一种高效率的 ...
- 代码混淆工具ipaguard:如何使用ipaguard保护和混淆iOS应用程序代码
转载:怎么保护苹果手机移动应用程序ios ipa文件中的代码? 目录 转载:怎么保护苹果手机移动应用程序ios ipa文件中的代码? 代码混淆步骤 1. 选择要混淆保护的ipa文件 2. 选择要混 ...
- 火山引擎DataLeap基于Apache Atlas自研异步消息处理框架
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 字节数据中台DataLeap的Data Catalog系统通过接收MQ中的近实时消息来同步部分元数据.Apache ...
- 火山引擎DataLeap如何解决SLA治理难题(一):应用场景与核心概念介绍
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 基于火山引擎分布式治理的理念,数据平台数据治理团队自研了火山引擎DataLeap SLA保障平台,目前已在字节内部 ...
- Android gradle dependency tree change(依赖树变化)监控实现,sdk version 变化一目了然
@ 目录 前言 基本原理 执行流程 diff 报告 不同分支 merge 过来的 diff 报告 同个分支产生的 merge 报告 同个分支提交的 diff 报告 具体实现原理 我们需要监控怎样的 D ...
- MMSC 扩充物料库存地点
当涉及到物料的库存地点时,系统通常会做校验,该物料是否扩充了库存地点,没有扩充则报错.为了不使这样的错误干扰到程序逻辑,通常会在涉及时,先查询MARD表,判断是否存在对应的库存地点.如果没有存在,则直 ...
- 例题 5-7 丑数(Ugly Numbers,UVa 136)
题意: 丑数是一些因子只有2,3,5的数.数列1,2,3,4,5,6,8,9,10,12,15--写出了从小到大的前11个丑数,1属于丑数.现在请你编写程序,找出第1500个丑数是什么. 思路: 如果 ...